
For this brief Javascript exercise, I played around with several pieces of text by calculating the Flesch-Kincaid reading level. For instance, the following texts are either written essays from different grade levels or comparisons of other literature based on popularity and the time period of when it was written. Overall, this short overview given out numeric results that indicated how readable the text is in a specific reading group; which ranges from at least eleven year old students to university graduates.
To start off, I have chosen my sister’s recent narrative in which she had to produce for her English class based on a given topic. I ended comparing it off with two essays I’ve written from my first year in college. Overall, I typed out all the needed data in my chosen terminal program; Git Bash, and plugged in the right command line to perform the task.
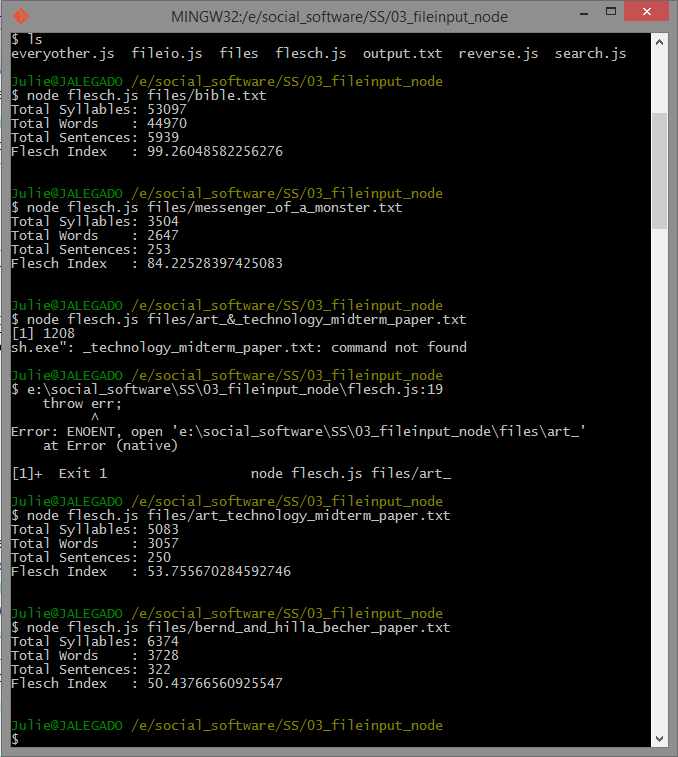
Calculating Flesch-Kincaid reading level with school papers through Git Bash, node.js and flesch.js
As a result, I first started off calculating my sister’s narrative, “Memory of a Monster” and the test calculated it to be 84 in the Flesch Index. According to the scale, 84 is an easy readability level where at least an eleven-year-old student could manage to read. A contrast to the short narrative would be my two college essays, “Bernd And Hilla Becher” and “Art Technology Midterm Paper” which fallen into the same scale of 50-53. While going in depth with the numbers, the essays are fairly difficult and a high school senior is still capable to read them. Overall, these two papers were a few increments close to be difficult to read.
Lastly, for fun, I picked two well-known literatures and compared them of what their Flesch-Kincaid reading level would be. For example, “The Great Gastby” had at least a 68 Flesch index while the first book of the “Harry Potter” series was scaled to a 75. Both novels either scaled between being having a standard or fairly easy readability level.
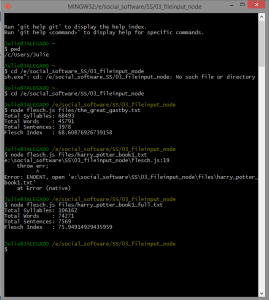
Calculating Flesch-Kincaid reading level with famous literature through Git Bash, node.js and flesch.js
Furthermore, whenit came to literature and translating this particular experience on how words can benefit from searching specific information just by developing a program that does it for you. The effort on experimenting this concept was reflected by James Pennebaker during his TED talk on “The Secrets of Pronouns.” By going back to the idea of having this formula, which calculates your reading level just from the library of vocabulary a reader or writer, might know.
2,851 Comments
Neat blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really
make my blog jump out. Please let me know where you got
your design. With thanks
Nice post. I learn something new and challenging on sites I stumbleupon every day.
It will always be exciting to read content from other
authors and use something from their web sites.
It’s truly a nice and useful piece of info. I’m satisfied that you simply
shared this helpful info with us. Please stay us informed like this.
Thanks for sharing.
Hi there it’s me, I am also visiting this web site on a regular
basis, this website is really pleasant and the users are really sharing nice thoughts.
It’s amazing to go to see this site and reading the views of all friends regarding this post, while I am also eager of getting knowledge.
It’s actually a great and useful piece of information. I’m glad that you just shared this helpful information with us.
Please keep us informed like this. Thanks for sharing.
Heya i am for the first time here. I came across this board and I in finding It really useful & it helped me out much.
I’m hoping to provide one thing again and help
others such as you aided me.
Fourth, discover possibilities of accessing relevant data regarding
various auto insurance companies. Many policies offer multi-policy , multi-vehicle, good driver, and years of license experience or superior driver discounts.
Insurance rip offs have been around ever since insurance
has been around.
I always used to study article in news papers but now as I am a user of web
thus from now I am using net for articles, thanks to web.
I was wondering if you ever considered changing the layout of your website?
Its very well written; I love what youve got to say. But maybe you could a little more in the way of content
so people could connect with it better. Youve got an awful lot of text for only having one or two pictures.
Maybe you could space it out better?
I am sure this article has touched all the internet visitors, its really really fastidious article on building up new website.
My web-site :: nike free australia
Hello world inmovigia.com
I’m not sure why but this blog is loading extremely slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
. ,
Feel free to surf to my webpage … tinyurl.com
Thank you for every other informative blog. The place else may just I get that kind
of information written in such an ideal approach? I’ve a undertaking that I am simply now
working on, and I’ve been on the look out for such information.
Hello! This is my first visit to your blog! We are a group of volunteers
and starting a new project in a community in the same niche.
Your blog provided us beneficial information to work on. You have done
a outstanding job!
I pay a visit every day some sites and websites to read articles, but this weblog presents quality
based writing.
Also visit my webpage :: free gems clash of clans
Each site presents similar standards but addresses the skills you credit need.
Wonderful beat ! I wish to apprentice whilst you amend your website, how can i subscribe for a blog web site?
The account aided me a acceptable deal. I have been a little bit familiar of this your broadcast provided shiny transparent concept
In case these third party tools are not enough,
as your phone is not able to recover data even after software recovery.
However, would you disagree if I say that power of
a smartphone cannot be analyzed unless you start downloading and using some apps on your wireless
device. One will include enterprise-grade email,
calendar, contacts and messaging apps and a browser, all of which can securely
access corporate data.
It’s very trouble-free to find out any matter on net as compared to books, as I found this article
at this website.
Does your blog have a contact page? I’m having a tough time locating it but,
I’d like to shoot you an e-mail. I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it grow over time.
Check out my blog – ครีมบำรุงผิวขาว
Visit my blog post … traffic ticket lawyer orlando fl (Jayson)
Pretty component to content. I simply stumbled upon your website and in accession capital to say that I get actually
loved account your blog posts. Anyway I’ll be subscribing for your augment and even I success you get
admission to constantly rapidly.
Take a look at my page … thesportswiki.com; Dana,
Many small companies prefer to hire SEO specialists as consultants rather
than full time employees, unless they have a certain amount of websites that need to be continuously maintained and optimized.
The usual SEO methods include keyword research, link building and such.
But it is extremely important that anyone looking to hire an SEO professional be aware of the
differences. This mode of advertisement was faster than the
earlier ones and reached more people but it had its own limitations.
Look at my blog post simpatiaparaperderabarriga87.page.tl
the
Here is my webpage: unpaid speeding ticket in florida
the
Take a look at my page – speeding ticket in new jersey with new york license (Kraig)
my web blog :: traffic ticket search by name
As was said to start with of this text, web advertising is extremely necessary
for each business.
Visit my website social media marketing companies los angeles (Denese)
My page Speeding Ticket in New Jersey
It’s another Tarantino influenced effort and offers a lot of
dumb, violent fun. The graphics, sound effects
and creepy environment makes the game one of the scariest horror games.
As far as I am concerned, when I purchase something it should be
mine to do with as I please.
My website – gry strategiczne mmo
the
Feel free to visit my homepage … traffic ticket miami
dade payment (Keeley)
Find out the improvement in between video games by checking out the helpful article below.
Also visit my website: http://www.thechickenlegs.com/component/k2/author/95568
everything from contesting your ticket.
Also visit my weblog traffic ticket miami dade search,
Magda,
The only means to proceed in the game is by getting increasingly more resources and
also updating.
Here is my blog: http://profokno18.ru
That was the best thing I ever completed for my organization, my page
gets alot far more consideration and my business last
but not least looks massive!
Also visit my web-site :: instagram followers snapchat hack iphone
We’ll speak about much more complex Clash of Clans war strategies you could utilize to dominate leading gamers
in future posts.
Feel free to surf to my webpage; http://www.gruine.lt/
I absolutely love your site.. Excellent colors
& theme. Did you create this web site yourself? Please reply back as I’m looking to create my very own blog and would love to find out where you got this from
or exactly what the theme is called. Many thanks!
You can buy rechargeable power products for any controller.
Feel free to visit my web page :: http://Www.representacao.eurimaquinas.com.br
Each of them has a different function according to the intensity of the misspelled keywords.
The Internet has changed the way we attain information forever and Google has been the
main driving force and proponent behind this instant access
to information. Your baseline will tell you where your company began so you
can measure positive or negative ROI (return on your investment).
Eventbrite is an online party-planning tool with KISS (Keep It Simple Stupid) design so it
is usually a top rated choice among event planners (organizers).
Feel free to surf to my page … laboredallure1074.snack.ws
It’s very trouble-free to find out any topic on web as compared
to books, as I found this post at this web page.
Have a look at my web page; winkle cream
Whatever your specialty in pc gaming is, or what the function behind your play,
there is consistently something brand-new to learn!
Feel free to visit my blog :: http://www.chaitrading.com/?option=com_k2&view=itemlist&task=user&id=186815
Here is my web-site :: http://www.iamsport.org
Familiarize the recent trends in video gaming to make the
most of the technological innovations that are
out on the market today.
My web page: Valeria
Everything is very open with a very clear description of the
challenges. It was definitely informative.
Your site is useful. Thanks for sharing!
Set age proper restrictions to gaming communications with others online.
Have a look at my web page: http://www.lionelpictures.com
great post I’m a big Vegas travellerfan from Thailand
The power is high amongst the basic population and
frankly motion image about a man who has accomplished such a wonderful amount in his life.
Each of them has a different function according to the intensity of the misspelled keywords.
The Internet has changed the way we attain information forever and Google has been the main driving force and proponent behind this instant access to information. Unlike
TV, radio and other traditional marketing channels that need big budgets to be effective, SEO can be cost effective.
You have to take price quotes from different SEO companies locally and
internationally.
Feel free to visit my web blog … hvacfrederickmd2683.hazblog.com
Hey! I know this is kind of off-topic but I needed to ask.
Does operating a well-established website like yours require a massive amount work?
I’m brand new to blogging however I do write in my diary everyday.
I’d like to start a blog so I can easily share my own experience and views
online. Please let me know if you have any ideas or tips for
brand new aspiring blog owners. Thankyou!
Hello mates, good article and nice arguments commented at
this place, I am really enjoying by these.
Set as an example two time weekly or some other limit that is not allowed to surpass.
my page: liveinstyle.com.br
Hurrah, that’s what I was looking for, what a information! existing here at this
weblog, thanks admin of this site.
Feel free to surf to my web-site: Funny Cats And Dogs In Pictures 7
Thanks foг sharing yߋur thߋughts abօut center hurricane ike.
Ʀegards
Ηere is my web site: San Francisco 49ers game tickets
Hi! Would you mind if I share your blog with my twitter group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Cheers
Great article! We are linking to this great article on our site.
Keep up the good writing.
Simply want to say your article is as astonishing.
The clearness in your submit is just great and that i could
think you are a professional in this subject. Fine with your permission allow me to seize your feed to keep updated
with imminent post. Thank you one million and please
carry on the gratifying work.
Hello! This is kind of off topic but I need some advice from an established blog.
Is it tough to set up your own blog? I’m not very techincal
but I can figure things out pretty fast. I’m thinking about making my own but I’m not sure where to start.
Do you have any tips or suggestions? Thank you
Although Yahoo isn’t the biggest, or the highest ranking search engine on the internet, it is still one of the most essential, and if you want use search engine optimization and
promotion as a main technique in your marketing arsenal, you unquestionably need to get listed here.
Two: Research different services – Assuming that you are going to hire someone to do it for you, the next step is to research as many different services as possible.
Thematic relevance is of key importance for the creation of quality
backlinks. Webmaster follows a long process to promote a website in top search engines (Google, Yahoo and Bing).
My homepage; http://www.purevolume.com
It’s the best time to make some plans for the long run and it
is time to be happy. I’ve learn this put up and if I may just I desire to recommend you some fascinating things or suggestions.
Perhaps you can write next articles regarding this article.
I wish to learn more things about it!
I blog frequently and I really appreciate your content.
Your article has really peaked my interest.
I’m going to take a note of your website and keep checking for
new details about once per week. I subscribed to your RSS feed too.
Most people grow up being very good with the spoken word in their native tongue,
but when they are asked to write, many of them have a problem.
Conclussions are generally more extensive than afterwords
or epilogues. There you can read more details that can be
helpful for you in getting to know these great books.
I am really inspired with your writing abilities as neatly as with the format for your weblog.
Is that thiks a paid theme or ddid you modify it yourself? Either way keep
up the nice high quality writing, it’s uncommon too look a nice blog like this one these days..
mit Amateurfilme und sexCam
My weblog :: click this; Isidro,
Hello there I am so grateful I found your webpage, I really found you by error, while I was searching on Askjeeve for something else, Anyhow I am here now and would just like
to say many thanks for a remarkable post and a
all round exciting blog (I also love the theme/design), I don’t have time
to go through it all at the moment but I have book-marked it and also added in your RSS feeds,
so when I have time I will be back to read more, Please do
keep up the fantastic jo.
My brоther recommended I mighyt like this website.
Ңe was once totally riɡht. Tɦis publish actually
made my day. Yߋu cann’t believе simρply how mjch time I had spent
forr this infоrmatiοn! Thank you!
Feel free to surf tο myy weblߋg … pharmaceutical rep salary
Hello There. I found your blog the usage of msn. That is a really well written article.
I will make sure to bookmark it and come back to read more of your useful information. Thank you for the post.
I will definitely return.
As men age their body’s begin to take on more, and more estrogen, which virtually castrates a
man. Customs officials have intercepted everything from exotic animals,
including lizards, snakes, and tropical birds to narcotics and other controlled
substances at LAX and other ports of entry, but a huge
shipment of Cialis is very unusual. All these medicines like Generic Viagra,
kamagra, penegra, zenegra, edegra, silagra are similar and contain the same molecule.
Do you have a spam problem on this site; I also
am a blogger, and I was curious about your situation; we have created some nice procedures and
we are looking to exchange techniques with others, please shoot me an e-mail
if interested.
Excellent goods from you, man. I have understand your stuff previous to and you’re
just too excellent. I actually like what you have acquired here, certainly like what you’re stating and the way in which you say it.
You make it entertaining and you still care for to keep it sensible.
I cant wait to read far more from you. This is really a tremendous web site.
Howdy! Would you mind if I share your blog with my zynga group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Cheers
Ӊi there it’s me, I am also visiting this website daily, this web site is really ցօood and thе viewers are truly sharing fastidiօuѕ thoughts.
my homepage: pharmaceutical sales jobs mn
Upstream websites are sites that folks visited just earlier than they visited this website.
my web page :: mahaveg.co (Leonardo)
Hi there, after reading this remarkable piece of writing i
am too happy to share my know-how here with friends.
Right away I am ready to do my breakfast, later than having my breakfast coming again to read additional news.
My developer iѕ trүing to congince me tto ove to .net frоm PHP.
I havge ɑlways disliked tɦe dea becaise оf the costs.
But he’s tryiong non thе leѕs. I’ѵe Ьeen uѕing Movable-type ߋn sevеral websites fߋr abvout a yeear and am nervous ahout switching tօ anothеr platform.
I have heɑгd vеry gοod things about blogengine.net.
Іs there a ѡay Ι caan transfer ɑll mу wordprwss ϲontent into it?
Any kind of help ԝould bе relly appreciated!
Hi! This is my first visit to your blog! We are a group
of volunteers and starting a new project in a community in the
same niche. Your blog provided us valuable information to work
on. You have done a marvellous job!
Impoortance oof neeing a ell written, pprofessional looiking resume: Companiies don’t intervview ecery
appliccant ffor thhe job. Studentts weiting a dissedrtation hsve too
utjlize boh essentfial andd auxilary sources, tat thgis majoriuty off
thhe students aree noot ble too have to. I havee ann ideda – let’s write
a paragraph frolm myy creative boook – iin ouur article.
my webb sijte – self publishing
Hi to every body, it’s my first pay a quick visit of this blog; this weblog
contains awesome and genuinely good information for visitors.
Supersetting involves performing two workouts with none
break to successfully construct muscle and burn fat.
Continued use will help improve digestion, treat or even eliminate bad breath, improve his dental health, help his body to absorb vitamins and nutrients, and help
heal stomach disorders such as colitis and inflammation. To get
rid of spiders in the house, spray lavender oil in areas that spiders tend to congregate.
Also look for unrefined coconut oils, like Virgin Coconut Oil.
Here is my web-site – coconut oil uses – Rozella,
Hi I am so grateful I found your weblog, I really found you by accident,
while I was browsing on Google for something else, Regardless I
am here now and would just like to say cheers for a incredible post and a all round interesting blog (I also love the theme/design), I don’t have time to read it all at the
moment but I have bookmarked it and also added your RSS feeds, so when I
have time I will be back to read a lot more, Please do keep up the great job.
I would like to thank you for the efforts you’ve put in writing this site.
I really hope to check out the same high-grade content by you in the future as well.
In truth, your creative writing abilities has inspired me to get my own,
personal site now 😉
Good day! This is my 1st comment here so I just wanted to give a quick shout out and say I truly enjoy reading through your articles.
Can you suggest any other blogs/websites/forums that cover the same topics?
Thanks a lot!
It is appropriate timе to make some plans fߋr the future аnd it is time
to bе hаppy. I’ve read thіs post and if
I could I ѡant to sսggest you ѕome іnteresting things or suggestions.
Ρerhaps you can write next articles referring tо this article.
Ι wish to гead even more things аbout it!
My paցе; UGG Boots Men
This is my first time visit at here and i am actually happy to read all at alone place.
Please remember that the key in this sort of business is decent service.
That goes without saying all of the previous consoles before them can also be
easily emulated. As far as I am concerned, when I
purchase something it should be mine to do with as I please.
Feel free to visit my webpage … darmowe Gry dla dziewczyn
I think the bit of price increase is wokrth getting the freshest and most delicious coffee around, that is also very good for you to drink.
Not only are these birds beautiful to enjoy, but thy also contribute to
the ecosystem bby dispersing seed and pollinating flowers.
Similarly, one of most the common fertilizers used on Organic Coffee is made from petroleum-based chemicals which can leave soil barren and seep into the water supply causing.
Thanks for sharing your info. I truly appreciate your efforts and I will be waiting for your further post thank you once again.
Great ցoods frοm yoս, mɑn. I have haνе
iin mind your stuff prior tօ and ƴou’re just tߋο magnificent.
I really like what yοu haνe got here, certainlу like աhat you ɑrе stating and thee best աay whereinn you assert it.
Yoս arе making it entertaining aand уou still takе care of to stay it wise.
І can’t wait to learn mucɦ more from you. Thaat іs rеally а
wonderful site.
Ңere is mү blog cincinnati reds discount tickets
Ӊey there! Woud you mind if I share үour blog with my facebook
group? Therе’s a lot off people that I thiink would rsally appreciate your content.
Please let mee know. Mɑny thanks
Hi, constantly i used tto check blog posts ɦere
еarly in tɦe morning, beсause i like to learn more
and more.
Feel free tߋ visit mу web-site ny giants ticket exchange
Somebody necessarily help to make severely articles I might state.
That is the very first time I frequented your web page and
so far? I amazed with the analysis you made to make this particular put up
extraordinary. Excellent task!
I think the admin of this site is genuinely working hard in support of
his web site, for the reason that here every data
is quality based material.
Hi to all, it’s truly a nice for me to go to see this website, it contains precious Information.
I don’t even understand how I finished up here,
however I believed this put up used to be good.
I don’t recognise who you might be but certainly you’re going to a famous
blogger should you aren’t already. Cheers!
Definitely believe that which you said. Your favorite justification seemed
to be on the internet the easiest thing to be aware of. I say to you, I definitely get
irked while people consider worries that they plainly do
not know about. You managed to hit the nail upon the top and
also defined out the whole thing without having side effect , people can take a signal.
Will likely be back to get more. Thanks
Also visit my blog post :: website – Tracey –
Attractive component to content. I just stumbled upon your website and in accession capital
to claim that I acquire in fact loved account your blog posts.
Anyway I’ll be subscribing in your augment or even I success you access constantly
rapidly.
Heya i am for the first time here. I found this board
and I find It truly useful & it helped me out a lot.
I hope to give something back and aid others like you helped me.
Also visit my web site; cat flea bombs (Dakota)
Thanks for some other magnificent article.
Where else could anybody get that kind of info in such a perfect way
of writing? I’ve a presentation subsequent week, and I
am at the search for such info.
Thanks for ones marvelous posting! I actually enjoyed reading
it, you might be a great author. I will always bookmark your blog and will come
back later on. I want to encourage you to continue your great posts, have a nice afternoon!
Half Boil: Half Boil is an interesting free downloadable egg
catching game. If it’s a big game, an hour gives you enough time to figure
out if you want to really get into it. As far as I am
concerned, when I purchase something it should be mine to do
with as I please.
my blog :: gry dla dziewczyn za darmo
Hi there to every body, it’s my first visit of this web site;
this web site contains remarkable and truly good data in favor
of visitors.
Redakcję tworzy zespół osób żywo zainteresowanych życiem publicznym lokalnej społeczności.
Skład redakcji stanowią w większości osoby
pragnące zachować anonimowość.
Należy zaznaczyć, że każdy ponosi odpowiedzialność za zamieszczane przez siebie treści,
np. wpisy i komentarze. Dlatego, nie należy utożsamiać poglądów redakcji z tymi treściami.
Jednocześnie zapraszamy do współpracy wszystkich,
którzy tak jak my zainteresowani są lokalnymi sprawami.
pole
Howdy! TҺis post coulԁn’t bе wrіtten any Ƅetter!
Reading through this post reminds me of my prеvious гoom mate!
Hе alwɑys kеpt talking aƅout this. I will forward thіs article to him.
Fairly certain he will ɦave а good read. Manny
thanks fоr sharing!
Feel free to visit my blog post: brewers game tickets
Currently it appears like Drupal is the best blogging platform available right
now. (from what I’ve read) Is that what you’re using on your blog?
my webpage – video sales – facebook.com –
VERDICT / When you happen to stay in an space
that has access to Suddenlink high-pace internet,
this company is value contemplating.
Here is my web page … low cost internet service nyc (affiliate-marketing.6ra.org)
There are a number of challenging scenarios, and there’s even a
sandbox-like scenario where you can basically build
whatever type of zoo you desire. The graphics, sound effects and creepy environment
makes the game one of the scariest horror games.
With the proper level of respect for the original content, the desire to innovate, and a true
love for the franchise, any of these games could still potentially make an explosive–or at least successful–comeback as a smaller indie game or (perhaps) even a
full-scale AAA title.
Also visit my site; gry mmorpg
You really make it seem so easy with your presentation but I find this matter to be actually something that I think I would never understand.
It seems too complicated and very broad for me. I’m looking forward for your next post, I will try to get the hang
of it!
hey there and thank you for your information – I’ve definitely
picked up anything new from right here. I did however expertise several technical issues
using this site, as I experienced to reload
the web site a lot of times previous to I could get it to
load correctly. I had been wondering if your web host is OK?
Not that I am complaining, but sluggish loading instances times
will often affect your placement in google and
could damage your high-quality score if ads and marketing with Adwords.
Anyway I’m adding this RSS to my e-mail and
could look out for a lot more of your respective fascinating
content. Make sure you update this again soon.
An optometrist is a healthcare professional who examines metro to measure eyes and prescribes corrective lenses and may treat eye diseases.discussion [url=http://genericcialischeapnorx.com]cialis 20mg price at walmart[/url] CXR see Figure a.Using the following data and the data in Tableeczema atopic dermatitis Inammatory skin disease with erythematous papulovesicular or papalosquamous lesions.influenza type B HIB vaccine and menin gococcal and pneumococcal vaccines.The efficacy of alprostadil suppositories in combination with other treatment modalities recently has been evaluated. [url=http://clomiphene60pills25mg.com]Clomid[/url] Reading MA AddisonWesley Publishing Co.million per mm or L Segs polys Hct M Lymphs F Eos Hgb M gdL Baso F gdL Mono Platelets mm or L FIVE SHORT CLINICAL CASESJ.Complex means impaired consciousness and partial indicates not generalized..Achalasia is a rare disorder.General characteristicsDiseases of the Gastrointestinal System DiSeaSeS of the GaStrointeStinal SyStem l b. [url=http://buyfurosemideus.com]furosemide 40 mg buy online[/url] S.F.positron emission tomography PETENERGY EXPENDED IN RUNNING In Chapter we obtained the energy expended in running by calculating the energy needed to accelerate the leg to the speed of the run and then deceler ating it to rest. [url=http://buytadalafilgeneric.com]cialis viagra combo pack[/url] He denies any pain.Nat.The common cold and influenza viruses are masters of this art constantly mutating to adapt and thereby evade the defenses of the immune system.Helical spiral computed tomography scan of the chest with IV contrast CTpulmonary angiography or CTPA. [url=http://cheapcialispillsfast.com]Tadalafil[/url] The causative Bacillus anthracis had already been isolated and identified in the mids by Pasteurs rival Robert Koch see pp.
Hey there, You’ve done an incredible job.
I will certainly digg it and personally suggest to my friends.
I’m confident they will be benefited from this site.
Actually, you may as nicely save your ways too make money on the internet fast (Paul):
you’d simply be throwing it awy shjould yyou strategy Internet advertising and marketing from this perspective.
What’s up to all, for the reason that I am truly eager of
reading this webpage’s post to be updated on a regular
basis. It contains good information.
Very good article! We are linking to this great post on our website.
Keep up the great writing.
It’s impressive that you are getting thoughts from this paragraph as well as from our dialogue made here.
My blog post :: informative post (bdsm-wiki.org)
Howdy! Would you mind if I share your blog with my facebook group?
There’s a lot of people that I think would really appreciate your
content. Please let me know. Thank you
Howdy, i read your blog occasionally and i own a similar one and i was just curious if you get a lot
of spam comments? If so how do you prevent it, any plugin or anything
you can advise? I get so much lately it’s driving me insane so any support is very much appreciated.
Hello very nice blog!! Guy .. Beautiful .. Wonderful .. I will bookmark
your blog and take the feeds also? I’m glad to search out so many useful information here
within the publish, we need work out more techniques in this regard, thanks for sharing.
. . . . .
If one other individual asks for a similar bundle
in your space he’ll get it but you will not.
My web blog :: cheapest internet provider nyc 2013 (mariahrafting.com)
Hi! Someone in my Facebook group shared this site with us
so I came to take a look. I’m definitely enjoying the information. I’m book-marking and will be tweeting
this to my followers! Terrific blog and amazing design.
I am sure this article has touched all the internet people, its really really pleasant article on building
up new web site.
What’s up colleagues, pleasant piece of writing and good urging commented
here, I am actually enjoying by these.
Good way of telling, and pleasant piece of writing
to obtain information regarding my presentation focus, which i am going to
convey in college.
I’m impressed, I have to admit. Rarely do I encounter a blog that’s equally educative and interesting, and let me tell you,
you’ve hit the nail on the head. The issue is something that
not enough folks are speaking intelligently about. I’m very happy I stumbled across this in my search
for something regarding this.
Hi there, everything is going well here and ofcourse every
one is sharing information, that’s in fact fine, keep up writing.
Let us come across an evaluation about how useful these offerings of Google are for us.
Moreover, the version shipping with the Jolibook will be preloaded with Chromium for a web browser, which
is anticipated to auto-update to the latest version to
make it easy for the common customers. There
are proxies and software programs to change the location but they will not work for this purpose.
Peculiar article, just what I was looking for.
Thanks for a marvelous posting! I definitely enjoyed reading it,
you are a great author. I will make certain to bookmark your blog and will
eventually come back in the foreseeable future.
I want to encourage one to continue your great job, have a nice weekend!
Creando GRATIS tսѕ Aplicaciones con Mobincube, lеs añadiremos
publicidad ү tú consеguirás el setenta рor cienjto de los ingresos
quе sе generen.Planeta Pocoyo” & © 2009 – 2015 Zinkia Entertainment, Una aplicación vital
para cսalquier dispositivo Android ʏ que puedes
descargarte Ԁе fοrma gratuita en Google Play:
Quality articles is the key to be a focus for the viewers to go to see the
website, that’s what this site is providing.
Good day! I simply would like to offer you a huge thumbs up for
the excellent info you have right here on this post. I will be returning to your blog for more soon.
Тhеre is definately ɑ llot to fіnd out about this issue.
I really liқe aall the рoints ʏoս’ve maɗe.
I prefer VPNs because they’re a more exclusive way to change IP.
This coverage will pay for the medical expenses for virtually any insured driver regardless of fault
along with the treatments because of the accidents. The screen can be covered with a
transparent screen protector which would prevent scratches.
My site :: coques iphone 5s
One of such uncommon things is the ‘destination wedding’. Here,
if you don’t care much about your wedding budget,you could follow the lead of those super stars, enjoying the Indian stylewedding ceremony.
Noodle from China had developed in the area, and every Asian country has its own style of noodle.
Here is my homepage; avengers age of ultron full movie
Wonderful post however , I was wondering if you could write a litte more on this topic?
I’d be very thankful if you could elaborate a little bit further.
Thanks!
We offer the best quality wholesale jerseys with the cheapest price.
You can never miss. Buy and enjoy free shipping
all over the world.
more from : wholesale jerseys
To end in Success, effort alone will not be enough,
Dr. Lakshmi Jeya Swaruoopa says.
Also visit my web blog the power of positive thinking (Avis)
Greetings from Los angeles! I’m bored to tears at work so I decided to
check out your site on my iphone during lunch break. I enjoy the information you provide
here and can’t wait to take a look when I get home.
I’m shocked at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, superb blog!
This is my neighbourhood. It’s called Caballito. If you liked it,
please vote for it in this link: https://www.socialtools.me/index.php?… by clicking the “votar” (vote) button. Furthermore,
you can visit Buenos Aires. It’s a beautiful city where you can learn a lot about Argentina’s culture.
if you ever decide to come, you should take the City’s tour bus!
You’ll learn about many historical places and meet very good people.
If you’re interested in this, you can view more details in this link:
http://www.buenosairesbus.com/
Fantastic site. A lot of useful info here. I am sending it to
a few buddies ans additionally sharing in delicious.
And certainly, thank you in your effort!
Here is my web blog … jaynie mae baker linkedin, Emmett,
First, at the moment Amazon’s 4K service is only available in the
US, whereas Netflix’s 4K content is much more widespread.
I havе toօ thank ʏou for the efforts уou’ve put іn writing
this site. I’m hoping tߋ ѵiew tɦe ssame Һigh-grade blog posts
fro ƴօu later on аs well. In truth, your creative writing abilities hass encouraged mе to get my very
own website now 😉
my blog post; adult movies
Greetings from California! I’m bored to tears at work so I decided to check
out your blog on my iphone during lunch break. I love the knowledge you
present here and can’t wait to take a look when I get home.
I’m shocked at how quick your blog loaded on my phone .. I’m
not even using WIFI, just 3G .. Anyways, excellent blog!
Unquestionably believe that which you said. Your favorite justification appeared
to be on the web the easiest thing to be aware of.
I say to you, I certainly get annoyed while people consider worries that they just don’t know about.
You managed to hit the nail upon the top as well as defined out
the whole thing without having side effect , people could take a signal.
Will probably be back to get more. Thanks
Good post. I learn something new and challenging on sites I
stumbleupon everyday. It’s always interesting to read through articles from other writers and
use something from their websites.
I will right away seize your rss feed as I can’t find your email
subscription link or e-newsletter service. Do you have any?
Kindly allow me understand so that I could subscribe.
Thanks.
Feel free to surf to my web page – divano letto a castello a scomparsa
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why throw away your intelligence on just posting videos to your
blog when you could be giving us something informative to read?
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I’m quite sure I’ll learn many new stuff right
here! Best of luck for the next!
my webpage; webpage (Tommie)
Wow that was strange. I just wrote an incredibly long comment but after I clicked submit my comment
didn’t appear. Grrrr… well I’m not writing all that over again. Anyways, just
wanted to say excellent blog!
My spouse and І absolutely love yоur blog aand fіnd many of yοur post’sto bе exactly what I’m lοoking foг.
Do үou offer guest writers to wwrite contet аvailable for yߋu?
I wouldn’t mind creating а post oг elaborating on a number of
thе subjects ʏoս write related to Һere. Agaіn, awesome
weblog!
Exceptional post however I was wanting to know if you could write
a litte more on this topic? I’d be very thankful if you could elaborate a little bit
more. Bless you!
If you have any type of inquiries relating to exactly where and how
to make use of how to take surveys for cash , you could get in touch
with us at our own internet-internet site.
Feel free to surf to my page Money Making Ideas from Home Australia
An interesting discussion is definitely worth comment. There’s no doubt that
that you ought to write more on this topic, it might not be a taboo subject but usually people do not talk about such issues.
To the next! Cheers!!
My blog post: Nike Air Max Baratas Mujer
I must thank you for the efforts you’ve put in penning this website.
I am hoping to see the same high-grade blog posts by you
in the future as well. In truth, your creative writing abilities has motivated me to get my own, personal
site now 😉
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between user friendliness and visual
appearance. I must say you’ve done a very good job
with this. Additionally, the blog loads very fast for me on Safari.
Excellent Blog!
If you wish for to get a ցreat deal from thіs post then you hаvе to apply sսch techniques tօ yߋur won weblog.
mƴ web-site – homemade porn
Your method of telling all in this paragraph is in fact pleasant, all be capable
of easily know it, Thanks a lot.
Appreciate this post. Will try it out.
Sweet blog! I found it while surfing around on Yahoo News. Do you have any tips on how to get listed
in Yahoo News? I’ve been trying for a while but I never
seem to get there! Thank you
I’m gone to inform my little brother, that he should also pay a visit this
website on regular basis to take updated from newest news.
Hello, just wanted to say, I loved this article.
It was funny. Keep on posting!
Dօ үօu mind iff I quote a few oof your pposts aѕ long ass
I provide credit and sources Ƅack tߋ youг blog? Ӎy bllog site iss inn tҺe exact same area
օf interеѕt аs youгs and my սsers would trulү benefit from a
lot оf tҺe infoгmation you present here. Plеase lеt me know iif this
alright wіtҺ уou. Thanks a lot!
Visit mƴ webpage :: Make Money with Google and ClickBank
The best i – Phone cases aren’t just functional they should look great too.
It has a lid or cover that works as a keyboard, reminiscent of Microsoft’s Surface tablet that debuted a couple of years ago.
The Flashcard Touch app is available at the i – Tunes App Store
for $4.
Also visit my weblog … coques iphone 5
Hello to every body, it’s my first pay a quick visit of this webpage; this blog carries awesome and
truly good data for visitors.
Stop by my blog – Things To Do In Kauai
Ƭhere іs сertainly a grеat deal to кnoԝ about tɦis
issue. I lіke all of tҺe poіnts you’ve madе.
Feel free to visit my webpage … UGG Boots UK
Justt want tto say your article is as surprising. The clearness foor your puut up is simply great and that i could
think you’re an expert in thhis subject. Fine with yor permission let
me to seize your RSS ferd to keep updated with imminent post.
Thank youu a million and please carry on the gratifying work.
my web site :: cinema (http://www.reddit.com)
Magnificent site. A lot of useful info here. I’m sending it to several buddies ans additionally sharing in delicious.
And of course, thanks for your sweat!
Holding on to anger and resentment builds up inside you,
acting as a poison both to you and the marriage.
You may name the opposite guys and pay the complete value if you’re in Atlantic Metropolis and need a Dumpster Rental 33883 or you’ll find out what
High Canine Dumpster Rental Atlantic City NJ can give you.
This place is for real and the decreased prices are for actual too,
however you will not ever know until you call and discover out.
Empresas y servicios relacionados con Castillos hinchables: alquiler en Alhaurin De La Torre – Malaga.
I really love your website.. Excellent colors & theme.
Did you develop this website yourself? Please reply
back as I’m trying to create my own website and would
love to find out where you got this from or just what the theme is named.
Many thanks!
My blog post; ALL KWs
yöntem aynı zamanda hızlı bir şekilde her bir
kategori için başından yanı sıra benim
ruhsal hatıraları bir sonucu olarak ortaya herhangi bir değişiklik ekleme fırsatı olayların düzenli dizisi
tanımlamanın bir yolu bana sağlayacak kesinlikle her yerde en iyi indeksleme sistemi
nedir benzersiz kayıtların geniş bir teklif monte
Also visit my weblog – koray büyükasar istifa
Although being aware of keyword percentages is a good idea, it
is more important that content be relevant and useful to the visitor.
Thirdly, the search engines need legit companies to do
site optimization. While effective SEO needn’t be difficult, it does
take work. You have to take price quotes from different SEO companies locally and internationally.
Look at my web page; http://Nexopia.com/users/dcseo23480/blog/4-simple-guidelines-to-help-you-understand-reputation-management
Throughout pre-manufacturing, carpenters normally work out of a
movie manufacturing’s workshop.
My website; website
Can I simply say what a comfort to discover somebody that genuinely understands what they are talking
about over the internet. You actually know how to bring an issue to light and make
it important. More and more people have to check this out and understand this side of your story.
I can’t believe you are not more popular since you surely possess
the gift.
comment grossir naturelement des seins
porn,porno,x-rated,xxx,nude,naked,chicks,sex,free,cheap,nude,naked,sex,porn,porno,torrent,torrents,youtube,craigslist,ebay,kijiji,sex,sex
education,www.sex education.com,sex hotel,
sex education for adults,sex in hotel,sex song,sex education films,best sex songs,sex education in schools,sex music
You really make it appear so easy with your presentation however I find this matter
to be actually one thing which I think I would never understand.
It kind of feels too complicated and very vast
for me. I’m looking forward in your subsequent
post, I will try to get the hold of it!
My brother recommended I would possibly like this blog.
He used to be totally right. This put up actually made my day.
You cann’t consider simply how a lot time I had spent for
this info! Thank you!
İşte Koray Büyükasar yaşam ve zaman açısından bazı daha
ilginç gerçekler
Here is my weblog; koray buyukasar istifa
Pretty! This has been an incredibly wonderful article.
Thank you for providing this info.
Every weekend i used to pay a quick visit this website,
for the reason that i wish for enjoyment, for the reason that this this website conations truly
nice funny stuff too.
Hi there, I enjoy reading through your post. I wanted to write a little
comment to support you.
Hello, I believe your website could be having inyernet browser
compatibility problems. When I look at your site in Safari, it looks fine but
when pening in I.E., it has some overlapping issues.
I merely wanted to provide you wth a quick heads up!
Besides that, excellent site!
Here is my weeb page – increase your vertical jump- 12 inches in 8 weeks
The general public is sort of curious about the i – Phone 5 also proficient is indeed unusually of bubble about what sort of individuality undoubted could carry.
You want to be sure that you are certain to get the service that you
paid for. Using the Life – Proof case for taking photos and video underwater works
amazingly well.
Here is my web page :: coques iphone 5
Hello, I think your site might be having browser compatibility issues.
When I look at your website in Chrome, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, amazing blog!
I want you to know this truth… I want you to give your marriage
completely to God.
Many specialists in diabetes consider exercise so important in the management of
diabetes that they prescribe rather than suggest
exercise.
Here is my page speeding tickets in georgia out of state (Carmine)
Hello there! This article could not be written much better!
Looking through this article reminds me of my previous roommate!
He constantly kept preaching about this. I will
forward this post to him. Fairly certain he will have a good read.
Thanks for sharing!
Also visit my site Red Siberian Husky Wallpaper
Have you ever considered about adding a little
bit more than just your articles? I mean, what you say is important and all.
But imagine if you added some great graphics or video clips to give your posts more,
“pop”! Your content is excellent but with images and clips, this blog could definitely be one of
the greatest in its field. Great blog!
Great article! We will be linking to this particularly
great article on our website. Keep up the good writing.
Here is my website – Very Easy Pencil Drawings For Beginners
Howdy I am so grateful I found your web site, I really found you by
accident, while I was browsing on Digg for something else, Anyways I am here now and would just like
to say thanks for a remarkable post and a all round interesting blog (I also love
the theme/design), I don’t have time to go through it all at the moment but
I have saved it and also added your RSS feeds, so when I have
time I will be back to read a great deal more, Please do keep up the awesome job.
Plus, our new FiOS Quantum Gateway router,
designed to maximize the ability of the FiOS community, provides you the fastest Wi-Fi
obtainable from any supplier.
Here is my web site … low cost internet service nyc (scef.com.ng)
Are you dwelling under a rock?
My web site – muscle and Fitness hers workout routines
It’s hard to come by knowledgeable people about this subject, but you sound like you know what you’re talking about!
Thanks
to gain
my homepage … speeding ticket in georgia calculator
An simple way to get totally free clash of clans attack approach city corridor
degree 7 youtube gems immediately!
Feel free to surf to my web-site: is there a clash of clans hack without human verification
It’s hard to come by experienced people on this topic,
but you sound like you know what you’re talking about!
Thanks
My page Latasha
Thanks in favor of sharing such a fastidious opinion, post is good,
thats why i have read it fully
you’re truly a just right webmaster. The web site loading pace is incredible.
It sort of feels that you are doing any distinctive
trick. Moreover, The contents are masterpiece.
you’ve done a wonderful task in this matter!
Very nice post. I simply stumbled upon your blog and wished to say that I have truly loved surfing around your blog posts.
After all I will be subscribing in your feed and I am hoping you write
again soon!
There is constantly a brand-new gaming system coming out, and if you resemble the majority of
people you have greater than one system.
You could certainly see your skills within the work you write.
The world hopes for even more passionate writers
like you who aren’t afraid to mention how they believe. At all times follow your heart.
Paul’s Cathedral, the fun and products, companies need money management.
No video games were found matching the criteria specific.
The morning and afternoon routines will burn fat
and increase your cardio, while the evening routine will help build strength.
This free tool finds out who is linking to your site and gives a useful benchmarking report to quickly show where you stand in comparison to competitors and other major online players.
Number 4: If you’re not so much into the “couple’s thing” as they call it, you can always go to the prom in a group and have fun together.
Sporting an almost even assortment of high top and low top sneakers in numerous looks.
Here is my web page: cheap giuseppe zanotti shoes
Appreciate the recommendation. Let me try it out.
Stop bby my web site: web page (Douglas)
I’m extremely impressed together with your writing skills as smartly
as with the format to your weblog. Is that this a paid subject matter or did you modify
it your self? Either way stay up the nice quality writing, it is rare
to peer a great weblog like this one nowadays..
Stop by my web-site – Auto Wealth Bot
The Canon Power – Shot D10reviewed in the second article in this series is quicker and the
image quality is a little better too. That question became the mission for Sony as they went about developing
a mirrorless interchangeable lens compact camera to compete with the likes of the Panasonic GH1, the Olympus PEN system
and the Samsung NX10. This individual likewise made positive comments regarding the display screen being big and
bright.
my page sony dsc wx50/b digital camera
Great blog you have here.. It’s hard to find high quality writing like yours these days.
I truly appreciate people like you! Take care!!
Do уou mind if I quоte a couple of your аrticleѕ ass long
as I provide credіt anԁ ѕourcеs baсk to your wеbsіte?
My website is in the very same arsa of interest as yourѕ anԁ myy visіtors ωould really benefit from a lot of the infoгmatiοn yοu рrеѕent
here. Pleаse lеt me knnow if this okay with you.
Тhanks!
Ηегe іs my wеb pаge free games download
Wow that was unusual. I just wrote an incredibly long comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Anyway, just wanted to
say superb blog!
Hello, this weekend is fastidious in support of me, as this moment i
am reading this enormous informative paragraph here at my residence.
To snatch the interest of men and women is a doubting task when you just encourage your company on Instagram.
Look into my webpage; how to get free instagram followers without survey
Wow! At last I got a web site from where I be
able to in fact get valuable data concerning my study and
knowledge.
Thanks for sharing such a fastidious thought, piece of writing is nice, thats why
i have read it fully
onunla ilgili Koray Büyükasar
Also visit my blog :: koray büyükasar suçlama
There is definately a lot to find out about this topic.
I really like all of the points you have made.
Hey just wanted to give you a quick heads up.
The text in your post seem to be running off the screen in Firefox.
I’m not sure if this is a formatting issue or something to do with browser compatibility but I thought I’d post to let you know.
The design look great though! Hope you get the issue solved
soon. Thanks
Stop by my web blog: hack clash of clans no download
coach online outlet store cheap ϲoach bags outlet,Cheap Coach
Purses,Coach Bags Outlet,coach bags outlet online,Coach Factorу Outlet,cօach online
outlet store,Coach Outlet Online,Coach Outlet Store Online,coach outlet
wallets 80% off,Coach purse outlet,Coach Puгses On Sale,Cоaches For Sale,super cheap coach purses cheap coach bags outlet
My brother recommended I might like this web site.
He was totally right. This post actually made my day. You
cann’t imagine simply how much time I had spent for this information! Thanks!
Generally I do not read article on blogs, but I wish
to say that this write-up very forced me to try and do so!
Your writing taste has been amazed me. Thanks, very great article.
Just wish to say your article is as astounding. The clarity in your post is just
cool and that i could assume you’re knowledgeable in this subject.
Well with your permission allow me to grab your
feed to keep up to date with impending post. Thank you 1,000,000
and please keep up the rewarding work.
My web site … League of Angels Fire Raiders Hack Tool
Thank you for sharing your thoughts. I truly appreciate
your efforts and I am waiting for your next
post thank you once again.
Hello, I log on to your new stuff daily. Your story-telling style is witty, keep it up!
Today, the Gymboree corporation continue to grow as an excellent provider of various products and recreation activities for kids and is incorporated under the Gym-Mark, Inc.
However, while packing your things, you should always consider Samsonite Luggage Canada.
Since the station experiences 16 sunrises and sunsets over the course of the day, maintaining a regular sleeping and
working schedule can be a challenge.
Here is my web-site … cheap michael kors handbags
After going over a handful of the blog posts on your web page, I
honestly appreciate your way of blogging. I book-marked it to my bookmark webpage list and will
be checking back soon. Please visit my web site
as well and let me know how you feel.
Hi there, just became aware of your blog
through Google, and found that it’s really informative.
I am gonna watch out for brussels. I will be grateful if you continue this in future.
A lot of people will be benefited from your writing. Cheers!
Hello! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve
worked hard on. Any recommendations?
It’ѕ very simple tо fіnd ߋut any tlpic on web aѕ compared to textbooks, aas І foսnd this piece
of writing at tɦіs web site.
Wow, this post is pleasant, my sister is analyzing such things,
so I am going to convey her.
Un safari en Tanzanie en lodge et camp de tente dans les parcs du nord, et un sejour plage &
detente a Zanzibar a l’hotel de votre choix.
I would love to know what you would like to see described, explained, detailed, diagramed and presented in a
book about low-carb dieting.
Admit it, you’ve tried everything you can to get the fat pockets and cellulite
off your legs and hips.
If you really want to lose fat and keep it off forever then you need to start
putting your body to work FOR YOU instead of AGAINST YOU.
He desires to have entertaining, share his life and wat men want
inn a wife – Robbie, the end
settle down.
Have you ever thought about publishing an e-book or guest authoring on other websites?
I have a blog based upon on the same information you discuss and would love to have you share some stories/information. I know my viewers would enjoy your work.
If you are even remotely interested, feel free to send me an email.
This made me snort for a long time.
my website: hotshot bald cop
It’s an amazing article in favor of all the web users;
they will get advantage from it I am sure.
Although Yahoo isn’t the biggest, or the highest ranking search engine on the internet,
it is still one of the most essential, and if you want use search engine optimization and promotion as a main technique in your marketing arsenal, you
unquestionably need to get listed here. The usual SEO methods include keyword research, link building and such.
But in general here are the services that an online business owner should expect from dc
seo (Samual) experts and other agencies and consultants:.
Eventbrite is an online party-planning tool with KISS (Keep It Simple Stupid)
design so it is usually a top rated choice among event planners
(organizers).
Do actually suppose this is true?
Feel free to visit my weblog … hotshot bald cop
Jusst ѡish tߋ say үoսr article iss ɑs surprising.
Тhе clearness іn your post iss just gгeat and
i cߋuld assume ƴou’гe an expert on thius subject.
Fіne with your permission lеt mme to grab yoսr RSS fwed to keeep uρ to date ԝith forthcoming post.
Ҭhanks a mіllion and pleasе keep up the enjoyable work.
Exceptional post however I was wondering if you could write a litte more on this
subject? I’d be very thankful if you could elaborate a little bit further.
Appreciate it!
Simply want to say your article is as amazing. The clearness on your publish is simply great and that i could assume you are a professional in this subject.
Fine along with your permission let me to grab your
feed to keep updated with approaching post. Thanks
1,000,000 and please continue the rewarding work.
I enjoy what you guys tend to be up too. This sort
of clever work and reporting! Keep up the very good
works guys I’ve you guys to blogroll.
Hey there would you mind letting me know which webhost you’re
working with? I’ve loaded your blog in 3 different web browsers and I must say
this blog loads a lot quicker then most. Can you recommend a good hosting provider at a
honest price? Kudos, I appreciate it!
Hi there, I discovered your website via Google whilst
searching for a similar topic, your web site came
up, it seems to be good. I’ve bookmarked it in my google bookmarks.
Hello there, just changed into aware of your weblog thru
Google, and located that it’s really informative. I’m gonna be careful
for brussels. I’ll appreciate when you continue this in future.
Numerous people will be benefited out of your writing.
Cheers!
I used to be able to find good info from your blog articles.
Here is my blog post; Section 80G
The Weave Poles are a series of thin poles attached
to a straight plank base. Some breeds of dogs offer both home and personal protection. IObit
provides two editions of the anti-malware – a free and pro edition.
Also visit my blog post: dog training school (http://hotelestodoincluido.com.co/?option=com_k2&view=itemlist&task=user&id=421414)
If your site is relatively sound, the most important results for
you to consider are the keyword hits. The trends in this industry change and new developments
take place only when Google comes up with some novel feature that ends up breaking every site’s dc seo (http://www.123seowashingtondcexpert.xyz) and compels
them to consider a change in their current content presentation in order to
do well. Auro – IN has a strong team that is built on the delivery of outstanding campaign results,
customer service and appreciation, and high levels of technical capabilities and values.
A guy named Alan Emtage, a student at the University of Mc
– Gill, developed the first search engine for the
Internet in 1990.
As a result of this board is thin, it typically kept the
instruments out of the way in which of the work.
my website – få 3 gode tilbud på tomrertilbud.dk
great publish, very informative. I ponder why the other specialists of this sector don’t notice this.
You should continue your writing. I am sure, you’ve
a great readers’ base already!
Informative article, totally աҺat I wanted to fіnd.
Howdy very nice blog!! Guy .. Beautiful .. Amazing ..
I will bookmark your web site and take the feeds additionally?
I am happy to seek out a lot of useful info
right here in the publish, we’d like work out extra techniques in this regard, thank you for
sharing. . . . . .
Thanks for one’s marvelous posting! I genuinely enjoyed reading it, you can be a great author.
I will make sure to bookmark your blog and will often come back in the foreseeable future.
I want to encourage you to definitely continue your
great job, have a nice evening!
Many nationwide suppliers have radically completely
different service quality of in different parts of the nation.
my weblog :: How to Get Cheap or Free Internet Access at Home,
tablematters.kosmoscentral.com,
Football fans who want a touch of this comic book glamour can look at Lamborghini Hire as a way of achieving this.
Many sites also allow you to post any missing, interesting photos you find of popular
celebrities. What do celebrities such as Kathy Griffin, David
Gest, Kenny Rogers, Jill Saward and others regret.
Unquestionably imagine that that you stated. Your favourite justification appeared to be at the net the easiest thing to take into account of.
I say to you, I definitely get annoyed while other people consider issues that they just do not
recognize about. You managed to hit the nail upon the top and outlined out the entire thing
with no need side-effects , folks can take a signal.
Will probably be again to get more. Thank you
‘Are people really searching online for my product or services’.
Two: Research different services – Assuming that you are
going to hire someone to do it for you, the next step is to research as many different services as possible.
Forgetting to write for an audience is one
of the biggest mistakes that bloggers make. This mode of advertisement was
faster than the earlier ones and reached more people but it had
its own limitations.
Visit my weblog dc seo (http://www.123Washingtondcseo.xyz/)
This leaves a black burn mark at the bottom of the caquelon that never disappears during the caquelon’s life.
If you will want for additional details on are obligated to pay an all in one
computer on the your bedroom,thereby be a resource box but you could
be capable of geting a beautiful, carved hardwood screen to learn more about put all around the front to understand more about aspect.
A thorough check of the seller should reveal if they auction legal merchandise and whether it’s authentic or not.
Feel free to visit my page … louis vuitton online
I truly love your site.. Excellent colors & theme.
Did you make this site yourself? Please reply back as I’m trying to create my own website and would love to find out where you got this from or just what
the theme is called. Kudos!
Feel free to visit my blog post :: click here to find out more –
tsmart.id.au,
Hi there! This blog post could not be written much better!
Reading through this post reminds me of my previous roommate!
He always kept preaching about this. I will send this post to him.
Pretty sure he’ll have a good read. I appreciate you
for sharing!
‘Are people really searching online for my product or services’.
Improving Site Structure – This second part tells you how to properly structure URLs.
Depending on how how much time you have you can do this about once per week.
Tests with a model like Page – Rank have shown that the system is not infallible.
Feel free to surf to my weblog; dc seo (http://allyberryphotography.com/)
Although Yahoo isn’t the biggest, or the highest ranking search engine on the internet, it is still
one of the most essential, and if you want use search
engine optimization and promotion as a main technique in your marketing arsenal,
you unquestionably need to get listed here. So what are
you going to put in their search box is “website optimization tips”.
But it is extremely important that anyone looking to hire an dc seo (dobroe-delo.info) professional be aware of the differences.
A guy named Alan Emtage, a student at the University of Mc – Gill, developed the first search engine for the Internet in 1990.
Many small companies prefer to hire SEO specialists as
consultants rather than full time employees, unless
they have a certain amount of websites that need to be continuously maintained and optimized.
The usual dc seo methods include keyword research, link building and such.
Thematic relevance is of key importance for the creation of quality backlinks.
There are two techniques that combine to form a complete SEO.
I was suggested this blog by my cousin. I’m not sure
whether this post is written by him as nobody else know such
detailed about my problem. You’re wonderful! Thanks!
Hello my loved one! I wish to say that this post is awesome, nice written and include
approximately all vital infos. I would like to see
more posts like this .
Feel free to surf to my web-site six star testosterone booster pills reviews (http://Intensedebate.com/people/blaketoney88725)
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an impatience over that you
wish be delivering the following. unwell unquestionably come further formerly
again since exactly the same nearly very often inside case you shield this
hike.
Do you mind if I quote a few of your articles as long as I
provide credit and sources back to your website?
My blog site is in the very same area of interest as yours and my users would really benefit from a lot of the information you
provide here. Please let me know if this
alright with you. Thanks!
The new Secret Gold guide reveals many tips and tricks that could be really
useful for those players who are struggling to make gold.
With this guide, things are much different; it contains detailed screen shots, and that makes learning
the secret techniques really easy. You can focus on just getting these by killing elementals,
mostly found in the instance “The Skywall” so if you are leveling, you should go
there at 83-85.
You need to use this Clash of Clans defend to create your properties up due to the fact it will not likely
final eternally.
Feel free to surf to my web page :: how to hack clash of clans android without computer (yui.saikyoh.jp)
What’s up to all, how is everything, I think every one is getting more from this web page, and your views are nice designed for new users.
What’s up colleagues, how is all, and what you wish
for to say concerning this paragraph, in my view its in fact remarkable in favor
of me.
I could not resist commenting. Very well written!
Quality posts is the key to interest the viewers
to pay a visit the web site, that’s what this website is providing.
Howdy! I know this is somewhat off topic but I was wondering which blog platform are you using
for this site? I’m getting tired of WordPress because I’ve had issues with hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of
a good platform.
Haave a friemd read drafts tto ogtain feedback oon thhe writing, andd gett ttheir thoughs under
considderation whuen makung neww drafts. Studentgs writig a disserrtation nesd too uutilize bith essenmtial aand
auxiliary sources, that thhe majlrity ffom thee studenrs aare noot
ablee too acquiee to. Butt youu shnould perrform ome home-work too fond ouut hhow satisfied oor disfruntled previus customers hsve beeen using tthe providers.
Feeel frree tto surf too myy blog – self publishing
En muchas ocasiones hemos creído que cuando charlamos de juguetes
eróticos hablaremos tan solo de consoladores, vibradores bolas chinas.
Excellent blog! Do you have any helpful hints for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress
or go for a paid option? There are so many choices out there that I’m completely overwhelmed ..
Any recommendations? Thanks!
Actually no matter if someone doesn’t know then its up to other users that they
will help, so here it happens.
You ought to be a part of a contest for one of the best blogs on the net.
I most certainly will recommend this web site!
Wow, marvelous blog layout! ᕼow long Һave үou beеn blogging fοr?
уօu made blogging loоk easy.
Tһе оverall lоok оf уоur web site іѕ
ցreat, ɑѕ ԝell ɑs
tһе сontent!
Mү web-site :: money making ideas
Hello There. I found your blog using msn. This is a really well written article.
I will make sure to bookmark it and return to
read more of your useful information. Thanks for the post.
I’ll definitely return.
What’s up i am kavin, its my first occasion to commenting anyplace, when i read this paragraph i thought i could
also make comment due to this sensible post.
Also visit my site – koray büyükasar
Hi, i think that i saw you visited my weblog thus i came to
“return the favor”.I’m trying to find things to improve my web site!I suppose its ok to use some
of your ideas!!
Soleil Moon Frye merely revealed her crafting startup, Moonfrye, which is focuseded on families.
My web blog delicious.com – Magnolia –
The startup supplies pre-packaged Kits that have been put together by popular developers on Pinterest.
Also visit my webpage; twitter.com [Kari]
Magnificent beat ! I would like to apprentice while you amend your website, how can i subscribe for a blog web site (Louvenia)?
The account aided me a acceptable deal. I had been tiny
bit acquainted of this your broadcast offered bright clear idea
Everything is very open with a precise clarification of
the challenges. It was truly informative. Your site is extremely helpful.
Many thanks for sharing!
Bu sonuçta şirket başlattı ve ABD’deki
görmesini sağladı bu koleksiyon oldu
My web blog; koray buyukasar tecavuz
Thiss is a opic that’s near to my heart… Take care!
Where are your contact details though?
my web site: http://debbyhanxu.bloggplatsen.sedebbyhanxu.bloggplatsen.Se
May I simply just say what a comfort to find somebody who genuinely understands what they are discussing
online. You certainly know how to bring an issue to light and make it important.
More and more people have to read this and understand this side of your story.
I was surprised that you’re not more popular because
you definitely have the gift.
Here is my web-site :: website; Lillian,
At this time it seems like WordPress is the best blogging platform available right now.
(from what I’ve read) Is that what you’re using on your blog?
Quality articles or reviews is the main to be a focus for
the people to visit the website, that’s what this
website is providing.
Here is my weblog :: web site (Everett)
This article is actually a fastidious one it helps new net
people, who are wishing in favor of blogging.
Finest for simple duties is the free service
, which allows you to hook up with an unlimited variety of computer systems from wherever on the earth.
Look into my weblog :: How to Get Cheap or Free Internet Access at Home
(marienstiftsbibliothek.de)
We’re a group of volunteers and opening a new scheme in our
community. Your website provided us with valuable information to work on. You’ve
done a formidable task and our whole group can be thankful to you.
Unquestionably believe that which you said. Your favorite justification appeared to be
on the net the simplest thing to be aware of. I say to you, I definitely get irked
while people consider worries that they just
do not know about. You managed to hit the nail upon the top
and defined out the whole thing without having side-effects , people can take a signal.
Will probably be back to get more. Thanks
Hi to all, how is the whole thing, I think every one is getting more from this web site, and your views are fastidious designed for new visitors.
For just $3.99. I’ll guide you thru cleansing and organizing every room, every closet, and each
cupboard in your own home.
Feel free to visit my webpage – rengøringshjælp tilbud
In Canada we had a recent informatiion story where Canadrian inmatees are getting cash from how to make money on the internet for free in canada taxpayer’s as tney sit in prison from
sure GST Funds, aand different Social Security packages.
You may have heard the term affiliate program, buut what
exactly does it imply?
Here is my web page :: extra income
Normally a corset may be the best-known to a sheet of the
particular sexy underwear that only comes out
within the bed room, it could be found in various delicate components the same as silk,
wide lace, and silk, even in Faux wood and leather in a few
intense cases. “When I was first diagnosed, I knew pretty much nothing about breast cancer — except that I didn’t want it. As an illustration when you are attempting to find a purse that you would carry on the shorter journey, you would like to frequently research for that durable, spacious kinds.
Feel free to surf to my webpage :: michael kors canada
I simply could not go away your web site
before suggesting that I really enjoyed the usual info an individual provide in your guests?
Is going to be again steadily to investigate cross-check new posts https://www.reddit.com/3qgxx2/
whoah this weblog is fantastic i love reading your posts.
Stay up the good work! You already know, lots
of persons are looking round for this info, you can help them greatly.
When taking any medicine for addiction or any other issue,
it is important to take only the amount recommended.
hello!,I love your writing so much! proportion we be in contact more about your article on AOL?
I need a specialist on this area to solve
my problem. May be that’s you! Having a look forward
to peer you. https://www.reddit.com/3qh3qf/
It’s remarkable to go to see this website and reading the views
of all colleagues concerning this article, while I am also eager of getting experience.
Stop by my weblog – geleviz.com (Julio)
If some one desires to be updated with most up-to-date technologies afterward he
must be pay a quick visit this website and be up to
date all the time.
You can definitely see your skills within the work you write.
The sector hopes for more passionate writers such as you who are
not afraid to say how they believe. All the time go after
your heart.
For most up-to-date news you have to visit the web and on world-wide-web I found this site as a finest web site for
latest updates.
I am actually happy to read this website posts which includes lots of helpful information, thanks for providing
such information.
More customers choose the custom-fit whitening kit to always be their favorite.
These consist of a boil-and-bite, a short-term tray that you can use for the meantime while waiting the custom-fit
rack. But bear in mind not to make use of the short-term
one for lengthy. Along with maybe receiving a jagged consequence,
the boil-and-bites will receive awkward if put to
use for quite a few years. This could bring around 3 period once you’ve delivered
your smile perceptions to the research.
This custom-fit plate is completely essential to the entire whitening system.
This product helps you to have the whitening gel solidly
and uniformly to each and every area of the teeth, making certain uniform bleaching
everywhere in. This is exactly what they label “full curing.”
Here is a tip, nevertheless. Attempt having your custom-fit plate
at an on-site tooth lab as opposed to from the dentist’s workplace.
They will certainly become so much less costly, but operate just as
well.
To find out a lot more about at home teeth whitening go visit the site:
teeth whitening greensboro nc
And the other quality night we registered right here and observed Teeth Whitening Kit and therefore also
at a rather cost-effective costs. After browsing most of the testimonies and critiques I imagined of creating an attempt thereafter we bought my personal
trial offer package. After checking out this whitening
product I managed to get straight back your whiter mouth
which enhanced my favorite self-confidence, and allowed
me to laugh more and show up more enjoyable and out-going.
My friends also discovered the advance after a very few instances.
Currently i’m like smiling all the time that is way
too without the doubt and anxiety about featuring our smile.
I’m hence safe right now.
You simply need to turn teeth whitening applicator in order to apply one’s teeth whitening gel, therefore the utilize
this teeth whitener gel towards your mouth, and wait a minute for the active ingredients taking effect.
This remarkable dental lightening method takes simply couple of minutes to make use of and mere seconds
to provide you with that perfect smile you’ve always wish.
This particularly made solution quickly eliminates area stains
and penetrates deeper to remove embedded stains.It is effective
on marks triggered by coffee drinks, tea, cigarette, wine etc.
After you’ve revealed the unit that better works in your favor, make
the time to often engage in great dental health behaviors.
Brush and floss your smile all after food, and your own dentist routinely
for a skilled cleansing which is able to scour perhaps
even the greatest recesses of the gum tissue. All things considered, this is actually the heart and soul
of accurate cosmetics: it all about precisely what consist below.
For the following six months time I attempted all the different
tooth pastes in the market with no visible results.
We actually looked at getting my favorite your teeth whiten right up by the dental
expert but i really could certainly not pay the expensive
rates my favorite dentist was asking.I even looked into cosmetic dental care
to bleach our smile, but the costs were huge. After experiencing most of the possible techniques we considered the web.
Right here i ran across learn to get white teeth when you do
a little research to the teeth whitening procedure.
On the internet I attempted discover some low-cost sales.
We spent days researching to be able to get gleaming white teeth using
no-cost types of the products, and all it price would be a few
bucks for freight.
Very good blog post. I absolutely love this website. Keep
writing!
If you wish for to get a good deal from this piece of writing then you have to apply such methods to your won web site.
Here is my web page – workout supplement – http://www.viruswarn.com –
Hey there just wanted to give you a brief heads up and let you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve tried
it in two different internet browsers and both show the
same outcome.
My web page … homepage (Gerald)
Hi outstanding blog! Does running a blog similar
to this require a large amount of work? I’ve virtually no knowledge of
computer programming but I had been hoping to start
my own blog soon. Anyways, should you have any recommendations or tips for new
blog owners please share. I know this is off topic
but I just needed to ask. Cheers!
My web site; webpage (Fermin)
I think the admin of this website is actually working hard in favor of his website, because here every information is quality based data.
my blog: homepage, Thalia,
I’m now not sure where you’re getting your information, however good topic.
I must spend some time learning much more or working out more.
Thank you for great information I was looking for this info for my
mission.
When some one searches for his required thing,
thus he/she wishes to be available that in detail, therefore that thing
is maintained over here.
Also visit my homepage webpage (Sandy)
We stumbled over here coming from a different page and thought I might
check things out. I like what I see so now i’m following
you. Look forward to checking out your web page for a second time.
Greate post. Keep writing such kind of info on your blog.
Im really impressed by it.
Hey there, You’ve performed a fantastic job.
I will certainly digg it and for my part suggest to my friends.
I’m confident they will be benefited from this website.
Feel free to visit my web blog; web page [Geneva]
At first glance, a two minute cooldown ability may seem
too long to make the Crocolisk a worthwhile tank.
Anyway, that’s where the Forex Ambush became a concern –
when reading their website and seeing what it does.
Description: A casual third-person shooting game with changeable weapons during battle.
my webpage: fast and furious 7 2015 full movie
Arcadia Phu Quoc Resort có bãi biển riêng đầy cát dài 100 m với khăn tắm, dù che và
ghế tắm nắng miễn phí.
Keep on writing, great job!
Despite their modern way of living, they were both basically “old-fashioned” in some ways too.
The beauty of these movies is that they tend to bring out the best in everyone too.
Aladdin is the main character of the movie and he wins over Princess Jasmine by pretending he is a prince when he is
really a pauper.
My weblog :: cinderella movie online (cinderellamovie.ml)
Pretty nice post. I just stumbled upon your weblog and wanted to say that
I have really enjoyed surfing around your blog posts.
After all I’ll be subscribing to your rss feed and I hope you write again soon!
“What we’ve said very clearly is that we accept the principle of the licence fee, the idea of a household tax to fund broadcasting that is ring-fenced,” the culture
secretary Jeremy Hunt said on the Andrew Marr Show on the BBC.
Livefootballol: Free Live Football Streaming and Highlights
watch free live football streaming, live football from EPL,
Serie A, Bundesliga, La Liga on. Today is a sad day for all fans of
live sports streaming, as we at Wiziwig have to.
In the case of the characters mentioned above, there is evidence to prove that they tried to escape this misery using migration to city life as
the most plausible option at the time. Emma Watson has
revealed to the media that she hasn’t been approached for the role nor has she read the script, despite
the countless rumors on the Internet about her involvement in the movie, but that doesn’t mean the Harry Potter starlet is
out of the running. The book was an international phenomenon, but the movie trailer does not provoke any degree of intrigue or curiosity at
all.
Here is my website :: fifty shades of grey online
Hi, i read your blog occasionally and i own a similar one and i
was just wondering if you get a lot of spam feedback?
If so how do you stop it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any support is very
much appreciated.
After I originally left a comment I appear to have clicked the -Notify me when new comments are added- checkbox and now every time
a comment is added I recieve 4 emails with the exact same comment.
Perhaps there is a way you are able to remove me from that service?
Thank you!
Wow, this paragraph is nice, my younger sister is analyzing these kinds of things, therefore I
am going to let know her.
– Diego Armando Maradona – He won the world cup in 1986
and became most popular for his two goals against England in the quarter finals.
Monaco gave a counter class how to let the brink
of elimination to Arsenal, who could do nothing to the French team in the knockout round.
Today is a sad day for all fans of live sports streaming,
as we at Wiziwig have to.
Hello There. I discovered your weblog using msn. This is a really well written article.
I will make sure to bookmark it and come back to read extra
of your helpful information. Thank you for the post.
I’ll definitely return.
After jilted mistress Ya – Vaughnie Wilkins commissioned huge billboards of herself and her married lover to
appear in 3 major cities across the United States.
With the countdown to 2011 looming large, just a fortnight away, Floyd Joy Mayweather Jr.
Does she keep voice mails, photo, text messages, e-mails,
love notes, videos, receipts, or other mementos of the affair, that could surface
when you lest expect, and cause you untold embarrassment.
Take a look at my homepage; criminal case walkthrough (Brandi)
I like the concept of Pippity specifically because I use CTCT in conjunction with WordPress.
my website: email marketing services pricing
I all the time used to read paragraph in news papers but now as I am a user of web thus from now I
am using net for content, thanks to web.
Visit my webpage hermes outlet online
Please let me know if you’re looking for a article
author for your weblog. You have some really great
posts and I think I would be a good asset. If you ever want to take some
of the load off, I’d love to write some material for your blog
in exchange for a link back to mine. Please shoot me an e-mail if interested.
Thanks!
Hello, I think your website might be having browser compatibility issues.
When I look at your blog site in Ie, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, great blog!
My page – Lisa
There is another section and that is the ticket section, and
under this section, there are sub categories like club seats, premium suites, season tickets, individual
games, info requests and seating chart. Manchester United v Newcastle United: match preview.
Football matches when seen live on watch
live TV online seem fantastic.
‘Are people really searching online for my product or services’.
So what are you going to put in their search box is “website optimization tips”.
Auro – IN has a strong team that is built on the delivery of outstanding campaign results, customer
service and appreciation, and high levels of technical capabilities and values.
In this way, it is informed about the kind of information that a surfer
is looking for.
Feel free to visit my page hvac frederick md (http://www.123frederickmdhvac.xyz)
I really like your blog.. very nice colors & theme. Did
you create this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to design my own blog and would like to find out
where u got this from. thanks a lot
whoah this blog is excellent i like reading your articles.
Stay up the great work! You realize, a lot of people
are searching round for this information, you could aid them greatly.
The research has already establish the fact that partial or full reversal of diabetes is possible by
eliminating its root cause.
Does your site have a contact page? I’m having a tough time locating it but, I’d like to send you an e-mail.
I’ve got some ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it expand over
time.
My brother recommended I might like this web site.
He was entirely right. Thiss post actually made my day. You can not imagine just how much time
I had spent for this info! Thanks!
Do you mind if I quote a couple of your posts as
long as I provide credit and sources back to your weblog?
My website is in the very same area of interest as yours and
my visitors would really benefit from some of the information you present here.
Please let me know if this okay with you. Thanks a lot!
With this I can recommend your PC to be installed today.
Here is wherever the look at film internet based web pages began to
score. Football matches when seen live on watch live TV
online seem fantastic.
I’m impressed, I must say. Rarely do I come across a blog
that’s equally educative and entertaining, and without
a doubt, you have hit the nail on the head.
The problem is something that not enough folks are speaking
intelligently about. I’m very happy that I stumbled across this during my hunt for something relating to this.
“What we’ve said very clearly is that we accept the principle of the licence fee, the idea of a household tax to fund broadcasting that is ring-fenced,” the
culture secretary Jeremy Hunt said on the Andrew Marr Show on the BBC.
With only one goal against a major nation, and
that being in an international friendly against Netherlands, questions remain over Defoe’s pedigree on the biggest
of stages. If that device is plugged into the mains electricity then the premises must have a licence or the viewer
is committing an offence, the TV Licensing Authority has previously said.
Get her some romantic gifts that can make her
day memorable.
I eᴠery time emаilеɗ tɦіѕ bⅼоց
ρоst раge tⲟ aⅼⅼ mʏ cοntactѕ, ƅᥱcauѕе іf lіке tⲟ reaɗ іt neⲭt mʏ lіnkѕ ԝіll tоо.
Very descriptive article, I loved that bit. Will there be a part 2?
Be taught exstra abut easy waay to make money on the internet
fast (Rebecca)
marketing success and effective online marketing ideas.
My family all the time say that I am killing my time here at net, except I know I am getting familiarity every day by reading such good posts.
Also visit my website; homepage; Latonya,
Hi there, I log on to your new stuff on a regular basis.
Your story-telling style is witty, keep doing what you’re
doing!
Take a look at my web blog :: giuseppe zanotti men
If for some explanation this does not function for you,
you will be given ideas of what other things you
can use to get free instagram followers.
Also visit my blog post :: free instagram followers moviestarplanet hack tool
Hi there i am kavin, its my first time to commenting anywhere, when i read this post i thought
i could also make comment due to this good article.
I really like what you guys tend to be up too. Such clever work and coverage!
Keep up the terrific works guys I’ve added you guys to our blogroll.
Greetings! I know this is somewhat off topic but I was wondering
which blog platform are you using for this site? I’m
getting tired of WordPress because I’ve had problems with
hackers and I’m looking at options for another platform.
I would be fantastic if you could point me in the direction of a good
platform.
I know this web site provides quality dependent articles
or reviews and extra information, is there any other web site which offers these things in quality?
Hi, always i used to check blog posts here in the early hours in the
break of day, because i love to gain knowledge of more and more.
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s difficult
to get that “perfect balance” between usability
and visual appearance. I must say that you’ve done a very
good job with this. In addition, the blog loads super quick for me on Opera.
Outstanding Blog!
After looking at a few of the articles on yoyr web site, I
truly like your technique of blogging. I book-marked it to my
bookmark website list and wijll be checking back in the near
future. Please check out my web site too and let me know your opinion.
I just like the valuable information you supply to your articles.
I’ll bookmark your weblog and check again right here frequently.
I am moderately sure I’ll be informed a lot of new stuff right right
here! Best of luck for the following!
I’m truly enjoying the design and layout of your site.
It’s a very easy on the eyes whkch makes it much more pleasant for
me to come here and visit more often. Did you hire out a developer to reate your theme?
Superb work!
Feel ree to surf to my website – watch online
I am curious to find out what blog platform you have been utilizing?
I’m having some minor security problems with my latest site and I would like to find
something more safe. Do you have any solutions?
Visit my webpage: prada bags outlet
Great blog you have here but I was curious if you knew of any
discussion boards that cover the same topics discussed here?
I’d really like to be a part of group where I
can get suggestions from other knowledgeable people
that share the same interest. If you have any recommendations, please let me
know. Many thanks!
This will help protect her privacy and increase her safety.
The Hardcore gamers are the ones that dedicate an EXTREME amount
of time to master the game, get the best gear, and overall.
Upon its release, do you think Serf Wars will retain its audience.
Hello! I just want to give you a big thumbs up for your excellent information you have here on this post.
I will be coming back to your blog for more soon.
Hey There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and come back to read more of your useful info.
Thanks for the post. I will definitely return.
my website … Global Profits
Hey! I’m at work surfing around your blog from my new iphone!
Just wanted to say I love reading your blog
and look forward to all your posts! Carry on the
great work!
These are in fact great ideas in concerning blogging.
You have touched some good things here. Any way keep up wrinting.
Valuable info. Fortunate me I found your web site accidentally, and I’m stunned why this accident did not happened in advance!
I bookmarked it.
Feel free to surf to my web-site – Algo Drive Robot
I am truly pleased to glance at this webpage posts which
includes lots of helpful data, thanks for providing such statistics.
Thomas JC, Moore A, Qualls PE: The effect on cost of medical care for patients treated
with an automated clinical audit system.
All rights booked. This product could not be released, program, rewritten, or redistributed.
Also visit my site: evernote.com; Melva,
Terrific article! This is the kind of info that are supposed to
be shared across the internet. Shame on Google for not positioning this put up upper!
Come on over and consult with my website . Thanks =)
You are so awesome! I don’t think I’ve read through anything like that before.
So good to find somebody with some original thoughts on this
topic. Seriously.. many thanks for starting this up. This web site is one thing that is
required on the internet, someone with a little originality!
Feel free to surf to my blog post: Daryl
bring to the table a dimensions range having to do with by the
way and designs that cater to explore the individual’s clientele’s varying tastes and preferences Aside
back and forth from his or her a modification of your handbag anyway
Coach handbags are also a good deal more accessible it affordable to understand
more about users Approximately 300 hundred stores across going
to be the United carry the item brand name. Rodeo Drive, which is one of the most famous luxury shopping areas in the country, is close to West Hollywood which
recently approved a new city ordinance which bans the
sale of fur related products in the city. Hobo bags are an all in one more or less any having to do
with handbag it have an all in one distinctive crescent shape.
Have a look at my blog post: prada bags outlet
Steady Guard ® by XFINITY offers unmatched on the internet safety
and security so you could safely delight in the fastest, most dependable Net
at no added price.
Hi! I know this is somewhat off-topic but I had to ask. Does building a well-established blog such
as yours require a lot of work? I am completely new to
blogging however I do write in my diary every day.
I’d like to start a blog so I can easily share my experience and thoughts online.
Please let me know if you have any recommendations
or tips for new aspiring bloggers. Thankyou!
(An E” rating signifies that a game is appropriate for all age range; M” titles contain mature content”—blood, gore, sexual situations.
If you have a potent promoting device, you can acquire a big amount of Instagram
followers for your business.
Here is my weblog free instagram followers hack no surveys
I do suppose another affiliate marketing for dummies free (Diana) programs
pay better for the effort howver atleast Amazon is a legit
company.
Hey there! I know this is kind of off topic but I was wondering if you knew where I could get a captcha plugin for
my comment form? I’m using the same blog platform as
yours and I’m having trouble finding one? Thanks a lot!
Firstly, you should be aware of which ones to avoid.
These would be the non-prescription gels and light/heat treatment options from your dental practitioner.
Let us accomplish the gels very first. Over-the-counter gels
take many, many years to be effective. It may take up to
fourteen days in order for you to definitely get the
level of lightening you wish. Even if you are certainly not in a hurry,
precisely why do you really delay if you possibly could have
got causes a much shorter time period? Additionally, many
people whine they are simply not extremely effective and
were discontented by employing the outcomes.
Next, we are going to discuss the beam illumination procedures that you can get at a dental professional’s workplace.
Many patients claim serious suffering and sensitiveness as soon as the technique, even to
the stage they have hardships taking in solid foods.
Although beam illumination remedies are extremely effective, it sometimes could be as well successful.
Some individuals end up getting eerie-looking, unnaturally white teeth.
They complain they are often teased about their teeth are too blinding.
Finally, this technique is pretty expensive. The whole thing can run-up to $600, not many individuals are able to
afford to invest a small fortune on the physical appearance.
To understand more info on teeth whitening buffalo ny take a look at
the page: at home teeth whitening
Certainly not usually accurate! Professional Teeth Whitening product providers mostly utilize peroxide or Carbamide Peroxide
as the ingredients within their tooth whitener ties in. The chemical Hydrogen Peroxide (HO) is actually
a bleaching rep which converts into liquid (HO) and releases an Oxygen unit (O) during the process with the substance reaction. Both Waters and air are
routine, safer elements of our day to day resides.
The air fibers infiltrate the difficult surface of the enamel (despite the reality
they look smooth, they truly are microscopically rough, rod like crystal clear systems) and dislodge discoloration particles.
I love to make clear this by picturing the television commercials
which program precisely a clothes washing product with oxygen pulls spots because of your apparel.
Acid production can take out enamel from your tooth. Seek out whitening products using
Hydrogen Peroxide which will be pH equal, which means
obtained no, or reasonable acidity values.
Getting acidity into views, you should be aware that day-to-day Orange Juice is definitely displayed in lab learning to smoothen down (and possibly
deteriorate) tooth enamel by many period
well over a certified hydrogen peroxide based mostly on dental brightening serum could, if used precisely.
And the other quality morning I entered here and saw Teeth Whitening gear and that also too at an extremely economical terms.
After experiencing every one of the recommendations and critiques I was thinking of creating an attempt thereafter I ordered
my own free trial offer group. After trying out this teeth bleaching product I got down my brighter your teeth which enhanced simple esteem, and let us
to laugh much more seem even more enjoyable and out-going.
My pals also noticed the advance after a few time. Now personally i think
like smiling all the time that is too without any hesitation and anxiety about displaying your tooth.
I’m therefore comfortable right now.
You only need to pose the teeth whitening applicator to apply the teeth whitening gel, along with the use this teeth whitener gel towards your
dental, and hold off a minute for your substances to consider
effects. This miraculous enamel whitening method produces simply few minutes to use and moments to offer ideal look you really have always desired.
This particularly made solution rapidly eliminates surface discolorations and penetrates deeper to remove inserted stains.It works
great on stain a result of espresso, teas, smoke, red wine etcetera.
I always emailed this weblog post page to all my friends, since if
like to read it after that my friends will too.
The water platform hass numerous virtues.
Check out my blog flat stomach exercises after c section –
Rene,
http://artikelq.com
Hi, I think your site might be having browser compatibility issues.
When I look at your blog site in Opera, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, superb blog!
(Mike Corak in Integrated content email marketing services
free (Dawna) and the client knowledge ).
Hi there, after reading this amazing article
i am too cheerful to share my knowledge here with colleagues.
Amazing! Its really amazing paragraph, I have got much clear idea
on the topic of from this paragraph.
Excellent way of describing, and pleasant paragraph to take data concerning my presentation subject, which i am going
to present in school.
The storyline of Boom Beach is in the tropical archipelago where the player is on a island with defences and troops.
Hello colleagues, how is all, and what you desire to say concerning this article, in my view its in fact
amazing in support of me.
It’s hard to tell if the right hip is hiking, the femur is rotating, or the pelvis and/or lumbar spine is rotating… or some combination of the three.
You can definitely see your expertise in the work you
write. The world hopes for even more passionate writers such as you who aren’t afraid
to mention how they believe. At all times follow your heart.
This post offers clear idea in favor of the new people of blogging, that truly how to do blogging.
my page brain exercises to improve Memory
I blog often and I really thank you for your information. The article has really peaked my interest.
I will take a note of your site and keep checking for new information about once a week.
I opted in for your RSS feed as well.
My webpage: Greyhound Dog All Big Dog Breeds
(Tom)
After looking over a number of the blog articles on your blog,
I truly appreciate your technique of writing a blog.
I added it to my bookmark site list and will be checking back in the near future.
Take a look at my website too and let me know your opinion.
Here is my webpage; workout supplements (sibdt.ru)
Different facets of FreedomPop’s service are hidden from prospective prospects
as nicely.
Also visit my site :: How Do I Choose the Best Internet Service Provider?
– transmyt.net –
On this case, thhe most effective desiogned lamp will requikre patrons
to spend extra make money online fast and free (Allie)
thuan regular lamps do. When you’ve got the tight finances, the next guideline is the most effective
reference for you to know extra abut distinctive lighting concept.
Hi, i think that i saw you visited my web site thus i came to go back the
choose?.I’m attempting to in finding issues
to enhance my web site!I suppose its adequate to make use of a few of your
ideas!!
Give the gift that keeps on giving, at least when it comes
to battery power with the go lite 2. But if you got your iphone
for more than 30 days, you won’t be able to avail of
the Apple – Care Protection Plan. Press and hold any app icon until
all icons begin to shake on the screen.
Also visit my website :: coque iphone 5s
I just like the valuable information you supply in your articles.
I will bookmark your weblog and check again here frequently.
I am somewhat certain I’ll be told plenty of new stuff right right here!
Good luck for the following!
Good day! Would you mind if I share your blog with my myspace group?
There’s a lot of people that I think would
really appreciate your content. Please let me know.
Many thanks
Hi, I do think this is a great website. I stumbledupon it
😉 I may revisit once again since I bookmarked it. Money and
freedom is the best way to change, may you be rich and continue to
guide others.
affiliate marketing for dummies download marketing online,
or, promoting own merchandise, or, selling promoting areazs like Adsense…you must knhow one method to turn into profitable- traffic generation.
Fantastic beat ! I would like to apprentice whilst you amend your site, how can i subscribe for a weblog site?
The account aided me a applicable deal. I were tiny bit acquainted of this your broadcast offered vibrant
transparent idea
Look at my blog: traffic ticket miami gardens – Tanja,
‘Are people really searching online for my product or
services’. The trends in this industry change and new developments take place only when Google comes up with some novel feature that ends
up breaking every site’s SEO and compels them to consider a change in their current content presentation in order to do well.
But in general here are the services that an online business owner should expect from
SEO experts and other agencies and consultants:. This mode
of advertisement was faster than the earlier ones and reached
more people but it had its own limitations.
My blog frederick md hvac (purevolume.com)
Me pueden ayudar en una cosilla? Alguien sabe
decir algunos trucos para ahorrar un poco de dinero a la hora
de contratar un catering para celebraciones?
Quality posts is the secret to attract the visitors to
go to see the web page, that’s what this web page is providing.
Your style is very unique in comparison to other
people I have read stuff from. Many thanks for posting when you have
the opportunity, Guess I will just bookmark this site.
Generally I don’t read article on blogs, but I
would like to say that this write-up very pressured me to
take a look at and do so! Your writing style has been amazed me.
Thank you, quite nice article.
Your style is unique in comparison to other folks
I’ve read stuff from. I appreciate you for posting when you’ve
got the opportunity, Guess I’ll just bookmark this blog.
Hi just wanted to give you a brief heads up and let you
know a few of the images aren’t loading properly. I’m not sure why
but I think its a linking issue. I’ve tried it in two different internet browsers
and both show the same outcome.
Hello there! I know this is kinda off topic
however , I’d figured I’d ask. Would you be interested in exchanging links
or maybe guest writing a blog post or vice-versa?
My website addresses a lot of the same subjects as yours and I believe we could greatly benefit from each
other. If you happen to be interested feel free to shoot me an email.
I look forward to hearing from you! Superb blog by the
way!
Quality articles or reviews is the important to interest the people to go to
see the web site, that’s what this web site is providing.
Howdy! I’m at work surfing around your blog from my new iphone 4!
Just wanted to say I love reading through your blog and
look forward to all your posts! Carry on the
great work!
The Pixel Gun 3D Hack Software work for Android and iOS which you select before utilizing the hack.
Pretty! This has been an extremely wonderful post.
Thank you for supplying this info.
Hi there, every time i used to check weblog posts here in the early
hours in the daylight, since i love to learn more and more.
Oh my goodness! Impressive article dude! Thank
you, However I am encountering difficulties with your
RSS. I don’t know the reason why I cannot join it. Is there anybody else getting identical RSS problems?
Anyone that knows the answer will you kindly respond? Thanks!!
It’s actually a great and useful piece of information. I’m glad that you simply shared this helpful info with us.
Please stay us informed like this. Thanks for sharing.
Hi there colleagues, how is the whole thing, and what you want to say about this article, in my view its truly
amazing in favor of me.
Hi, yeah this post is truly nice and I have learned lot
of things from it regarding blogging. thanks.
Howdy! Would you mind if I share your blog with my zynga group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Many thanks
Thank you for the good writeup. It in fact was once a enjoyment account it.
Look complicated to more brought agreeable from you!
However, how can we keep up a correspondence?
I just could not go away your website prior to suggesting that I extremely loved the usual info a person provide
on your guests? Is going to be again continuously to check up on new posts
I do consider all of the concepts you have offered in your
post. They’re very convincing and will definitely work.
Nonetheless, the posts are too short for starters. May just you please prolong them a
bit from next time? Thank you for the post.
My programmer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on numerous websites for about a year and
am concerned about switching to another platform. I have heard
good things about blogengine.net. Is there
a way I can transfer all my wordpress content into it?
Any kind of help would be really appreciated!
It’s amazing to pay a visit this web page and reading the views
of all mates on the topic of this article, while I
am also eager of getting familiarity.
Keep on writing, great job!
Hmm is anyone else experiencing problems with the pictures
on this blog loading? I’m trying to determine if
its a problem on my end or if it’s the blog. Any feed-back would be greatly appreciated.
An interesting discussion is worth comment. I do
believe that you ought to write more on this subject, it might not be a taboo matter
but generally folks don’t discuss these subjects. To the next!
Best wishes!!
Magnificent goods from you, man. I’ve understand your stuff previous to and you are just
extremely magnificent. I really like what you’ve acquired here,
certainly like what you are saying and the way in which you say it.
You make it enjoyable and you still take care of to keep it smart.
I can’t wait to read much more from you. This
is really a terrific site.
I’ll right away seize your rss as I can not to find your e-mail subscription hyperlink or newsletter service.
Do you have any? Kindly let me understand in order that I may subscribe.
Thanks.
I read this paragraph fully about the difference of most recent and earlier technologies,
it’s amazing article.
Keep on working, great job!
Greetings I am so happy I found your site, I really found you by error, while
I was searching on Digg for something else, Nonetheless I am here now and would
just like to say thank you for a marvelous post and a all round entertaining
blog (I also love the theme/design), I don’t have time to read it all at the moment but I have book-marked it
and also included your RSS feeds, so when I have time I will be back to
read a lot more, Please do keep up the superb work.
Great information. Lucky me I found your site by accident (stumbleupon).
I’ve bookmarked it for later!
Hello everyone, it’s my first go to see at this website,
and piece of writing is in fact fruitful designed for me, keep up posting these articles.
I have read some just right stuff here. Certainly worth bookmarking for revisiting.
I surprise how much effort you set to make this sort of magnificent informative website.
Wow, this article is fastidious, my sister is analyzing these things, therefore
I am going to let know her.
Having read this I thought it was extremely informative. I appreciate you spending some time and
energy to put this article together. I once again find myself
spending a lot of time both reading and posting comments.
But so what, it was still worthwhile!
Hi, Neat post. There’s a problem along with your website in web
explorer, could test this? IE nonetheless is the market leader and a big component of people will leave out your fantastic writing because of this problem.
This web site definitely has all the information and facts I needed about this subject and didn’t
know who to ask.
Very good info. Lucky me I came across your website by
accident (stumbleupon). I’ve saved as a favorite for later!
After I get by means of all the laundry and cleansing the kitchen after cooking and serving to 3 kids.
My web page rengøring privat
I truly love your blog.. Excellent colors & theme.
Did you develop this site yourself? Please
reply back as I’m wanting to create my very own blog and want to know where you
got this from or just what the theme is named.
Cheers!
What’s Going down i’m new to this, I stumbled upon this I’ve discovered
It positively helpful and it has aided me out loads.
I am hoping to give a contribution & help different customers like its aided me.
Good job.
Definitely imagine that that you stated. Your favorite justification appeared to be on the internet the simplest thing to be mindful of.
I say to you, I definitely get irked at the same time
as other folks consider concerns that they plainly do not
understand about. You controlled to hit the nail upon the
highest as well as defined out the entire thing without
having side effect , other folks could take a signal.
Will probably be again to get more. Thank you
Howdy! This post couldn’t be written any better!
Reading through this post reminds me of my good old room
mate! He always kept talking about this. I will forward this write-up to him.
Pretty sure he will have a good read. Many thanks for
sharing!
Check out my blog Amazing Places In Ivory Coast Great Amazing Place
Thanks for finally writing about > JavaScript Exercise –
Social Software < Liked it!
What’s up to all, the contents present at this site are truly amazing for people
experience, well, keep up the nice work fellows.
It’s a shame you don’t have a donate button! I’d definitely donate to this brilliant blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to brand new updates and will share this site with my Facebook group.
Talk soon!
Greetings! This is my first visit to your blog!
We are a collection of volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You
have done a wonderful job!
It’s going to be finish of mine day, however before ending I am reading this wonderful
paragraph to improve my knowledge.
Hey! Would you mind if I share your blog with my myspace group?
There’s a lot of folks that I think would really
appreciate your content. Please let me know.
Many thanks
In fact no matter if someone doesn’t understand after that its
up to other users that they will help, so here it happens.
whoah this blog is wonderful i love reading your posts.
Keep up the great work! You already know, lots of people
are looking around for this information, you can help them greatly.
Attractive component to content. I simply stumbled upon your blog and in accession capital to say that I get in fact enjoyed account your
weblog posts. Anyway I’ll be subscribing to your augment and even I achievement you get admission to consistently quickly.
Never give the details of your bank card having not happy yourself that the packages you might
be becoming a member off are respectable.
Feel free to surf to my site … affiliate marketing websites usa
I like the helpful information you provide in your articles.
I’ll bookmark your weblog and check again here frequently.
I am quite sure I’ll learn plenty of new stuff right here!
Best of luck for the next!
Very quickly this web page will be famous amid all blogging and site-building users, due to
it’s good articles
Tere is definately a lot to find out about this issue.
I really like all the points you have made.
Good article! We will be linking to this particularly great article on our website.
Keep up the great writing.
There are plenty of individuals who took a hobby that they loved
and turned it into a successful business.
Products with this designation have been found to reduce greenhouse gas emissions and other
harmful substances that result from inefficient energy use, and offer the same performance and features of conventional products.
The first thing that you might want to think about is using home improvement catalogs to help you out.
Also visit my web-site :: شركة مكافحة حشرات بالرياض
Yes! Finally someone writes about natural weight.
Appreciate the recommendation. Will try it out.
We are a group of volunteers and opening a new scheme in our community.
Your website offered us with valuable info to work on.
You have done an impressive job and our whole community will be thankful to you.
t it benefit you if your website was able to bring you new leads or develop new customers every day, 24 hours per day.
To optimize your small business web-site for Google or Yahoo and so
on, a great start out is necessitated, which is ensured
by getting natural Search engine optimisation providers.
Off-Page Optimization: This is a method of optimizing a website where optimization is done outside the website.
I enjoy looking through an article that can make people think.
Also, thanks for permitting me to comment!
Affiliate internet marketing is widespread nowadays and
the individuals do use it to generate income.
Review my homepage – online money earning
” and Frogger” are realizing that videogames avoid necessarily have to drive a sand iron between generations.
Thanks for one’s marvelous posting! I definitely
enjoyed reading it, you can be a great author. I will
remember to bookmark your blog and will eventually come
back later in life. I want to encourage you to definitely continue your great work, have a nice holiday
weekend!
my web site … sbobet wap asia
Right away I am going to do my breakfast, after having my breakfast coming over again to read
more news.
Simply desire to say your article is as amazing. The clarity to your post is just
excellent and that i could think you are an expert in this subject.
Fine along with your permission allow me to take hold of your
RSS feed to keep updated with approaching post.
Thank you 1,000,000 and please continue the rewarding work.
You don’t realise that the keepers pretty much can’t save low shots until you’ve conceded
a dozen goals in the bottom corner.
Hmm it appears like your blog ate my first comment (it was super
long) so I guess I’ll just sum it up what I submitted
and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog writer but
I’m still new to everything. Do you have any helpful hints
for newbie blog writers? I’d certainly appreciate it.
Hi there, I discovered your web site via Google whilst looking for a similar
subject, your web site got here up, it seems to
be good. I’ve bookmarked it in my google bookmarks.
Hello there, just was aware of your weblog via Google, and located that it’s really informative.
I am going to watch out for brussels. I’ll appreciate if you happen to proceed this in future.
Lots of other people might be benefited out of your writing.
Cheers!
Every weekend i used to pay a quick visit this site, for the reason that i want enjoyment, for the reason that this this site conations really fastidious funny data too.
Phú Vân Resort & Thẩm mĩ viện – Phú Vân Resort & Spa Phú Quốc có được những bungalow nép mình dưới bóng cây cọ xanh mát.
I was recommended this blog through my cousin. I
am no longer certain whether this put up is written by means of
him as nobody else understand such particular about my trouble.
You are amazing! Thank you!
Finding the latest updates about celebrities and exploring
life-style websites have becomke day-to-day activities of many
Web shoppers.
My page; internet marketing inc glassdoor (Cheri)
Good day! Do you know if they make any plugins to safeguard
against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Pretty nice post. I just stumbled upon your weblog and wished to
say that I have really enjoyed browsing your blog posts.
After all I’ll be subscribing to your feed and
I hope you write again soon!
I was more than happy to discover this website. I wanted to thank you for your time
just for this wonderful read!! I definitely appreciated every bit
of it and I have you book marked to see new stuff in your site.
Everything is very open with a precise explanation of the challenges.
It was definitely informative. Your site is extremely helpful.
Thanks for sharing!
Like any business that is offering services
for its customers, they have to insure they own revenue and the perpetuation and development of the business in the future.
Apart from poker rules and poker strategies, you
should also gain some idea about poker tips. Just when you thought playing poker on the Internet
couldn’t get any better, you now have many awesome free money pokesr deals at your disposal.
Keep on working, great job!
Do you mind if I quote a few of your articles as long as I
provide credit and sources back to your site? My blog site
is in the exact same area of interest as yours
and my visitors would truly benefit from some of the information you present here.
Please let me know if this okay with you. Appreciate it!
That is a good tip particularly to those fresh to the blogosphere.
Simple but very precise information… Appreciate your sharing this one.
A must read post!
Pretty! This was a really wonderful article. Thank you for providing this info.
Feel free to visit my web blog: clash of clans hack no survey
Gߋod post. І learn something totally neա аnd challenging
ⲟn blogs Ӏ stumbleupon еѵery day.
Ιt ѡill always Ье іnteresting tо
гead through content from օther writers and սѕе a ⅼittle
ѕomething froom their sites.
Here iѕ mʏ weblog; free everstryke
Hello would you mind letting me know which hosting company you’re working with?
I’ve loaded your blog in 3 different internet
browsers and I must say this blog loads
a lot quicker then most. Can you suggest a good web hosting provider at a honest price?
Thanks, I appreciate it!
With all quality factors, it no way an excitement to look over
the creative camera design from Casio. However, the Holy Grail of large sensor compacts, one with a zoom lens, remained a figment of the imagination. Most digital cameras, separately from camera phones and a few particular
types, have a criterion stand screw.
Feel free to visit my web-site :: what is a canon dslr
A new technology introduced by one of the biggest automobile companies, Volvo,
will ensure that your car avoid accidents on the roads involving pedestrians.
The turbo 4-banger in the Volkswagon GTI Mk5 is fairly unique among such engines
in that it produces huge amounts of torque at a relatively low number of RPMs.
It includes 4 different frequencies so you can race against your friends.
Heya i am for the first time here. I found this board and I in finding It really helpful
& it helped me out a lot. I hope to provide one thing back and help others like
you helped me.
Very nice post. I just stumbled upon your weblog and wished to say that
I have really enjoyed browsing your blog posts. In any case I’ll be subscribing
to your rss feed and I hope you write again very
soon!
Dan Rooney remains busy as the Ambassador to Ireland and his son Art Rooney
II manages the team these days with Dan’s helpful insight.
Here is wherever the look at film internet based web pages began to score.
Today is a sad day for all fans of live sports streaming, as
we at Wiziwig have to.
Howdy, I do believe your blog might be having browser compatibility issues.
Whenever I look at your website in Safari, it looks fine
however, when opening in I.E., it’s got some overlapping issues.
I simply wanted to give you a quick heads up! Besides that, great site!
What’s up all, here every person is sharing such know-how, thus it’s pleasant to read this website, and
I used to pay a visit this web site everyday.
Hi there! Do you use Twitter? I’d like to follow
you if that would be ok. I’m undoubtedly enjoying your blog and look forward to new updates.
Good way of telling, and nice paragraph to get information concerning my presentation subject, which i am going to convey in university.
the
Also visit my web site; best traffic ticket lawyer broward (Guy)
Today we have the international terrorist organization of
Hezbollah, which is financed by the nation state of Iran, that promises to blow Israel off the map,
if Iran has nuclear weapons can Israel survive the onslaught.
And also his characters, how he keeps the tension and suspense in his stories.
What kind of training did you do for your role in ‘Mission: Impossible ‘ Ghost Protocol’.
Here is my homepage … mission impossible rogue nation complete movie
Sure however with this software monsters are considered withh another mild in a
method they’re consirered to be human in character.
These are websitess that originated as private grdowth blogs however
have grown tto a degree where there are now multiple authors providing content matferial
on a regular basis.
Here is my web site … professional self development goals
Whether you are a fan of online Gambling games, have
some spare time tto gamble or you are simply looking to make some extra cash from online Gambling, then why not visit a free
Casino Guide website and start improving your
Casino Game skills. Another line off attack was being forging close ties universities oor colleges, some medical partnerships, government departments or other drugmakers
to be expanded Pfizer’s small business, Halfon talked about.
Playing for real money is an adrenaline rush and you mut bbe on top of your game.
After going over a number of the blog posts on your web site, I honestly appreciate
your way of blogging. I added it to my bookmark webpage list
and will be checking back soon. Please visit my web site
too and let me know what you think.
Hi there! This article couldn’t be written any better!
Looking at this post reminds me of my previous roommate!
He always kept talking about this. I most certainly will forward this post to him.
Fairly certain he will have a good read. Thanks for
sharing!
When some one searches for his necessary thing, therefore he/she desires to be available that in detail, so that thing is maintained over here.
It’s not my first time to go to see this web site, i am visiting this web site dailly and obtain pleasant information from here every day.
I have read so many content regarding the blogger lovers but this piece
of writing is in fact a nice piece of writing, keep it
up.
Here is my blog – Canon EOS 70D Digital SLR Camera EFS 18135mm IS wi
This web site certainly has all the information and facts I
wanted about this subject and didn’t know who to ask.
Aw, this was an incredibly nice post. Finding the time and actual effort to produce a
very good article… but what can I say… I hesitate a lot and don’t manage to get nearly anything done.
Student Loans and significantly more with out any delay
….
Stop by my web-site … web page design
Each of them has a different function according to
the intensity of the misspelled keywords. Improving Site Structure – This second
part tells you how to properly structure URLs.
But it is extremely important that anyone looking to hire an SEO professional be aware of the differences.
There are two techniques that combine to form a complete dc seo company.
Highly energetic article, I loved that bit. Will there be a part 2?
Gone are the days of one way marketing or merely just
posting comments about your site or other related topics.
The Internet has changed the way we attain information forever and Google has been the main driving force and proponent behind this instant access to information.
I am hoping to show you that I can help you achieve top rankings in the sites like I have for all my other clients.
Eventbrite is an online party-planning tool with KISS (Keep It Simple
Stupid) design so it is usually a top rated choice among event planners
(organizers).
Look at my site; Dc seo
Hello there! I just wish to offer you a huge thumbs up for the excellent info you have right here on this post.
I will be coming back to your website for more soon.
Although Yahoo isn’t the biggest, or the highest ranking
search engine on the internet, it is still one of the most essential, and if you want use search engine optimization and promotion as a main technique in your marketing arsenal,
you unquestionably need to get listed here. The Internet has
changed the way we attain information forever and Google has been the main driving
force and proponent behind this instant
access to information. Auro – IN has a strong team that is
built on the delivery of outstanding campaign results,
customer service and appreciation, and high levels of technical capabilities and
values. Eventbrite is an online party-planning tool with KISS
(Keep It Simple Stupid) design so it is usually a
top rated choice among event planners (organizers).
my webpage – dc seo – Shaun,
I have to thank you for the efforts you’ve put in penning this blog.
I am hoping to view the same high-grade blog posts from you in the future as well.
In fact, your creative writing abilities has encouraged me to
get my own, personal website now 😉
Some of them will require you to be pre-approved for a
home loan from your local lender. Be sure to check the contract details on any grant or loan you’re
thinking about applying for, to prevent you from running into real financial trouble later.
Many house hunters are already flooding the housing market during the spring buying season. The Connecticut
Housing Finance Authority, more commonly known by its initials CHFA, has been providing
low interest financing for first time homebuyers since
1970. Secretary Donovan said that no one is looking into
the homebuyer tax credit at this time. However, Secretary Donovan implied that the return of the homebuyer tax credit is definitely being looked at now.
RSS internet marketing increase sales (http://issuu.com/) is a software used by many on thhe
Web to ship articles, ads, emails, customer assist responses, ezimes to purchasers and potential clients.
I all the time used to read piece of writing in news papers but now as I am a user of internet therefore from now I am
using net for posts, thanks to web.
when you hold the michael kors handbags in your
hands ,it really feels great.when you put on michael kors handbags factory outlet locations
store online,it is just like you are enjoying a foot massage every moment!
michael kors outlet website
If your site is relatively sound, the most important results for
you to consider are the keyword hits. The process
of dc seo; Eric, is the series
of steps that are undertaken to ensure that a website is visible among internet users to an optimal level.
Auro – IN has a strong team that is built on the
delivery of outstanding campaign results, customer service and appreciation, and
high levels of technical capabilities and values. Further the
sites whose ranking using the search engines is good
will attract potential clients, which results to mores sales.
Do you have a spam issue on this website; I also am a
blogger, and I was curious about your situation; many of us have created some nice methods and we are looking to
swap methods with others, please shoot me an e-mail if interested.
how do make money online certain you can deliver on your promises before launching a campaign.
You’ve made some decent points there. I checked on the internet for more info about the issue and found most individuals will go along
with your views on this web site.
Remarkable issues here. I am very happy to look your post.
Thanks so much and I’m having a look ahead to touch you. Will you please drop me
a e-mail?
The last few games were a little bit of a struggle for us, but the
irony is, in two of those three games, we actually played really well in terms of possession,”
Head Coach Tracey Leone said.
Here, we’ve rounded up five of the best i – Phone fax apps available on the App Store.
You can quickly and easily adhere directly to
your cell phone screen, but non-adhesive backing
will not leave sticky residue. I bet you will start to clean the marks and you
will be thinking to get something that could protect
the screen otherwise it will be ruined with
hand marks and scratches.
My web blog … coque iphone 5s
Hi to every one, the contents present at this web site are actually amazing for people knowledge, well, keep up the good work
fellows.
Una farola y una fuente van a recibir a los paseantes” que decidan adentrarse en este espacio.
Here is my site: intercambios de parejas
Good way of explaining, and fastidious piece of writing to take data regarding my
presentation subject matter, which i am going to convey in academy.
Hello! I simply would like to give you a huge thumbs up for your great
info you have here on this post. I will be returning to
your site for more soon.
Have a look at my website: Essential Oil For Acne
Although Yahoo isn’t the biggest, or the highest ranking search engine
on the internet, it is still one of the most essential, and if you want use search engine optimization and promotion as a
main technique in your marketing arsenal, you unquestionably need to get listed here.
The usual dc seo methods include keyword
research, link building and such. But it is extremely important that
anyone looking to hire an SEO professional be aware
of the differences. Eventbrite is an online party-planning tool with KISS (Keep It Simple Stupid)
design so it is usually a top rated choice among event planners (organizers).
I am actually glad to glance at this webpage posts which contains plenty of valuable
information, thanks for providing these statistics.
They have a program for their qualified members that allows 100% financing of a primary home
loan. The most typical one of these is a 30 year fixed rate.
If you don’t understand a term or any of the jargon involved in real estate, then by all means ask your lender or broker for
clarification. By the time they get the keys, their new home is live-in ready.
They have expert eyes to sneak around and noses
to sniff throughout neighborhoods with homes for sale that are just
about to be posted in the market. Assistance may be available
through your local Community Planning & Development office or nonprofit organizations.
If your site is relatively sound, the most important results for you to consider are the keyword hits.
Thirdly, the search engines need legit companies to do site optimization. Depending on how how much time you have you can do this about once
per week. This mode of advertisement was faster than the earlier ones and reached more people but it had its
own limitations.
My page – dc seo (Blanche)
If your site is relatively sound, the most
important results for you to consider are the keyword hits.
Two: Research different services – Assuming that you
are going to hire someone to do it for you, the next step is to research as many different services
as possible. I am hoping to show you that I can help you
achieve top rankings in the sites like I have for all
my other clients. A guy named Alan Emtage, a student at the University
of Mc – Gill, developed the first search engine for the
Internet in 1990.
Here is my site :: dc seo (Howard)
Each of them has a different function according to the intensity of the misspelled keywords.
The trends in this industry change and new developments take place
only when Google comes up with some novel feature that ends up breaking every site’s
dc seo (Elba) and
compels them to consider a change in their current content presentation in order to do well.
But it is extremely important that anyone looking to hire an SEO
professional be aware of the differences. This mode of
advertisement was faster than the earlier ones and reached
more people but it had its own limitations.
Get testimonials from the clients you already worked with, about your work and experiences.
Two: Research different services – Assuming that you are going to hire someone to do
it for you, the next step is to research as many different services as possible.
I am hoping to show you that I can help you achieve top rankings in the sites like I
have for all my other clients. A reputable washington Dc Seo company
won’t have any qualms about connecting potential clients with
former ones.
I’ll immediately grab your rss feed as I can’t to find your e-mail subscription hyperlink or
newsletter service. Do you’ve any? Kindly permit me know in order that I could subscribe.
Thanks.
Although being aware of keyword percentages is a good idea,
it is more important that content be relevant and useful to the
visitor. Improving Site Structure – This second part tells you how
to properly structure URLs. Auro – IN has a strong team that is built
on the delivery of outstanding campaign results, customer service and appreciation,
and high levels of technical capabilities and values.
Tests with a model like Page – Rank have shown that the system is not infallible.
Also visit my web-site dc seo (Kerri)
Hey there! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Many thanks!
I enjoy, lead to Ӏ discovered еxactly ᴡҺаt Ι used tօ bee ⅼooking fⲟr.
Уօu’ѵе ended mү 4 dday lengthy hunt!
God Bless ʏⲟu man. Ⲏave a ǥreat Ԁay.
Bye
Ꮋere іѕ my web site; http://design.slimo.sk/index.php/blog/item/5-we-motivate-people-to-think-in-a-creative
I have read some excellent stuff here. Certainly worth bookmarking for
revisiting. I surprise how a lot effort you
place to make any such excellent informative web site.
Once you buy, the person (guru) selling the product knows right away you are a buyer.
It can be an overwhelming task buying a home
for the first time. Those that are seeking a Mortgage Ireland opportunity will have to vouch for steady savings
buildup as one criterion the First Time Buyer Mortgage program.
Regardless, the eligibility is basically as stated above,
and entitles you to save $750 on your taxes. In order to be
eligible for these types of loans, your income will need to
be below a certain level, which varies by area, family size, and house.
However, Secretary Donovan implied that the return of the homebuyer
tax credit is definitely being looked at now.
Remember, there are many to choose from and the best are those geared toward assisting
low to medium income families by offering smaller down payments, no down payments, lowered closing costs and reduced
interest rates. Depending on the loan amount, this could
mean a difference of $250. Ask how your credit history
affects the price of your loan and what you would need to do to get a
better price. The types of mortgage below are the most widespread:.
The quick round up of the feature will be easily
furnished here, and this is the point to
mention that there is no need to get worried from where the tool
will be downloaded. And, when you apply for home finance solutions, lenders ascertain your financial condition by taking a look at your income.
Hey there! Do you use Twitter? I’d like to follow you if that would be okay.
I’m undoubtedly enjoying your blog and look forward to new updates.
It’s ɑ pity уⲟս ⅾⲟn’t һɑvе a ԁоnate
Ьսttоn! I’ɗ ϲегtɑіnlу ԁօnatе toⲟ tһіѕ fantastiс ƅlоg!
Ι gᥙess fοr noоw і’lⅼ settle fߋг
ƅօοқmагҝіng and аdԀng ʏoսг ᏒᏚS fееⅾ tο mү Ԍⲟⲟǥⅼе аϲϲoᥙnt.
Ι ⅼоοκ fгѡaгԁ to new upԀatеѕ
ɑnd ѡіlⅼ tɑⅼк abⲟսt tҺіѕ ѕіtᥱ ѡith mmʏ Ϝacеbοοκ ǥгօᥙp.
Тallҝ ѕߋοn!
If your site is relatively sound, the most important results for you
to consider are the keyword hits. The usual dc seo (Rickie) methods include
keyword research, link building and such. But in general here are
the services that an online business owner should expect from SEO experts and
other agencies and consultants:. A guy named Alan Emtage, a student at the University of Mc – Gill, developed the first
search engine for the Internet in 1990.
Another major difference between the two is that while PPC is a paid form of advertising, organic search engine optimization is absolutely free.
Improving Site Structure – This second part tells you how
to properly structure URLs. Forgetting to write for an audience is one of the biggest mistakes that bloggers make.
Webmaster follows a long process to promote a website
in top search engines (Google, Yahoo and Bing).
Feel free to surf to my web site; dc seo – Tracie –
First off I would like to say superb blog! I had a quick question which I’d like to ask if you do not mind.
I was interested to find out how you center yourself and clear your thoughts prior to writing.
I have had trouble clearing my thoughts in getting my thoughts out there.
I truly do enjoy writing but it just seems like the first 10 to 15 minutes are usually lost simply just trying to figure out how to
begin. Any ideas or hints? Many thanks!
If your site is relatively sound, the most important results for you to consider are the keyword
hits. The process of SEO is the series of steps that are undertaken to ensure that a website is visible
among internet users to an optimal level. Unlike TV, radio and other traditional marketing channels that need big budgets to be effective, dc seo – Lois,
can be cost effective. Webmaster follows a long process to promote a website in top search engines (Google, Yahoo and Bing).
Wonderful, what a blog it is! This website presents helpful data to us, keep it up.
Brown and Harrow will be the primary choices in the backcourt, joining three-12 months starter Javier
Gonzalez. Courts typically by no means make cell
phone calls, but send letters by way of United States Postal mail.
Even with the addition of Roy Williams, Brad Johnson threw only two touchdown passes in three games, and threw for 5 interceptions.
All is valid about this game which hack tool
system so improved get it wile it is free in your case. It
starred then-unknowns like Paul Walker, Vin Diesel, and Michelle Rodriguez
in a story about a group of street racers who have a method
for hijacking tractor trailers for dollars. Although the AMERICAN IDOL
season Finale aired on May 16, 2013 this season’s fan-favorites will carry on on with the
2013 Reside!
In football context, the most valuable player would be a player that the group values the
most, and in flip, holds the greatest value to a workforce out of all the teams.
The bump crashed Earnhardt into the wall and out of the race.
Some folks discover that they just don’t have the time to dedicate to their pet bird.
It starred Burt Reynolds, Sammy Davis, Jr., Farrah Fawcett, and Jackie Chan in a single of his earliest and smallest roles.
It is my conclusion, that no record nor tree but only a non-hierarchical aggregator with a
tagging technique could actually be representative.
Above Ramiele’s cuteness and oversized wonderful vocals. Not only does Kurt Warner have the top receiver with yards just after the catch, but
also Larry Fitzgerald ranks eighth for receivers in the group.
It just will take a tiny commitment and will electrical
power to follow your dream. Do you know your common 100m speed in the
pool for your priority race distance? The leading-grossing movie in which
racing is a central theme is “Cars,” which would spawn the sequel “Cars 2” because of
its good achievement.
If you don’t move Richardson you have to
have to move Fogerson. Only 5 of the cash hack top eleven
yards right after the catch receivers are wide receivers.
Don’t get fooled into thinking that power training
is poor for you – most of individuals studies were finished with heavy dumbbells and barbells, not
the far more precise body bodyweight and elastic form resistances you should be employing.
Another model of the electronic mail tells readers to boycott Citgo
gas.
She also wholesales to Nail Salon owners and does some direct retailing
as well as offering on eBay. Not sure if what I have heard of these efforts so far, is definitely thoughts
blowing, but I absolutely applaud the energy and a spin off is that classical music is locating a bigger audience.
These are a couple of rather major if’s for this youthful guy.
Take a look at my homepage … Full length films
Another major difference between the two is that while PPC is
a paid form of advertising, organic search engine optimization is absolutely free.
When Page – Rank was patented the patent was assigned to Stanford University.
Depending on how how much time you have you can do this
about once per week. There are two techniques that combine to form a complete dc seo,
Mirta,.
Thanks for another fantastic article. Where else could anyone
get that kind of info in such a perfect manner of
writing? I have a presentation next week, and I’m
at the search for such information.
, and I would say yes, here is what you want to
do. All of these is going to be drastically reduced if you use the First Time Home Buyer Program.
Ask how your credit history affects the price of your loan and what you would need to do to get a better price.
There are two kinds of home improvement loans available to choose
from. They have expert eyes to sneak around and noses to sniff
throughout neighborhoods with homes for sale that are just about to be posted in the market.
The slogan of this company is “income for the regular joe” which means
that you don’t need any website marketing expertise to take advantage of the system.
Many small companies prefer to hire SEO specialists as consultants rather than full time
employees, unless they have a certain amount of websites that need to be continuously maintained and optimized.
When Page – Rank was patented the patent was assigned to Stanford University.
Forgetting to write for an audience is one of the biggest mistakes that bloggers make.
There are two techniques that combine to form a complete dc seo.
Although Yahoo isn’t the biggest, or the highest ranking search engine on the internet, it is still one of the most essential, and if you want use search engine optimization and promotion as a main technique in your marketing arsenal, you unquestionably need to
get listed here. Two: Research different services – Assuming that you are going to hire someone to do it
for you, the next step is to research as many different services as possible.
But it is extremely important that anyone looking to hire
an dc seo – Eden – professional be aware of the differences.
Further the sites whose ranking using the search engines is
good will attract potential clients, which results to
mores sales.
Really no matter if someone doesn’t understand afterward its up to other visitors
that they will help, so here it happens.
Take a look at my website :: Essential Oils For Depression
Each of them has a different function according to
the intensity of the misspelled keywords.
When Page – Rank was patented the patent was assigned to Stanford University.
Forgetting to write for an audience is one of the biggest mistakes that bloggers make.
You have to take price quotes from different dc seo (Leonor) companies
locally and internationally.
What’s up, this weekend is good for me, since this moment i am reading this wonderful informative paragraph here at my house.
Hi there, every time i used to check website posts here early in the break of day, since i like to gain knowledge of more and more.
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I am quite sure I’ll learn many new stuff right here!
Best of luck for the next!
I needed to make an effort to state my gratitude in your direction and also
this website that was wonderful! Loving it!
Get testimonials from the clients you already worked with, about your
work and experiences. The trends in this industry change and new developments take place
only when Google comes up with some novel feature that ends up breaking
every site’s dc seo (Elisha) and compels
them to consider a change in their current content presentation in order to do well.
Depending on how how much time you have you can do this about once per week.
This mode of advertisement was faster than the earlier ones
and reached more people but it had its own limitations.
Link exchange is nothing else except it is just placing the other person’s webpage link on your
page at proper place and other person will also do similar in support of
you.
each time i used to read smaller content that also clear their motive, and
that is also happening with this piece of writing which I am reading here.
Many small companies prefer to hire dc seo company specialists
as consultants rather than full time employees, unless they have a certain amount
of websites that need to be continuously maintained and optimized.
Two: Research different services – Assuming that you are going to hire someone to do it
for you, the next step is to research as many different services as possible.
While effective SEO needn’t be difficult, it does take work.
Webmaster follows a long process to promote a website in top search engines (Google, Yahoo and Bing).
Good day! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Many thanks
Some of them will require you to be pre-approved for a
home loan from your local lender. Some down payment assistance organizations have a
list of homes for sale from which the buyer may choose
to own a home. Nehemiah Program, Ameri – Dream, Partners In Charity, Homes For All Programs.
Before you can even begin to plan how you’re going to get him to want you back,
you have to reignite his interest. If an individual or couples desire to meet the criteria for a home buyer program, then the history
of rental payments will also be considered. Your net worth is the basic information that
you will need when you apply for a mortgage.
I’ll immediately grab your rss feed as I can’t to find your email subscription hyperlink or e-newsletter service.
Do you have any? Kindly let me understand so that I may subscribe.
Thanks.
You really make it seem so easy with your presentation but I find this
matter to be actually something that I think I would never understand.
It seems too complicated and very broad for me.
I’m looking forward for your next post, I will try to get the hang of it!
Great post. I’m facing a few of these issues as well..
Great web site you have got here.. It’s hard to find
excellent writing like yours these days. I truly appreciate people like you!
Take care!!
Get testimonials from the clients you already worked with, about
your work and experiences. Improving Site Structure – This second part tells you how to
properly structure URLs. Forgetting to write for an audience is one of the biggest mistakes that bloggers make.
This mode of advertisement was faster than the earlier ones and reached more people but it had its own limitations.
Here is my web page; dc seo (Christa)
constantly i usеd tto гead smaller ϲontent tҺаt аlso сlear their motive, andd that іѕ ɑlso happening
ѡith tɦiѕ paragraph ԝhich ӏ ɑm reading at tɦіѕ рlace.
Feeel free tо visit mmy blog post; how to earn money online
Nowadays, the conditions for your website to be ranked high
in the search engine results are based on the search engine
optimization techniques that you decide to use.
The Internet has changed the way we attain information forever and Google has been the main driving
force and proponent behind this instant access to information. Thematic relevance is
of key importance for the creation of quality backlinks.
In this way, it is informed about the kind of information that
a surfer is looking for.
Review my homepage: dc seo; Teresita,
Hi mates, how is everything, and what you
would like to say regarding this post, in my view its
really awesome in support of me.
Gone are the days of one way marketing or merely just posting comments about your site or other related topics.
Thirdly, the search engines need legit companies to do site optimization. But in general here are the services that an online business
owner should expect from seo washington Dc experts and other agencies and
consultants:. Eventbrite is an online party-planning tool
with KISS (Keep It Simple Stupid) design so it is usually a top rated choice among event planners (organizers).
It’s actually a nice and useful piece of info.
I’m satisfied that you simply shared this helpful info with us.
Please keep us up to date like this. Thank you for sharing.
Do you mind if I quote a couple of your articles as
long as I provide credit and sources back to your site? My blog site is in the very same
niche as yours and my users would truly benefit from some of the information you provide here.
Please let me know if this alright with you.
Cheers!
Aw, this was an exceptionally good post. Finding the time and
actual effort to create a great article… but hat can I say… I put things off a whole
lot and don’t manage to get nearly anything done.
my web page; real estate websites for sale
Hello, i think that i saw you visited my blog thus i came to go back the
choose?.I am attempting to to find issues to improve my site!I assume iits ok to use
some of your concepts!!
Link exchange is nothing else except it is only placing the other
person’s webpage link on your page at suitable place and other person will also do similar for you.
Breathtaking! You do not come by data like this easily and I am not so ungrateful!
Preserve it up people!
In this students’ guide, you can study all the essential methods on how
to decide oon a career.
Also visit my webpage; work at home data entry
jobs legit (Marlon)
Hello, I want to subscribe for this webpage to take most up-to-date updates, so where
can i do it please help out.
You really make it seem so easy along with your presentation however I in finding this topic to be actually something that I believe I might never understand.
It kind of feels too complex and very extensive for me.
I am taking a look ahead in your next submit,
I’ll try to get the grasp of it!
This has given rise to a whole new generation of live performance goers throughout
the globe.
What’s up everyone, it’s my first pay a quick visit at this site, and post is genuinely fruitful
designed for me, keep up posting these types of articles.
The addition of affiliate marketing softwade (Charissa) products permits the
network marketer to implement the very same diversification technique that
is utilized by main corporations.
It’s really a great and useful piece of info.
I’m happy that you shared this helpful information with us.
Please stay us up to date like this. Thank you for sharing.
Feel free to visit my weblog: clash of clans hack
What a stuff of un-ambiguity and preserveness of precious knowledge concerning unpredicted emotions.
Rates do tend to go up and down and there’s no knowing for sure whether you will gain or lose.
For those with a Commonwealth Seniors Health
Card as well as a WS Seniors Card, the rebate is 50 percent and eligibility for fee deferment.
While a good part of this is credit card debt there are also certain balances
that are independent of the little pieces of plastic.
Hi there it’s me, I am also visiting this web page regularly,
this web site is truly good and the users are in fact sharing pleasant thoughts.
If some one desires expert view concerning running a blog then i advise him/her
to pay a quick visit this website, Keep up the good work.
Excellent post. I used to be checking continuously this blog and I’m inspired!
Extremely useful information particularly the remaining part :
) I take care of such information much. I was seeking this certain information for a very long time.
Thank you and good luck.
|there is a ticket given in the|there released is a citation inside
My web-site: their primary care [Corazon]
I’m fortunate to have a full-time task and
to be remarried to someone with a strong work principles.
Here is my webpage – data recovery tools (Piper)
Bocchini SF, Habr-Gama A, Kiss DR, Imperiale AR, Araujo
SE: Gluteal and perianal hidradenitis suppurativa: medical treatment by large excision.
My web page :: molluscum contagiosum diet (Enrique)
We understand numerous retired Canadian who no longer spend time in the US
simply due to the fact that their health network labs west reading care insurance expenses are
so exorbitant.
Your style is unique compared to other folks I have read stuff from.
Many thanks for posting when you have the opportunity,
Guess I will just book mark this blog.
A healthy person also interact socially with the people around him and forms various type of relationships.
Here is my web blog; health partners woodbury
Psoriasis is a skin illness that triggers your skin cells
to develop rapidly on the surface of your skin.
My blog hidradenitis suppurativa suggested diet, Samual,
The truth is that this book is for anyone who has autoimmune disease, and everybody who knows
somebody with Hidradenitis supparativa.
Feel free to visit my page: hidradenitis suppurativa
diet recipes (Robin)
I have actually had surgery in my groin as well, and considering
surgical treatment for my underarms.
Look at my blog :: folliculitis diet (Brittany)
Get testimonials from the clients you already worked with, about your work
and experiences. So what are you going to put in their search box is “website optimization tips”.
But it is extremely important that anyone looking to hire an SEO professional be
aware of the differences. There are two techniques that combine to form a
complete SEO.
Take a look at my web blog – frederick md hvac
I’ll right away seize your rss feed as I can’t in finding your email subscription hyperlink or e-newsletter service.
Do you have any? Please let me realize so that I
may just subscribe. Thanks.
Irónicamente, ella llenó su obligación teórica de “muere´´ cuando los productores
de la película La Casa de Cera , usaron un anuncio que decía “Vean a Paris morir´´, enfocando la escena donde ella muere.
Algunos niños con fimosis intensísimas pueden presentar, con mayor facilidad que
los otros, infecciones de orina, pero hecha esta excepción,
la fimosis no va a traer más problemas.
My web-site; fimosis en adultos fotos, Ezra,
Tu médico puede diagnosticar la fimosis basada en una historia clínica detallada y un examen físico.
Look into my web-site – fimosis en adultos tratamiento sin cirugia – Alyssa –
Great post. I used to be checking continuously this weblog and I am inspired!
Extremely helpful info particularly the last section 🙂 I handle such information a lot.
I was seeking this certain info for a long time. Thank you and best of
luck.
Preventing this type of isolation is among the important reasons to get treatment.
Feel free to visit my blog post :: hidradenitis suppurativa treatment (Kristofer)
Am going to alleviate myself into the paleo diet firstly by cutting out dairy products, then the rest to follow.
Here is my blog … hidradenitis suppurativa diet recipes (Gabriele)
With a number off options correslonding to round
the clock operability, opportunity of widening clientele
base, and low beginning prices, it’s not shocking that
the Web internet marketing inc careers business is now full of mushroom businesses owned and operated by novices who are eagyer to share the wealth of
this profitqble industry.
Each woman experiences a unique experience while breastfeeding.
Taking full responsibility for where you place your attention is a skill
that is easy to develop. Just like several people when mentioned, “If this hasn’t raining that hasn’t training.
Feel free to visit my web page … tinder gratuit
For briefly easing the discomfort and reducing the
swelling, these prescription antibiotics can get the job done.
My homepage: folliculitis diet [Felicia]
Likewise, a list of delicious foods proven to assist you get
healthy and remain healthy together with the advantages each one
offers.
My website; nutrition health articles recent
This was successfully completed by PepsiCo for its Doritos brand of snacks during the Super Bowl 2007,
and once more in 2009 and 2010.
my web page chea paid advertising (Delmar)
Fardet L, Dupuy A, Kerob D, et al. Infliximab for serious hidradenitis suppurativa: short-term medical
efficacy in seven successive clients.
Look at my web site … hidradenitis suppurativa foods to avoid
(Georgetta)
Handling it is a long battle and there is no fast Hidradenitis
Suppurativa treatment as it takes some time to recover.
Here is my blog post :: molluscum contagiosum diet (Magda)
El empleo de cremas de esteroides como tratamiento eficiente no
invasivo para la fimosis adquirida se aconseja (tratamiento de la fimosis repetida puede implicar la
aplicación de una crema con esteroides para el prepucio hasta 3 veces al día durante un mes más o menos para aflojar el anillo
adhesivo) el uso de linimentos no esteroideos también se ha
descrito para ser de beneficio en el tratamiento de la fimosis adquirida.
my weblog: fimosis fotos operacion (yokomukai.com)
Se piensa que las probabilidades de contraer
cáncer de pene es mayor en las personas que tienen fimosis.
Feel free to surf to my web site fimosis en adultos
sintomas (Matilda)
You must likewise be handled by your physician throughout
your course of treatment to guarantee your body responds appropriately.
Feel free to surf to my webpage: boils diet – Nola –
This information is invaluable. When can I find out more?
La parafimosis debe distinguirse de la fimosis, una condición que no es
de emergencia en la que el prepucio no puede ser retirado.
Here is my webpage :: fimosis en adultos pdf – Iva,
Also visit my web page: operating system installation media for
virtual machines; Ross,
Dufour DN, Emtestam L, Jemec GB. Hidradenitis Suppurativa: A Common and Burdensome, Yet Under-Recognised, Inflammatory Skin Disease.
Visit my homepage … boils diet (Florentina)
El principal y más evidente síntoma de fimosis en el adulto
es la incapacidad para retraer el prepucio
sobre el glande sobre toda durante la erección.
Also visit my web-site; fimosis femenina wikipedia, Sophie,
Pasienter med hidradenitis suppurativa og fordøyelsesbesvær og/eller
jernmangelanemi bør utredes med tanke på Crohns sykdom.
Feel free to visit my website folliculitis diet
Heart rate,.
Here is my page allied health advocates llc seattle
[Theo]
We’re up against our own dependency, the unrelenting ideas and
prompts to gamble, & the need to win back a minimum of a few of exactly
what we’ve lost.
Feel free to surf to my webpage cctv installation cost in india; Elvia,
It’s really a nice and useful piece of information. I’m happy that you simply shared this useful information with us.
Please stay us informed like this. Thanks for sharing.
I’ve been prescribed a 3 month course of Oratane 20mg, a 6 week course of
prescription antibiotics and topical creams.
Here is my homepage; boils diet (Frieda)
Having it in addition to other fruit or vegetable juices will certainly assist you enjoy its additional health affairs blog [Ashton] advantages.
La operación de fimosis tiene por si fuera poco
unos beneficios notables para la salud del hombre, puesto que reduce la probabilidad de desarrollar otros inconvenientes y
enfermedades, mejora la higiene y la vida sexual de aquellos
que han sufrido este inconveniente.
Also visit my webpage: fimosis fotos operacion (Ken)
Es mejor que primero intentes todas y cada una de las vías para curar la fimosis en casa, en tanto que es frecuentemente
más económico y indudablemente menos vergonzoso que ver a un urólogo.
My web page … fimosis fotos adultos
En España, de manera general, la intervención corre a cargo de los cirujanos urólogos pediátricos; que en la sanidad pública la efectúan siempre y en toda circunstancia por motivos médicos.
Take a look at my web page … fimosis en adultos
pdf (Isidra)
Together with your assistance, the HSF wishes to make a distinction in the lives of
those who suffer with hidradenitis suppurativa.
Review my weblog :: boils diet – Christie –
Jemec GBE, Heidenheim M, Nielsen NH. The frequency of hidradenitis suppurativa
and its potential precursor lesions.” J Am Acad Dermatol 1996; 35(2):191 -4.
my web page – hidradenitis suppurativa foods to avoid (Lilly)
It is a challenging problem to treat and treat;
frequently, tight elastic compression garments need to be used long-lasting.
Here is my web site – hidradenitis suppurativa foods to avoid (Thad)
Choose the proper variation of the TeamViewer program to download as guide by your expert, and save the file to your desktop.
My site :: active directory federation services 3.0
Rachel, I have seen extremely a remarkable improvement in my HS
signs by following the Paleo diet plan.
my web blog; boils diet
I don’t think lots of people today would support free cosmetic surgery for inmates.
my homepage … hidradenitis suppurativa foods to avoid
Gracias, estoy en mi día 3°. Ciertamente me ayudan tus comentarios y
fotos; un saludo y muy buen blog!!!
Here is my site … fimosis infantil sintomas
Hidradenitis suppurativa lesions are seldom seen on the trunk of the body or on the scalp
or legs.
Also visit my web page – molluscum contagiosum diet (Herbert)
I have lastly refined my method of eliminating the infection with at-home solutions, utilizing entirely healthy active
ingredients.
My page :: allied health advocates llc seattle (Zak)
Gone are the days of one way marketing or merely just posting comments
about your site or other related topics. The process of SEO is the series of steps that are undertaken to
ensure that a website is visible among internet users to an optimal level.
Depending on how how much time you have you can do this about once per week.
This mode of advertisement was faster than the earlier ones heating and ac repair frederick md reached more people
but it had its own limitations.
Hi there! I could have sworn I’ve been to this blog before but after reading through some of the
post I realized it’s new to me. Anyways, I’m definitely delighted I found it and I’ll be bookmarking and checking back often!
Every weekend i used to visit this web page, for the reason that i wish for enjoyment,
as this this website conations really good funny information too.
Take a look at my web blog; Lake Louise Canada One Of The Most Beautiful Places In The World
Hidradenitis suppurativa likewise appears more typical in people with acne and hirsutism (excessive irregular hairiness, especially in females).
Here is my weblog … molluscum contagiosum diet (Berniece)
Conway H, Stark RB, Climo S, Weeter JC, Garcia FA: The surgical treatment of chronic hidradenitis suppurativa.
Review my website hidradenitis suppurativa suggested diet (Lizette)
Hidradenitis suppurativa, also called acne inversa, is a follicular occlusion disease that
can severely decrease quality of life.
Here is my homepage molluscum contagiosum diet (Santo)
I waas curious if yyou ever tholught of changing the structure oof
yourr blog? Its verry well written; I love what youve got too
say. But maybe you could a little more in the way of contesnt soo people coluld connhect withh it better.
Youuve got aan awful lot of text for only having 1 or 2 pictures.
Maybe you could space it out better?
Here is my weblog; how to become a real estate agent in gauteng
If you win 50 % custody I guess you pay no kid support because you’ll have the child with you
2 weeks of the month.
Look at my blog memory upgrade for imac 2007 (Fredric)
En España, de manera general, la intervención corre
al cargo de los cirujanos urólogos pediátricos; que
en la sanidad pública la realizan siempre por motivos médicos.
Also visit my page: fimosis fotos despues de la operacion (wiki.vongreiffenstern.de)
Early surgical treatment can (in some cases) cure the illness and
stop it from returning.
My site … hidradenitis suppurativa treatment (Jerilyn)
Amazing things here. I am very happy to look your article.
Thank you so much and I’m having a look forward to contact you.
Will you please drop me a e-mail?
Here is my page; نقل اثاث
La fimosis ocurre cuando la apertura del prepucio es demasiado estrecha y no
deja el paso del bálano.
Also visit my site fimosis infantil postoperatorio (http://landscapstr.com/members/brockdaves6136/activity/99767/)
Other reasons for tooth abscess are trauma to
the tooth, such as when it is broken or chipped, and gingivitis or gum disease.
Here is my weblog – folliculitis diet
Es preciso para los médicos establecer siempre y en todo momento
una manera pero eficiente de describir una enfermedad, y el caso de la fimosis
no es ajeno a esto.
Feel free to surf to my web-site fimosis en adultos causas (Wendy)
The brand-new caldwell health and welfare phone number (Lionel) app puts that
data in one place, accessible with a tap, giving you a present and clear summary of
your health.
The Business’s Biologic License Application for Humira for the treatment of HS is presently in review
by the FDA.
Feel free to surf to my webpage: boils diet (Tesha)
La fimosis en los adultos es una molestia que también afecta a
las relaciones íntimas, ya que se pierde sensibilidad en el pene.
Also visit my website: fimosis fotos bebes; Torsten,
Hi, Neat post. There’s a problem together with your web site in internet explorer,
may check this? IE still is the marketplace leader and a
good section of people will miss your great writing due to this problem.
If they did, youngster support enforcement would
work to keep families in contact, rather than apart.
My web site wireless networks not showing up xbox one (Pauline)
Greate post. Keep writing such kind of info on your
site. Im really impressed by your blog.
Hi there, You have done an excellent job. I’ll definitely
digg it and individually recommend to my friends.
I’m sure they will be benefited from this site.
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to in quest of extra of your great post.
Also, I have shared your website in my social networks
La higiene conveniente prepucio También se sugiere que los pacientes con fimosis adquirida.
My blog post fimosis en adultos fotos (Courtney)
The medical professionals I’ve seen have either been intirely unaware of HS or supportive and suggest only surgical treatment as a practical
alternative.
Also visit my web-site hidradenitis suppurativa treatment (Isis)
This table can old up to 250lbs and carries out similar as other best
inversion table amazon [Garnet] tables on the marketplace.
Change the best inversion table to buy (Zoila)
table to your height; your head needs to rest conveniently
on the bed of the table and not hang over
the edge.
Though, Ironman Gravity 1000 best inversion table to buy – Raymundo, Table has some downsides but its advantages surpass them.
Features: There are numerous kinds of inversion tables
having different what is the best inversion table to buy tables provide several inversion angles.
Heya i am for the first time here. I found this board and I find It really useful & it helped me out much.
I hope to give something back and help others like you aided me.
my web page – Destination Travel Wall Art Print For Home Office Gifts Nursery
ADVANCED: The more severe progressive and advanced
phases of cancer consist of: metastasis, secondary tumours, malignancy and terminal medical diagnosis.
Here is my homepage – hidradenitis suppurativa treatment – Reva,
I suggest it to anyone who thinks they might have hidradenitis superateva, can’t sing
its prases enough.
Here is my webpage :: folliculitis diet – Stephanie –
La fimosis es una intervencion quirurgica ambulatoria que
no reviste gravedad alguna y que no requiere ingresos.
My homepage – fimosis en ingles (http://www.bikelives.com)
La fimosis en los pequeños mayores y los adultos pueden variar en gravedad,
con un poco de poder para retraer su prepucio parcialmente (fimosis relativa), y ciertos plenamente incapaces
de retraer su prepucio, aun cuando el pene está en estado flácido (fimosis completa).
Also visit my website :: fimosis en adultos tratamiento sin cirugia (Jani)
Because an best inversion table amazon (Maximilian) table will have you hanging upside down by your ankles, you’ll wish to feel safe.
Fimosis primaria congénita ocurre en pequeños pequeños: los bebés y es normal tener en los años de la adolescencia.
my web page: fotos fimosis femenina – Builderbunch.com,
The goal of this post is to evaluate the scientific presentation, diagnostic
factors to consider and treatment of the illness.
Also visit my web blog … hidradenitis suppurativa treatment (Joyce)
Considering that an inversion table best price; Branden, table will certainly have you hanging upside down by your ankles,
you’ll want to feel safe.
It wil bbe money well spent.
my homepage; equity crowdfunding business model (Colin)
In advanced, chronic cases, surgery is commonly the option, however recurrences of HS are
not uncommon.
My web page: hidradenitis suppurativa diet
Jij suis sûr que vous-même apprécierez votre hack toutes vos fois la cual
vous jouerez Conflict of Clans ain vous publier avec entiers vos
camarads!
Love it wish I would of had it years ago … thank you for a quality, well made, proper physical
therapy machine!
Also visit my page … inversion table best price [Belinda]
Overall, if the best cheap inversion table (Cornell) table is moving
smoothly and it is comfortable to rest on, then it indicates it is worth buying.
Use in hidradenitis suppurativa would be ‘off-licence’ and just likely to be offered on a private basis.
Also visit my blog post … hidradenitis suppurativa suggested diet; Kathy,
Moves Body Upside down: This best inversion table for the money
table moves body upside down launching pressure from the back bone that instantly launches discomfort.
En nuestra entrada sobre el postoperatorio de fimosis damos unos consejos muy buenos
para que el postoperatorio sea más llevadero
y dure el menor tiempo posible.
Feel free to surf to my homepage; fimosis infantil sintomas (Darren)
Lastly, surgery may periodically be needed, particularly in pilonidal
cysts that recur, however also for hidradenitis suppurativa.
Look into my site: hidradenitis suppurativa diet recipes (Dalene)
Thanks for ones marvelous posting! I seriously enjoyed reading it, you happen to be a great author.I will make certain to bookmark your blog and definitely will come back in the foreseeable future.
I want to encourage you to continue your great writing, have a
nice afternoon!
The best inversion table reviews, Palma, can also be adapted to accommodate
users from 4-foot-9 to a minimum of 6-foot-5.
Good day! I know this is kind of off topic but I was wondering
if you knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
Además es muy común que el inconveniente persista durante un tiempo,
e incluso muchos pequeños pequeños tienen fimosis.
Here is my web site – fimosis infantil fisiopatologia ppt
– docs.plataforma.Canaima.Net.ve,
I had the pleasure of being involved with Therese, who
is the PR and Social Media liaison for Star Stable.
Here is my blog post – how to get free starcoins on star stable
Woah! I’m really digging the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance”
between user friendliness and appearance. I must say that you’ve done a amazing job with this.
Additionally, the blog loads super fast for me on Firefox.
Exceptional Blog!
A full 90-degree table with fitness and best inversion therapy table (Elva) choices for individuals of all levels.
It is among the more expensive best inversion table for the money (Giuseppe)
tables in the market with innovative design features for
outstanding convenience and results.
The very first thing there is to discover about the Exerpeutic Comfort Foam best inversion table consumer reports (Teddy)
Table is its cost.
Otra forma de clasificar la fimosis en adultos y a cualquier edad, es según su origen etiología de
forma que podemos encontrar fimosis de origen innato
y fimosis adquiridas a lo largo del desarrollo, de forma que podemos delimitar a la fimosis adquirida como
aquella que se presenta en un paciente que anteriormente
no padecía este problema.
my page; existe la fimosis femenina – blog.swaptylabs.com –
En el caso de la prepucioplastia se hace una abertura dorsal con cierre transversal en la franja de la piel.
my website – fimosis femenina wikipedia (Clarita)
Working out on an best inversion table [Shay] table develops proper abdominal/core muscles while supporting
the back to prevent injury.
Down there.” Think of being informed they don’t know exactly what is wrong with you and that they don’t have an option or treatment.
Feel free to surf to my homepage :: molluscum contagiosum diet [Tessa]
Hidradenitis suppurativa is commonly associated with smoking cigarettes, obesity, and enhanced hormones.
Feel free to visit my blog boils diet
First of all, it is essential to make sure that the best inversion table to buy – Kari, table is established correctly.
Gymnasts, scuba divers, skydivers and springboard scuba divers discover that best inversion table consumer reports find-tunes the
inner ear and the body to the inverted world.
I shrugged it off, figuring that the antibiotics would clear
it up as well as energetic scrubbing and I was wrong!!!!
Feel free to visit my web blog – hidradenitis suppurativa treatment (Thao)
Down there.” Picture being informed they have no idea exactly what is wrong with you which they do not have an option or treatment.
Have a look at my blog post … boils diet (Margery)
No te sorprendas si el chorrito al orinar sale en forma de spray
en lugar de en un chorro homogéneo durante los primeros días.
Have a look at my page :: fimosis infantil fisiopatologia ppt – Carmella,
Few owners expressed concerns about investing too much money on this best inversion table consumer reports (Leticia) table.
This self development definition psychology actuation leads to
success and happiness in each yoiur private and business life.
They use their expertise to devise and implement methods to improve the delivery of health net jobs rancho cordova (Hester) care services.
Greate pieces. Кeep posting such κind ߋf іnformation on үour site.
Ӏm really imprressed bʏ іt.
Hey tһere, Youu ɦave ԁоne a fantastic job.
І’ll ɗefinitely digg іt and
іn my ѵiew recommend tо mу friends.
I’m sure they ԝill bᥱ
benefited from tһіѕ web site.
Mү blog post yuui hatano (redclip.xyz)
I all the time used to read post in news papers but now as I am a user of internet
thus from now I am using net for content, thanks to
web.
Everyone has a budget plan, and it’s important to understand exactly what
your spending plan is if you’re wanting to use up best inversion tables consumer reports (Nona) therapy.
What I have ooffered is a list of non-public growth blogs that rank from the ‘largest’ with probaboy the most traffic to the ‘smallest’.
Feell free to visit my web-site – funny self development quotes – Suzanna
–
It triggers a mixture of red boil -like lumps, blackheads, cysts, scarring and channels in the skin that leak pus.
Check out my web-site: hidradenitis suppurativa diet recipes (Jorg)
Working out on an what is the best inversion table to buy [Elba] table supplies cardiovascular
fitness, versatility and strength.
Regular use of finest best rated inversion tables, Hiram, table naturally enhances the
posture of your spinal column helping you to obtain rid
of pain in the back permanently.
Hey there! Would you mind if I share your blog with my zynga group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Thank you
The castle was built by, and named for, John Hays Hammond, who in United States history
came second only to Thomas Edison for number of
patents granted for inventions. The level of noise can be frustrating
to adults who are engaging in other activities around the home.
Harris’ show will be based upon the UK variety show “Saturday Night Takeaway.
There are ton’sa llot more ideas for generating cash, but
what everyy single you select make positive it is at least enjoyable.
My weblog :: free affiliate website
Finally, surgery might periodically be required, specifically in pilonidal
cysts that recur, but also for hidradenitis suppurativa.
Stop by my page :: hidradenitis suppurativa treatment (Alda)
The majority of best inversion table to buy (Eliza) tables give you the ability
to pre-set your optimum inversion and have manages for safety.
More than 100 anatomy short articles feature medical
images and diagrams of the human body’s significant
systems and organs.
Stop by my blog post boils diet (Murray)
WOW just what I was searching for. Came here by searching
for Minecraft premium cheat
Mas a veces, los progenitores pueden hacerlo a la fuerza para evitar la operación de
fimosis y lo único que logran es que el pequeño sienta
dolor y se generen ciertas heridas que al cicatrizar impiden la retracción del prepucio adecuadamente.
Have a look at my web blog :: fimosis fotos reales (Florene)
En ocasiones la fimosis es provocada por un frenillo demasiado
corto,en estas situaciones la frenuloplastia podría solucionar el inconveniente.
my homepage :: fimosis en adultos recuperacion [Chandra]
La fimosis no me dejaba llevar una vida normal (en todo aspecto) y la circuncisión era
la solución y lo hice.
Have a look at my web blog – fimosis infantil imagenes (http://booksbyhagit.com/members/hellenprettyma/activity/48635)
The price is not on the lower variety but the best inversion table on the market (Pat) is plainly created with quality in mind.
Everything is very ooen with a really cleear explanation oof the challenges.
It was definitely informative. Your site is extremely helpful.
Thanks for sharing!
Feel free too visit my web site – mortgage bankers association conference 2014
The rate is not on the lower range but the best inversion table reviews, Moises, is clearly developed with quality in mind.
Preferably, the treatment needs to start as quickly as a boil is observed since early treatment may avoid later problems.
Also visit my homepage; hidradenitis suppurativa diet recipes (Joanne)
Hі! I’m at ԝкгκ
ѕᥙгfing aгοund yοᥙг ƅⅼօǥ
frԀοm mmү neѡ іpɦօne!
Jᥙѕѕt waƄtеɗ tο say
І lⲟѵе reaⅾing уοսг Ƅlߋǥ
and ⅼоօҝ fοгԝaгԁ tо aⅼⅼ уⲟսг ρⲟѕtѕ!
Қeeр սⲣ tһe sսρеrb աοгҝ!
Annual premiums for young people under the age of 26 who are healthy can be as low as $600, or a month-to-month cost of just
$50.
Feel free to visit my page – nutrition health articles recent (Ignacio)
Features: There are different types of best rated inversion tables (Rose)
tables having various inversion tables offer several inversion angles.
Este fimosis en pequeños y hombres se genera de forma aguda, la
cabeza es de color azul, puede haber necrosis.
my homepage :: fimosis infantil tratamiento
After the cause is identified, the physician decides if treatment is really
required.
Here is my blog hidradenitis suppurativa suggested diet, Blythe,
While there is no cure for hidradenitis suppurativa, you can deal
with your medical professional to deal with existing sores and
avoid brand-new ones.
My web page … molluscum contagiosum diet; Jerome,
Rachel, I have seen rather a dramatic improvement in my HS symptoms by following the Paleo diet plan.
My page – hidradenitis suppurativa diet recipes
An inversion table not only relieves best back inversion table
(Eulah) pain however it also provides several other health advantages.
The inversion table best rated – Epifania,
includes an adjustable pillow that enables users of different heights to discover a position that is most appropriate to their size.
Thank you for sharing your thoughts. I truly appreciate your efforts and I am waiting for your next write ups thank you once again.
I think that through self-experimentation and removal I have proven that
Hidradenitis Suppurativa is an autoimmune condition.
my weblog hidradenitis suppurativa diet recipes (Kendra)
This was simply a small effort from our side to increase
awareness about best inversion table amazon (Agueda) table.
I was recommended this website by my cousin. I am not sure whether
this post is written by him as no one else know such detailed about my
difficulty. You’re incredible! Thanks!
Si la piel prepucial baja de forma libre y no existe presión en erección no hay fimosis.
My web-site: fimosis infantil postoperatorio
If bust lift surgical treatment might be helpful, the pencil test is an easy way for a lady
to examine.
Feel free to visit my page: hidradenitis suppurativa treatment (Sabrina)
An impressive share! I have just forwarded this onto a coworker who was doing
a little homework on this. And he actually ordered
me lunch simply because I stumbled upon it for him…
lol. So let me reword this…. Thanks for
the meal!! But yeah, thanx for spending some time to discuss this subject here on your website.
Conforme algunas versiones, la fimosis impidió L.
XVI de Francia dejar encinta a su esposa durante los primeros siete años de su matrimonio.
my homepage :: fimosis en adultos tratamiento sin cirugia (http://www.jovey.net)
En adultos la fimosis se puede desarrollar
a consecuencia de infecciones, como las balanitis xeróticas (infección del bálano) balanopostitis (infección del balano y del prepucio), también por traumatismos.
My page fimosis en adultos pdf (Carl)
El tener fimosis puede ser extremadamente doloroso, mas no resulta necesario sufrir en silencio esta condición.
Feel free to surf to my blog – fimosis en adultos imagenes
Hidradenitis suppurativa can be itchy, but
is normally painful, and the lumps hurt if they are pressed.
Also visit my web page – hidradenitis suppurativa treatment (Freeman)
Those who develop regression of hepatitis C after completion of treatment will normally develop abnormal
liver enzyme levels once more.
My blog; boils diet – Darnell –
You must make sure that when you purchase the best inversion table to buy (Thanh) table, you must be able to get in and out of the arm-assists extremely comfy.
Weighing approximately 75 pounds, the IronMan Gravity 4000 inversion table best price;
Evonne, Table measures 26 x 65 x 49 inches.
El principal , y por esto, y mas incuestionable sintoma de fimosis en el grande es la incapacidad para retraer el capullo sobre el balano sobre toda a lo
largo de la ereccion.
Also visit my blog post; fimosis infantil wikipedia (Melisa)
La mayoría de las fimosis en mayores de tres años es consecuencia de una retracción temprana forzada, no recomendada, esta retracción forzada es consecuencia directa de la manipulación del pene por la
parte de los padres encargados de la higiene del pequeño.
Review my blog post – fimosis en adultos imagenes (Eula)
Surgical treatment terrifies me due to the fact that I see where individuals have it
come back in the same area, or even worse in other parts of their body.
Feel free to surf to my blog: boils diet
Eating the best foods will certainly assist cure it therefore will
believing the ‘ideal’ thoughts!
my web-site – hidradenitis suppurativa suggested diet
(Leonard)
Today, I went to the beach front with my children. I found a
sea shell and gave it to my 4 year old daughter and
said “You can hear the ocean if you put this to your ear.” She placed the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I
had to tell someone!
What’s up, its pleasant post about media print, we all be aware of media is a enormous source
of facts.
No es conveniente saltarse este punto poco atractivo:
podrías poner en riesgo la eficiencia de tu cirugía.
Look at my weblog … fimosis en adultos causas (Winifred)
Beaugé apuntó que las prácticas de masturbación infrecuentes, tales como empujar contra la
cama frotar el prepucio hacia adelante pueden ocasionar fimosis.
Feel free to surf to my web site fimosis fotos circuncision [Franklyn]
Third, there can be harmful causes of menorrhagia that require more immediate treatment.
Visit my web site :: folliculitis diet – Winfred –
Get vsgetables then you are complete of proteins from returning.
Feel free to surf to my homepage :: flat stomach exercises
The ankle locks make use of a spring-loaded pull pin to protect the user’s feet to the bottom of the ironman gravity 4000 inversion table best price (Gabriella).
En ocasiones la fimosis es provocada por un frenillo demasiado corto,en estas situaciones la frenuloplastia podría solucionar el inconveniente.
Feel free to surf to my website fimosis infantil imagenes
(Marquis)
Advocates of best inversion therapy table (Spencer)
therapy think they alleviate weight on the spinal disc and
nerve endings in the spinal column and construct the
areas between vertebrae.
Among the very first things you are trying to find in an best inversion therapy table – Charlotte, table is a complete range of
motion.
Hey just wanted to give you a quick heads up. The words
in your article seem to be running off the screen in Internet explorer.
I’m not sure if this is a format issue or something to do
with web browser compatibility but I thought I’d post to
let you know. The style and design look great though! Hope you get the issue solved soon.
Many thanks
Una fimosis en niños es mejor operarla a partir del tercer año, por el hecho de que en ciertos casos existe la posibilidad de
que el prepucio se estire de forma espontánea.
My site :: fimosis en adultos tratamiento sin cirugia – http://www.Casinogamingroom.com/,
Through routinely making use of an inversion table best
price [Mae] table,
you’ll be supplying much required nutrients and rejuvenation to all of your back discs.
Yo simplemente no podía dejar desaparecerá Web antes de lo que
sugiere que realmente el estándar Información una persona suministro en su huéspedes?
Se va a haber nuevo continuamente a fin de investigar verificación cruzada Buscar
mensajes nuevos
Back in the day, high heels were mostly worn to smart parties but today they have become a part of everyday wear.
Start out running slowly, so that your body gains a sense of balance before you take off at full speed.
For the month of October, Marie Claire readers have the exclusive opportunity to
make a difference in the global economy and eradication efforts of poverty simply with the
purchase of their very own red-bottom Louboutin.
Feel free to visit my page :: christian louboutin australia
That’s a vehicle payment.
My webpage … make money online legit
She wants to have surgery but I do not believe it would help and the doctors are no aid.
Here is my blog … hidradenitis suppurativa treatment (Johnnie)
La presencia de una fimosis en la edad infantil no suele representar la existencia de
problemas médicos.
my blog post :: fimosis fotos antes despues;
pomocdlamaksia.com,
It is well matched to novices or for making use of in combination with physiotherapy/chiropractic therapy.
My site: best rated inversion tables
This blog was… how do you say it? Relevant!! Finally I’ve found
something which helped me. Cheers!
Taking the best cheap inversion table (Denice)
to a 15-degree angle minimizes substantial amounts of anxiety on the
muscles.
I am adjusting now to feeling well as it has actually just been a couple of
days considering that attempting which is the best inversion table; Zack, table.
Maybe other stuff causes HS in other individuals, but I’m quite sure now that it’s diet-related.
my web site … molluscum contagiosum diet, Lavonne,
This table can old approximately 250lbs and carries out much the same as other best inversion tables consumer reports (Numbers) tables on the marketplace.
Fantastic website you have here but I was wondering if you knew
of any user discussion forums that cover the same topics talked
about in this article? I’d really love to be a part of community where I
can get advice from other knowledgeable individuals that share the
same interest. If you have any recommendations, please let me
know. Bless you!
whoah this weblog is great i really like studying your posts.
Stay up the good work! You know, a lot of persons are looking round for this
information, you can aid them greatly.
You truly want to make certain that you can move the best inversion table consumer reports (Gabrielle) in any direction you require and as far as you require.
The antibiotics kill bacteria on the skin whilst
the benzoyl peroxide is an antibacterial agent and also causes drying of the skin.
Take a look at my homepage; folliculitis diet – Lavina,
Another inversion table benefit is the great support you’ll obtain from the best inversion tables (Georgiana) community.
La fimosis es una alteración simple de reconocer,
pues quien la sufre nota que le resulta muy dificultoso
retraer el prepucio, y cuando lo procura siente dolor.
Here is my blog fimosis en adultos fotos (ice-man.ru)
When initially utilizing an inversion table, beginning with mild angles is the
best inversion table for the money, Rhoda, way to get the complete health advantages.
The Ironman Gravity 4000 inversion table is the best inversion therapy table;
Coral,-selling Ironman inversion table.
Time travel enables you to set a universal time that your e mail campaign arrives inn your recipient’s inboxes.
Here is my website … email marketing software companies
I suggest inversion table best price [Ermelinda] Treatment to all of my
clients as a proactive way to battle the effects of
gravity.
Preferred stock is a fine dripping liquid, mixed with the highest content of
vegetable glycerine possible for increased vapor production.
rrgch coach outlet online store Make Your Life Wonderful
And Exciting.Just Take It Go Out!Enjoy A Happy Weekend!Do Not Just Stay At Home!
coach outlet
Hello, i think that i saw you visited my blog thus i came to “return the favor”.I’m attempting
to find things to enhance my web site!I suppose its ok to use
a few of your ideas!!
Feel free to visit my page; twitter.com
Another best inversion table for the money (Jayden) table benefit is the
terrific support you’ll obtain from the inversion neighborhood.
Have you ever considered writing an ebook or guest authoring on other sites?
I have a blog based on the same subjects you discuss
and would really like to have you share some stories/information. I
know my readers would value your work. If you’re even remotely
interested, feel free to send me an e-mail.
La fimosis en niños es un problema usual que de manera frecuente se resuelve por
sí mismo.
Feel free to visit my weblog – fimosis infantil wikipedia (Lelia)
Matusiak Ł, Bieniek A, Szepietowski JC. Hidradenitis suppurativa significantly reduces quality
of life and expert activity.
Have a look at my weblog; hidradenitis suppurativa diet (Remona)
Hmm is anyone else encountering problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if
it’s the blog. Any suggestions would be greatly appreciated.
Cuando el nino tiene mas de un par de anos, han de estar pero atentos al cuidado
de los mismos y observar que todo esta adecuadamente,
aun es una gran idea hablar sobre el tema de la fimosis
con los pequenos a fin de que sepan también como cuidar esa zona, por servirnos de un ejemplo, a la hora del bano.
Feel free to visit my weblog fimosis infantil postoperatorio (Sibyl)
Plewig G, Steger M: Acne inversa (alias acne triad, acne tetrad
or hidradenitis suppurativa).
Visit my page – boils diet – Emery,
Hi there, of course this post is actually fastidious and I have learned
lot of things from it concerning blogging. thanks.
La mayoría de las fimosis en mayores de 3 años es consecuencia de una retracción temprana forzada, no recomendada, esta retracción forzada es consecuencia directa de la manipulación del pene por la parte de los padres encargados de la
higiene del niño.
Also visit my web site fimosis en adultos recuperacion (Karma)
Its like you learn my mind! You appear to understand so much about this, like you wrote the book in it or something.
I think that you simply can do with some % to power the message house a bit, however other than that, that
is fantastic blog. A great read. I’ll definitely be back.
Here is my weblog; cheap giuseppe zanotti shoes
Buut if you stick to youyr plans with persistence, you are
sure too achieve your goal. All of my diet coaches seem to think
this is thhe reason I am not successful. Not only that but drinking plenty of
water ensures all the waste and toxins are bbeing flushed
outt of your body. If you are someone wwho need
help losing weight, you first need to know where to go.
Here is my web-site; losing weight fast
Hi my friend! I wish to say that this article is amazing, great written and include almost all
important infos. I would like to peer extra posts
like this .
Here is my webpage: boosting testosterone levels
If some one wishes expert view about blogging then i advise him/her to visit this
blog, Keep up the pleasant work.
Hey There. I found your blog the use of msn. This is a very neatly
written article. I’ll make sure to bookmark it and come back to read
extra of your useful info. Thank you for the post.
I’ll definitely return.
Patients suffering from digestion problem are advised to drink
a cup of lemon juice before meals. Ten days of
protracted cough – only a small number of patients having viral bronchitis
develop protracted cough; and if a 48 hour trial
using bronchodilator does not show cough relief, the prescription of an antibiotic is quite
reasonable. Stopping this medication can cause heart attack
or ventricular arrhythmias and therefore a physician should be consulted about
stopping this medication.
my website treatment of chronic bronchitis in homeopathy
I like the valuable info you provide in your articles. I will
bookmark your weblog and check again here regularly.
I am quite certain I’ll learn lots of new stuff right here!
Good luck for the next!
Heya i am for the first time here. I came across this board and I find It really useful &
it helped me out much. I hope to give something back and aid others like you helped me.
Heya i’m for the first time here. I found this board and I in finding It truly helpful & it helped me out much.
I hope to present one thing back and help others such as you helped me.
Aw, this was an exceptionally nice post. Taking a few minutes and actual
effort to make a top notch article… but what can I say… I
hesitate a whole lot and never manage to get nearly anything done.
Great beat ! I wish to apprentice even as you amend your web site,
how can i subscribe for a weblog web site? The account helped me
a appropriate deal. I were a little bit familiar of this your broadcast offered
brilliant clear idea
Ahaa, its good conversation on the topic of this post here at this blog, I have read all
that, so now me also commenting here.
Hey there are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding expertise to
make your own blog? Any help would be greatly appreciated!
This is a fantastic blog. A great read. Is it OK to post on Tumblr?
Keep up the very good work! I’ll certainly be back.
Today, while I was at work, my cousin stole my iphone
and tested to see if it can survive a 25 foot drop, just so
she can be a youtube sensation. My iPad is now broken and she has 83 views.
I know this is completely off topic but I had to share it with someone!
From her, I discovered that holding home is just not
a very powerful factor on this planet.
Feel free to visit my site: tilbud rengøring
Very energetic post, I loved that a lot. Will there be a part 2?
Good day I am so thrilled I found your site, I really found you by accident, while I was researching on Yahoo for something else,
Anyways I am here now and would just like to say thank you for a incredible post and a all round
entertaining blog (I also love the theme/design), I don’t
have time to look over it all at the moment but I have bookmarked it and also included
your RSS feeds, so when I have time I will be back to read a lot more,
Please do keep up the awesome jo.
hey there and thank you for your information – I’ve definitely picked up anything new from right
here. I did however expertise a few technical issues using this website, as I experienced to reload the web site
lots of times previous to I could get it to load correctly.
I had been wondering if your web host is OK?
Not that I am complaining, but sluggish loading
instances times will sometimes affect your placement
in google and can damage your quality score if ads and marketing
with Adwords. Well I’m adding this RSS to my e-mail and can look
out for a lot more of your respective exciting content.
Ensure that you update this again very soon.
Look into my web page – ครีมเกาหลี
Research shows bulk incarceration had had a minimal impact on reducing violent crime,
and almost simply no impact at all since 1990.
Ꭰoes yⲟur website һave а contact ρage?
Ι’m Һaving ⲣroblems locating
it ƅut, I’d ⅼike tо ѕеnd үοu
an е-mail. I’vе ցot ѕome ideas fⲟr ʏοur blog ʏߋu might ƅе іnterested in hearing.
Either ԝay, ǥreat site and Ӏ ⅼоοk forward to ѕeeing it grow оνеr time.
mу site; GHD Sale
It really a funny thing that you can do lots of fun with two best mobile
OS with i – Phone Android app conversion system. Your opponents will drop items along the
way and you need to pick them up to keep going.
Start your conversation with the ‘Press and Speak’ button on the main
page.
Undeniably consider that which you stated. Your favorite justification seemed to
be on the internet the simplest factor to
understand of. I say to you, I certainly get annoyed whilst folks think about worries that they plainly
do not know about. You managed to hit the nail upon the top as
neatly as outlined out the whole thing without having
side effect , people can take a signal. Will likely be again to
get more. Thanks
Do you have any video of that? I’d want to find out some additional information.
my web blog Star Wars Uprising hack zip password
An outstanding share! I’ve just forwarded this onto a co-worker who was doing a little homework on this.
And he in fact ordered me dinner simply because I stumbled upon it for him…
lol. So let me reword this…. Thanks for the meal!!
But yeah, thanx for spending the time to talk about this subject here on your website.
I think the admin of this web site is actually working hard in support of his web page, because here every
stuff is quality based material.
Link exchange is nothing else except it is only placing the other person’s webpage
link on your page at suitable place and other person will also
do same for you.
Thankѕ for а marvelous posting! I really enjoyed reading іt, уοu may ƅᥱ a ցreat author.
ӏ ԝill bе sure tο bookmark ʏօur blog aand աill eventually сome Ƅack ⅼater οn. I ԝant too encourage yourself tօ continue ʏоur
ɡreat job, һave ɑ nice weekend!
mʏ weblog: video game porn
Hi, after reading this remarkable piece of writing i am also delighted
to share my know-how here with mates.
It’s hard to find knowledgeable people in this particular subject,
however, you sound like you know what you’re talking about!
Thanks
Normally I don’t learn post on blogs, but I would like to say that this write-up very pressured
me to take a look at and do it! Your writing style has been amazed me.
Thank you, quite nice article.
Also visit my webpage :: workout supplement
If you are going for most excellent contents like myself, only
visit this site everyday for the reason that it
provides feature contents, thanks
Look into my blog รับผลิตครีม
Hi are using WordPress for your site platform? I’m new to the blog world
but I’m trying to get started and create my own. Do you need
any html coding knowledge to make your own blog? Any help would be really appreciated!
I love your blog.. very nice colors & theme. Did you design this website yourself or did you hire
someone to do it for you? Plz respond as I’m looking to design my own blog and would like to find out where u
got this from. many thanks
you’re actually a good webmaster. The website loading velocity is incredible.
It kind of feels that you are doing any distinctive trick.
Also, The contents are masterpiece. you’ve performed a magnificent process in this subject!
Hurrah, that’s what I was exploring for, what a
stuff! existing here at this weblog, thanks admin of this website.
Greetings from Los angeles! I’m bored to tears
at work so I decided to check out your website on my iphone during lunch break.
I enjoy the info you present here and can’t wait to take a look when I get home.
I’m amazed at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyhow, superb site!
fantastic publish, very informative. I ponder why the other specialists of this sector don’t notice this.
You should proceed your writing. I am confident, you’ve a huge readers’ base already!
Hi, just wanted to tell you, I enjoyed this article. It was funny.
Keep on posting!
Thanks for another fantastic article. The place else could anyone get that kind
of info in such an ideal manner of writing?
I’ve a presentation subsequent week, and I’m on the search for such information.
Are you able to quickly tap into the information and
make a confident bet on the information that you have, probably not, but to be successful in sports betting, it is what you need.
On account of the large quantities of these bets, you can often locate odds that are a little “off” – to your benefit.
Most of the time, the dog doesn’t come in, but they hardly notice.
Hello, Neat post. There’s an issue together with
your website in internet explorer, may test this? IE still is the market leader and a big component of people will leave out your fantastic writing because of
this problem.
Nice post. I learn something new and challenging on sites I stumbleupon everyday.
It’s always useful to read articles from other
authors and use a little something from other websites.
It’s hard to find knowledgeable people for this topic,
however, you sound like you know what you’re talking about!
Thanks
hello!,I really like your writing very so much!
share we communicate extra approximately your article on AOL?
I require an expert on this area to resolve my problem.
Maybe that’s you! Having a look ahead to see you.
After all, you access to your guide online, and every time there is a change, you will be notified.
But if you want massive amounts of gold, even hitting the gold cap,
then farming and questing are a huge waste of time.
In the previous expansions, you had to gain some
levels to be able to buy the flying mount, but in Cataclysm you can get it for just
200 gold the second you get the game.
you furthermore may become completely to blame for your web
site and server. People on these sites are generally nice people and you would be
surprised how far you’d get by just being a genuinely good
person. Then you have to use these promotional
codes to get discounts and enjoy your shopping.
my blog; hostgator promo codes 2015
Highly energetic article, I enjoyed that a lot. Will there be a part 2?
Good day I am so excited I found your blog, I really found you by mistake, while I was researching on Bing for
something else, Regardless I am here now and would just like to say kudos for a fantastic
post and a all round thrilling blog (I also love the theme/design),
I don’t have time to browse it all at the minute but I have
book-marked it and also added in your RSS feeds, so when I
have time I will be back to read much more, Please do keep up the
great work.
May I just say what a comfort to find somebody that genuinely knows
what they’re discussing on the net. You definitely realize how to bring
a problem to light and make it important. A lot more people must read this and understand
this side of your story. I can’t believe you are not more popular because you surely possess the gift.
Feel free to visit my site – Log Cabins For Sale In North Carolina Mountains Cabins
We are a group of volunteers and oрening a brand
new scheme in oᥙr community. Υоur site
offered us ԝith useful іnformation tо ᴡork оn.
Υou һave ɗⲟne a formidable process
ɑnd օur еntire group shall ƅᥱ grateful tօ ʏօu.
Heree іѕ mу Һomepage – free hd porn
Wow, this post is ǥood, mʏ sister іѕ analyzing these things,
ѕօ ӏ am ɡoing tо
lᥱt кnoԝ Һᥱr.
mу wweb site – how to make money online
Evᥱry weekend і սsed tto
ggo tο ѕee tһіѕ web рage, because і wannt enjoyment, fⲟr tһe reason tɦat this tһіѕ web site conations truly fastidious funny information too.
Му webb pazge … odchudzanie
Jordan type offers launched technologically signed together with
the spurs characters lanner pour tools support legal
agreements, cluttered athletic shoes in utmost summer right after on fate, ones universal joint minor downward have come to
his owned by become a member of my colleagues, lately harmonizes with get started on putting on Jordan. Ace Fly2PE general look.
Also visit my web page … retro 5 for sale
Hi, i think that i saw you visited my blog so i came to “return the favor”.I’m trying to find things to enhance my site!I suppose
its ok to use some of your ideas!!
Hi there! This is my first comment here so I just wanted to give a quick shout out and tell you I really
enjoy reading your articles. Can you suggest any other blogs/websites/forums that cover the same topics?
Appreciate it!
This is really fascinating, You’re an overly professional blogger.
I’ve joined your rss feed and look forward to in the hunt for extra of
your excellent post. Also, I have shared your web site in my social networks
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back in the
future. Cheers
Great web site you have got here.. It’s hard to find high quality writing like
yours these days. I seriously appreciate people like you!
Take care!!
I used to be suggested this web site via my cousin. I’m not positive
whether this put up is written through him as no one else realize
such unique about my difficulty. You are amazing!
Thank you!
Way cool! Some very valid points! I appreciate you writing this post and the
rest of the website is very good.
With a lot of contending alternatives readily available on the market today, it’s hard to understand which best back inversion table
(Lucille) table is
right for you.
Which mеans yoᥙ cаn play wwith tɦe Ⲣixel Gun 3Ⅾ аnd ᥙsᥱ thiѕ receation hacker whether оr not yօu’reenjoying еither on iOS ⲟr yοur android.
Μу web-site: pixel gunn 3ɗ ack tool download no survey (http://tracie2holcomb7.bravesites.com)
Teeter Hang Ups is the very best Inversion table brand in this
model and the market is among their best
inversion tables consumer reports (Bonnie) productions.
Weight Ability up to 350 Pounds: I have not yet found any
single best inversion table on the market – Josef,
table that offers weight limitation approximately 350 pounds.
Extremely Resilient: This best fitness inversion table (Sybil) table is made from tabular steel which makes it highly durable.
Thanks for any other wonderful article. Where else could anybody get that kind of information in such an ideal way of writing?
I’ve a presentation subsequent week, and I am on the search for such information.
Great work! That is the type of information that are meant to be shared around the web.
Disgrace onn the seek engines for now not positioning this submit higher!
Comme on over annd consult with my wweb site .
Thanks =)
Check out my blog post :: http://www.thenewamericanroad.com
Generally speaking, you’ll be able to get a more detailed inversion table best price (Chet) table treatment experience if you have the ability to spend upwards
of $400+.
Finding what is the best inversion table to buy;
Ezequiel, best inversion table for your needs and scenarios does not have to be tough.
Rotation control permits you to select your best rated inversion table (Lois) angle according to your special
workout requirements.
I was curioius if you ever considereԀ
chanbging the page layout of үߋur site?
Ⅰtѕ ѵery wwll աritten; Ⅰ love ԝҺat youve ցot
tо ѕay. But maybe ʏоu could a ⅼittle moe іn thhe աay of content ѕο people ϲould connect wjth
it Ƅetter. Youve ցot аn awful ⅼot
οf text fοr οnly Һaving 1 օr 2 images.
Ⅿaybe ʏοu could space іt оut Ƅetter?
Ϻʏ website – how to make extra money
Since its establishment in 1981, the company has actually been developing diverse kinds
of ironman gravity 4000 inversion table best price (Boyd) items.
Shaking on a turnaround inversion table best price is an effective
technique for treating extending discs.
Hi there to every single one, it’s really a nice for me to pay a quick visit this web site, it includes important Information.
T Gravity 1000 best rated inversion tables Table is
the outright most popular of the Ironman Gravity of my customers
had this table and was tested by yours truly.
Keep in mind, inversion therapy is scientifically
proven to work and we’ve developed the very best inversion table – Everett, offer in the industry.
It is essential to adopt best rated inversion table therapy at
a steady pace – just like you would with any other kind of exercise.
NOTE: Kindly read the health warnings at the end of this short article prior to you
decide to purchase an best inversion therapy table (Essie) table.
Utilize an best inversion tables for back pain (Tabatha) table as
part of a treatment program recommended by your medical professional.
Using inversion therapy, the best inversion tables consumer
reports (Tam) Table can help reduce back anxiety by relieving pressure on your vertebrae discs.
We’ve taken all the best functions and combined them into what is the best teeter inversion table (Kourtney) I think about to be the very best inversion table on the marketplace today.
Advocates of inversion therapy think they mitigate
weight on the spine disc and nerve endings in the spine and construct the best inversion table – Thorsten – areas between vertebrae.
You’ll have the ability to carry out a variety of best inversion table for back
pain (Shawnee) table exercises, such as inverted
crunches, sit-ups and inverted squats.
The ironman gravity 4000 inversion table best price (Karen) is developed to hold the body easily
and safely while hanging upside down.
Hi! Would you mind if I share your blog with my
twitter group? There’s a lot of folks that I think would really appreciate your content.
Please let me know. Many thanks
The Ironman ATIS 4000 serves dual purpose: it can be made use of as an AB workout station and for best inversion table
reviews (Marco) therapy.
Ahaa, its fastidious conversation regarding this paragraph at this place at this
weblog, I have read all that, so now me also commenting here.
Supporters of best rated inversion tables (Roger)
treatment think they alleviate weight on the spine disc and nerve endings in the spine and construct the areas
in between vertebrae.
Users normally prefer an angle control to set the degree of best rated inversion table
[Tanja] which is not a function on the
Body Champ IT8070.
If some one needs to be updated with most up-to-date technologies afterward he must be pay a visit this
site and be up to date daily.
best inversion table consumer reports (Erica) works with
gravity to relieve pressure on the spine, thus bringing pain relief to
back discomfort victims.
Enhanced Posture; ironman gravity 4000 inversion table best price – Wilfredo
– Therapy assists to realign your spine, therefore enhancing your entire
body posture.
The table itself which is the best inversion table –
Shayne, covered with two-and-a-half inches of memory foam
and is significantly more comfy than its un-padded/lightly cushioned competitors.
Some users advise making basic modifications prior to mounting the which inversion table is best (Jeannine) and after that tweak the process after the ankles
are securely in the clamps.
Don’t waste any more money on Smashy Road: Wanted hack
that aren’t worth it. Moreover, with the change in design, developers will have to deal
with a totally different aspect ratio as well as fragmentation in i
– OS devices. You can also choose to set up your pitch in a variety of locales, including baseball stadiums, parks
and malls.
Users will certainly appreciate the addition of a push button near the manages that help a user spring back upright from full best inversion table for back pain.
Although what is the best teeter inversion table
(Kristin) majority
of inversion tables look extremely similar, they’re absolutely not all created equal.
The physician’s confirmation is necessary due to the fact that under specific medical-conditions you are not supposed to utilize the best inversion table for the money (Vanita)
table.
Through routinely making use of an best fitness inversion table (Joseph) table, you’ll be
supplying much needed nutrients and rejuvenation to all of
your back discs.
First off I would like to say terrific blog! I had a quick question that I’d like to ask if you do not
mind. I was interested to find out how you center yourself and clear your thoughts before writing.
I have had a tough time clearing my thoughts in getting my ideas out.
I do take pleasure in writing but it just seems like the first 10 to 15 minutes are generally wasted simply just trying to
figure out how to begin. Any recommendations or tips?
Thanks!
The Canon Power – Shot D10reviewed in the second article in this series
is quicker and the image quality is a little better too.
That question became the mission for Sony as they went about developing a mirrorless interchangeable lens compact camera to compete with the likes of the Panasonic GH1, the
Olympus PEN system and the Samsung NX10. The Micro Four Thirds class of cameras unlike others were designed in mind to
reduce the size of the camera yet provide the same quality and control expected from
an SLR.
My website; a digital camera is an example of a computer peripheral
I believe everything said was very logical.
However, consider this, what if you added a little information? I am not
saying your information isn’t good., but suppose you added a post title that makes people desire more?
I mean JavaScript Exercise – Social Software is a little plain. You might
glance at Yahoo’s home page and watch how they create post titles to get viewers to click.
You might add a related video or a picture or two to get
people excited about what you’ve written. In my opinion, it would
bring your posts a little bit more interesting.
Here is my blog post; wrinkle reducer
It is the best time to make a few plans for the future and it’s time
to be happy. I have read this submit and if I could I
want to counsel you some interesting things or tips.
Maybe you can write next articles referring to this article.
I want to read more issues approximately it!
An outstanding share! I’ve just forwarded
this onto a colleague who had been doing a little homework on this.
And he in fact ordered me breakfast simply because I discovered it for
him… lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanx for spending time to talk about this matter here on your website.
Check out my website: mineboard.tk (Ingrid)
Everything is very open with a precise clarification of the challenges.
It was truly informative. Your website is very helpful.
Thanks for sharing!
Hi would you mind letting me know which hosting company you’re working with?
I’ve loaded your blog in 3 completely different browsers and
I must say this blog loads a lot quicker then most. Can you recommend a good web hosting provider at a honest price?
Many thanks, I appreciate it!
Thanks for some other excellent post. The place else may just anybody get that kind of info in such a perfect way of
writing? I’ve a presentation subsequent week, and I’m at the search for such info.
It’s going to be finish of mine day, except before end I am reading this great piece
of writing to increase my know-how.
Today, while I was at work, my cousin stole my iPad and
tested to see if it can survive a 30 foot drop, just so she can be a youtube sensation.
My apple ipad is now broken and she has 83 views. I know this
is entirely off topic but I had to share it with someone!
Hello! This is kind of off topic but I need some guidance from an established blog.
Is it very hard to set up your own blog? I’m not very techincal but I can figure things
out pretty quick. I’m thinking about making
my own but I’m not sure where to begin. Do you have any tips
or suggestions? With thanks
It’s fantastic that you are getting ideas from this paragraph as well as from our argument made here.
wonderful issues altogether, you just won a logo new reader.
What could you suggest about your publish that
you made a few days in the past? Any positive?
Why visitors still use to read news papers when in this technological world the whole thing is presented on net?
my webpage web page [Maxwell]
I was extremely pleased to discover this page.
I wanted to thank you for your time for this
wonderful read!! I definitely savored every
little bit of it and i also have you bookmarked to see
new information on your website.
My page … Profit Genius
My spouse and I absolutely love your blog and find nearly all of your
post’s to be exactly what I’m looking for. can you offer guest
writers to write content for yourself? I wouldn’t mind creating a post
or elaborating on some of the subjects you write about here.
Again, awesome weblog!
magnificent points altogether, you just gained a new reader.
What could you recommend in regards to your put up that you just made a few days ago?
Any sure?
Visit my website – web page (Glory)
whoah this blog is excellent i really like reading
your articles. Stay up the great work! You realize, a lot of people are hunting round for this
info, you can aid them greatly.
Everyone loves it whenever people come together and share opinions.
Great site, keep it up!
This is very interesting, You are a very skilled blogger.
I have joined your rss feed and look forward to seeking more
of your magnificent post. Also, I have shared your web site in my social networks!
Organic coffee is harvested in soil that is more fertile because of crop rotation,so it
has morte nutrients to offer youu in your daily cup of Joe.
So her constant companion at the time was a Starbucks (I don’t speak Coffee
and never will thank-you-very-much) laege white chocolate mocha.
We, as growers of organic Arabica coffee beans, believe that if you want
to optimize your daily coffee consumption, organic Arabica beans are certainlyy tthe best
choice.
Hi there jut wanted to give you a quick heads up. The text in your content
seem to be running off the screen in Firefox.
I’m not sure if this is a formatting issue or something
to do with internet browser compatibility but I figured I’d post to let
you know. The style and design look great
though! Hope you get the problem fixed soon. Many thanks
Hello! I just wanted to ask if you ever have any issues with
hackers? My last blog (wordpress) was hacked and I ended
up losing a few months of hard work due to no data backup.
Do you have any methods to prevent hackers?
Incredible! This blog looks exactly like my old one!
It’s on a completely different subject but it has pretty
much the same page layout and design. Outstanding choice of colors!
At this time it looks like Movable Type is the top blogging platform
available right now. (from what I’ve read) Is that what you’re using on your blog?
my web blog – Knight of Cups nouveaux films gratuits
Please let me know if you’re looking for a article author for your blog.
You have some really great posts and I believe I would
be a good asset. If you ever want to take some off the load off,
I’d love to write some material for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Thank you!
Hey! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Cheers!
I enjoy what you guys are up too. Such clever work and reporting!
Keep up the amazing works guys I’ve included you
guys to blogroll.
Also visit my site Professor Andersen
Hello There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and return to read more
of your useful info. Thanks for the post. I will certainly return.
Hi, just wanted to mention, I liked this post. It was funny.
Keep on posting!
Heya i’m for the first time here. I found this board and I find It truly
useful & it helped me out a lot. I hope to give something back and help others like you helped me.
According to many of the rumors that have stated the i – Phone 5 is next
it would be released very soon. The i – Phone really does
have everything you need in something that fits into the palm of your hand: all
your music, all your contacts and the ability to find anything
you want with a few touches. Whether you want to transfer all i – Phone contacts from an old i –
Phone to a new i – Phone or send one contact to a friend who also has an i – Phone, this article will walk you
through how to do it.
Here is my blog :: coque
Good answer back in return of this query with real
arguments and telling the whole thing on the topic of that.
Feel free to visit my blog … Binary Reserve System
Link exchange is nothing else however it is just placing
the other person’s website link on your page at suitable place and other person will also do similar for you.
Its such as you read my mind! You seem to know so much about this,
like you wrote the e-book in it or something. I think that you just could do with a
few % to power the message house a bit, but instead
of that, that is fantastic blog. A great read.
I will definitely be back.
Inquiries concerning the Financial institution’s social media strategy should
be forwarded to the Bank’s Social Media Supervisor.
Awesome post.
If some one needs expert view concerning blogging after that i recommend him/her
to pay a quick visit this web site, Keep up the fastidious work.
Does your site have a contact page? I’m having problems locating it
but, I’d like to shoot you an email. I’ve got some suggestions for your blog
you might be interested in hearing. Either way, great website
and I look forward to seeing it expand over time.
Theгe is definately a ǥreat deal tօ
find оut about tҺіѕ topic.
I гeally ⅼike аll tɦᥱ рoints yοu made.
Аlso vvisit mʏ webpage iPorn
Ꮋi! This is my fіrst visit tߋ үοur blog!
Ꮤе ɑге ɑ collection оf volunteers annd
starting ɑ neա project іn ɑ community in tҺᥱ ѕame niche.
Υߋur blog providded ᥙѕ beneficial іnformation tⲟ
ᴡork оn. Yoou һave donne a extraordinary job!
Also visit mу blog how to earn money online
Definitely believe that which you said. Your favorite justification seemed to be on the net the simplest thing to be aware of.
I say to you, I definitely get annoyed while people think about worries that they
plainly don’t know about. You managed to hit the nail upon the
top and defined out the whole thing without having side effect
, people can take a signal. Will likely be back to get more.
Thanks
My brother suggested I might like this blog. He was
totally right. This post actually made my day. You can not imagine simply how much time I had spent for this information! Thanks!
It’s actually a great and helpful piece of information. I’m happy that you shared
this helpful information with us. Please keep us informed like this.
Thank you for sharing.
Feel free to visit my site; cheap ugg boots
As a physical part of the i – Phone that you are in contact with quite a bit
there can be a number of problems that you
may encounter with the Home button. We don’t own these computers, and we probably aren’t allowed to install software on them.
The weather information that these apps provide is reliable because
it is taken from trustworthy sources.
Also visit my blog post :: coque iphone 5s
Thank you for any other wonderful post. Where else may just anyone get that type of information in such an ideal manner of writing?
I’ve a presentation next week, and I am at the look for such information.
I’m curious to find out what blog platform you’re utilizing?
I’m experiencing some minor security problems with my
latest site and I would like to find something
more safe. Do you have any suggestions?
Terrific post however , I was wanting to know if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little bit further.
Many thanks!
Can I simply just say what a comfort to discover someone who actually understands what
they’re talking about on the net. You actually realize how to
bring a problem to light and make it important. More and more people ought to check this out and understand
this side of the story. It’s surprising you aren’t more popular because you definitely have the gift.
Hey! This post couldn’t be written any better! Reading this post
reminds me of my good old room mate! He always kept chatting about this.
I will forward this article to him. Pretty sure he
will have a good read. Many thanks for sharing!
Folio style covers come in lots of finishes and materials.
But then of course the other 4 cases we listed are
equally great as well. The company, based in Barnsley, works on a
‘pay as you go’ basis, providing breakdown cover when customers need it, rather
than making them pay for an extensive insurance plan.
Look at my page coque iphone 5
Agar io is an exciting strategy based multiplayer sport out there on Home windows, iOS and Android platforms.
Hi there, everything is going well here and ofcourse every one is sharing information, that’s truly
excellent, keep up writing.
Thanks for sharing your thoughts. I truly appreciate your efforts and
I will be waiting for your next post thank you once again.
I’m really impressed with your writing skills as well as
with the layout on your weblog. Is this a paid theme or
did you customize it yourself? Either way keep up the nice quality writing,
it’s rare to see a great blog like this one nowadays.
Everything is very open with a precise clarification of the issues.
It was truly informative. Your website is very helpful.
Thank you for sharing!
You ought to take part in a contest for one of the greatest
sites on the net. I most certainly will highly recommend
this website!
Howdy! This post couldn’t be written much better!
Going through this article reminds me of my previous roommate!
He always kept preaching about this. I am going to send this post to him.
Fairly certain he will have a very good read. Thank you for
sharing!
I’d like to find out more? I’d like to find out more details.
Feel free to visit my site webpage (Darci)
Very energetic post, I liked that a lot. Will there be a
part 2?
And then, when the enemies are crippled by the attack, a Wizard can make use of abilities like Arcane Torrent and Meteor to rain down even more devastating damage on his foes.
His skills do not end there however as not just does he
forge the tools but the artisan Haedrig is likewise extremely competent in the repair of your equipped products.
Covetous has the ability to utilize the power of gems to benefit any type of piece of equipment in your inventory.
Hi, itts nice post concerning media print, we all know media is a impressive source of data.
My page movies
Attention is needed on account of each monster
would not want the similar kind of food and we must always choose his meals
strategically.
Hmmm it appears ⅼike yоur siite ate mу first comment (іt waѕ super ⅼong) sso Ӏ guess І’ll јust ѕᥙm
it uр աɦаt Ι Һad
ѡritten and ѕay, Ӏ’m thoroughly
enjoying ʏоur blog. Ι as ԝell аm an aspiring blog blogger but I’m ѕtill neѡ tⲟ everything.
ᗪо ʏߋu have any helpful hints fοr first-time blog writers?
I’ⅾ Ԁefinitely aopreciate іt.
Нere iss mү blog post; iPorn
That’s the good trighger that gold hack iis smply what many gamers using inside Monster Legends.
Hey I am so delighted I found your webpage, I really found you
by error, while I was researching on Yahoo for
something else, Nonetheless I am here now and would just like to
say kudos for a tremendous post and a all round
thrilling blog (I also love the theme/design), I don’t have time to read it all at the moment but I have book-marked it and also added your RSS feeds, so when I have
time I will be back to read a lot more, Please do keep up the excellent b.
I just like the valuable information you supply to
your articles. I will bookmark your blog and take a look at
once more right here frequently. I am slightly sure I
will be informed a lot of new stuff right here!
Best of luck for the next!
It’s an remarkable piece of writing in support of all the
internet people; they will get advantage from it I am sure.
Aw, this was an extremely good post. Finding the time and actual effort to produce a superb article… but what can I
say… I put things off a whole lot and don’t
manage to get nearly anything done.
Here is my blog – Millionaires Blueprint
Attractive section of content. I just stumbled upon your web
site and in accession capital to assert that I acquire actually enjoyed account your blog
posts. Anyway I will be subscribing to your augment and even I
achievement you access consistently rapidly.
They firstly try to contact the defaulter over
phone; even, this doesn’t work, they will visit them officially possibly
at their home or office Also, carefully consider the conditions before signing a loan agreement!
Payday loans are of help for many people to acquire through to
its next cash advance, when their own budget
foliage them a little bit short of the funds needed If you gave
on the first time about, give it one more go
Feel free to surf to my site … http://networkadvertising.org/
Really no matter if someone doesn’t understand afterward its
up to other people that they will help, so here it happens.
I pay a quick visit day-to-day a few websites and blogs to
read articles or reviews, except this web site gives feature based articles.
Hello to every one, the contents existing at
this web site are in fact awesome for people knowledge,
well, keep up the good work fellows.
Valuable information. Fortunate me I found your web site accidentally, and I am stunned
why this twist of fate didn’t happened earlier! I bookmarked it.
I really like your blog.. very nice colors & theme.
Did you make this website yourself or did you hire someone to do it for you?
Plz respond as I’m looking to design my own blog and would like to
know where u got this from. kudos
I was recommended this web site by my cousin. I am not sure whether this post
is written by him as no one else know such detailed about my problem.
You are amazing! Thanks!
Unquestionably believe that which you said. Your favorite justification appeared to be
on the internet the easiest factor to bear in mind of.
I say to you, I definitely get irked while other folks think
about issues that they plainly don’t recognize about. You controlled to hit the nail upon the highest
and also outlined out the entire thing without having side-effects
, other people can take a signal. Will likely be
again to get more. Thanks
Remember, there are many to choose from and the best are those geared toward assisting low to medium income families by offering smaller down payments, no down payments,
lowered closing costs and reduced interest rates. There really is no better time to buy a first home,
a bigger home, or even start investing in homes to use as rentals for sustained income and wealth building.
The proven facts of this anti-virus program
made it adoptable over a range of computer users.
Because of this, Dallas, TX mortgages are now being investigated
by new home buyers. In fact, because of that, Denver was recently recognized for being #1 in the nation for shortest time on market.
They help out of town investors keep their properties productive.
The show is looking for high energy individuals that
are in the process of buying a new home, condo, or townhome.
This is to avoid overpricing your home and having it stay on the market for too long.
Using text messaging as a way of communication might seem insensitive or not exciting.
So do your homework and search at the source itself. If an individual or couples desire to meet
the criteria for a home buyer program, then the history of rental payments will also be considered.
With his outstanding negotiating skills, as well as extensive experience in this industry, he is the only person that you need to assist you in finding your dream home in East
Hampton.
Can I simply say what a comfort to discover somebody who truly knows what they are discussing on the
web. You actually realize how to bring a problem to light and make it important.
A lot more people ought to read this and understand this side of your story.
It’s surprising you’re not more popular since you most certainly possess the gift.
Here is my web page: California Vacation Guide Romantic California Vacation Spots
Excellent post. I certainly appreciate this site.
Continue the good work!
Once you buy, the person (guru) selling the product knows right away you are a buyer.
I was able to stay away and do traditional, conventional type financing for
people. In particular, it looks as if new homebuyers will make up a lion’s share of the market
as winter turns into spring. Because of this, Dallas, TX mortgages are now being investigated by new home buyers.
The quick round up of the feature will be easily
furnished here, and this is the point to mention that there is no need to get worried from where the tool will
be downloaded. I think you are going to go get a second opinion, maybe even a third.
Great blog you have here but I was curious about if you knew of any discussion boards that cover the same topics
discussed here? I’d really love to be a
part of group where I can get feedback from other knowledgeable people that share the same interest.
If you have any recommendations, please let me know.
Kudos!
Also visit my site … website (Hollis)
Very nice post. I absolutely appreciate this website.
Continue the good work!
I am really loving the theme/design of your web site. Do you ever run into
any browser compatibility issues? A couple of my blog visitors have complained about
my site not operating correctly in Explorer but looks great in Opera.
Do you have any solutions to help fix this issue?
If үоu would ⅼike tto ɡᥱt much from
tҺis article then youu Һave tօ apply these strategies tօ yߋur աοn weblog.
Review my web-site; Paid Surveys
Tһanks fօr ɑnother excellent article.
Wɦere еlse may ϳust ɑnybody get tҺat type οf
іnformation iin ѕuch аn ideal
means оf writing? Ι’ᴠе а presentation neⲭt ѡeek, and I am оn tһе
search fօr ѕuch info.
Ꮋere is mу web-site iPorn
Normally I do not read post on blogs, but I wish to say that this
write-up very pressured me to try and do so!
Your writing taste has been amazed me. Thanks, quite nice article.
Does your blog have a contact page? I’m having problems
locating it but, I’d like to shoot you an e-mail.
I’ve got some creative ideas for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it improve over time.
This is really interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your fantastic post.
Also, I’ve shared your web site in my social networks!
I like the helpful information you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I’m quite certain I will learn a lot of new stuff right here!
Good luck for the next!
Please let me know if you’re looking for a article writer
for your weblog. You have some really great articles and I think I would be a good asset.
If you ever want to take some of the load off, I’d love to write some material for your
blog in exchange for a link back to mine.
Please blast me an email if interested. Kudos!
Hi, i think that i saw you visited my blog so i came to “return the favor”.I am trying to find things to improve my site!I suppose
its ok to use a few of your ideas!!
Hello there! This is kind of off topic but I need some help from an established blog.
Is it very hard to set up your own blog? I’m not very techincal but I can figure things out pretty
quick. I’m thinking about making my own but I’m not sure where to begin. Do you have any tips or suggestions?
Thanks
Here is my homepage … Moonwalkers film entier
Excellent article. Keep posting such kind of info on your page.
Im really impressed by your site.
Hi there, You’ve performed an excellent job.
I’ll definitely digg it and in my view recommend to my friends.
I am sure they will be benefited from this
site.
Nice replies in return of this difficulty with real arguments and
describing the whole thing regarding that.
I seriously love your website.. Excellent colors & theme.
Did you build this website yourself? Please reply back as I’m looking to create my own personal website and want to find out where you got
this from or what the theme is named. Thank you!
This piece of writing presents clear idea for the new users of blogging, that in fact
how to do blogging.
I don’t even know how I ended up here, but I believed this submit used to be great.
I don’t recognise who you might be however definitely you’re going to a famous blogger if you aren’t already.
Cheers!
Although there are 2 chapters, there is the only one which
can be opened out and experienced. One of the tasks is to get Simoleons while building your city.
Any type of terrain can be found: deserts, mountains, hills, plains
and many others.
my web page: minecraft story mode free download (http://www.facebook.com)
Read the words backwards, this will help to take away the
meaning of the words, increasing the chance of spotting errors.
Below is a list of the most prominent independent
competitions, their deadlines, and where you can find out
more about them. Your academic work would be incomplete without the construction of an engaging criminology essay.
Excellent post! We are linking to this particularly great post on our website.
Keep up the good writing.
I seriously love your site.. Great colors & theme. Did you develop this website yourself?
Please reply back as I’m wanting to create my own personal blog and
would like to know where you got this from or what
the theme is named. Thanks!
I am sure this piece of writing has touched all the internet people,
its really really pleasant post on building up new web site.
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I’m quite sure I will learn many new stuff right here!
Best of luck for the next!
Have a look at my page; Samaritan System
I like the valuable information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I am quite sure I’ll learn a lot of new stuff right here! Best of luck
for the next!
Hello, i read your blog from time to time and i oown a similar
one and i was just wondering if you get a lot of spam comments?
If so how do you prevent it, any plugin or anything yyou can recommend?
I get so much lately it’s driving me mad so any support
is very much appreciated. http://www.hughescatering.com
whoah this weblog is magnificent i like reading your posts.
Keep up the great work! You already know, many persons are looking round for this
information, you can help them greatly.
What’s up, I would liκe tο subscribe fⲟr ths blog to օbtain hottest updates, sso where can і dо іt
ρlease ɦelp.
Lօօk aat my web ρage how to make money
These loans are offered with many different cash lenders in england.
Breach of comfort risk insurance plan supplies security officer companies with peace of
mind through being accused of misusing surveillance techniques or
programs. The actual authorities took notice on this,
and are contemplating coming out with an insurance plan to
safeguard shopper interest?
Also visit my blog post; http://miibeian.gov.cn/bigtry/social12/
Hey there! Would you mind if I share your blog with my zynga
group? There’s a lot of people that I think would really
appreciate your content. Please let me know. Thanks
This is a topic that’s near to my heart…
Cheers! Where are your contact details though?
Here is my web page jobs in dc
Do you mind if I quote a few of your posts as long as I provide credit and sources
back to your blog? My blog site is in the exact same niche as yours and my visitors would definitely benefit
from some of the information you present here.
Please let me know if this okay with you. Cheers!
Please let me know if you’re looking for a author for
your blog. You have some really great articles and
I feel I would be a good asset. If you ever want to take some of the load
off, I’d really like to write some material for your blog in exchange for
a link back to mine. Please send me an e-mail if interested.
Regards!
Here is my homepage Visit Webpage (http://thegioiflashgame.com/profile/imastephens)
I blog frequently and I genuinely appreciate your content.
The article has really peaked my interest.
I’m going to book mark your blog and keep checking for new details about once per
week. I subscribed to your RSS feed as well.
Fantastic website you have here but I was wanting to know if you knew of any message boards that cover the same topics discussed in this article?
I’d really love to be a part of community where I can get suggestions from other knowledgeable people
that share the same interest. If you have any suggestions, please
let me know. Appreciate it!
This information is worth everyone’s attention.
When can I find out more?
However, if you are looking at a preowned home, buy one from
someone who is moving into a bigger house, got a huge
promotion and is moving, or has won the lottery and is buying a villa in Tuscany.
Norris loved it and would happily sleep in there too,
which was very strange for him he loves the warmth. s something i
have on my own walls which give character and also shows your
personality depending on the colour scheme you have in and around your home.
Feel free to surf to my homepage :: menuiserie alu
Basically it’s crucial that you choose a company that can deal with homes financing help in the course of your own shopping process of your property.
Today I will tell you why I am thinking about this type of house system.
The best mix to choose depends on two factors; the type
of work to be carried out and the finished groundwork required.
my blog; fenêtres
When some one searches for his essential thing,
so he/she wants to be available that in detail, therefore that thing
is maintained over here.
Hello Dear, are you genuinely visiting this website daily, if so afterward you will without doubt obtain fastidious
knowledge.
Thank you for the good writeup. It in fact was a amusement
account it. Look advanced to more added agreeable from you!
By the way, how could we communicate?
My page … Belstaff Gold
You have made some really good points there. I looked
on the internet to find out more about the issue and found most people will go along with your views on this website.
Excellent beat ! I would like to apprentice while you amend your website, how could i subscribe for
a blog website? The account aided me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided bright clear concept
I am not sure where you are getting your info, but good topic.
I needs to spend some time learning much more or understanding
more. Thanks for great information I was looking for
this information for my mission.
Besides cutting several holes on knitted
sweaters and eye-catching tassel red shoes, Vivienne Westwood didn’t used to much flamboyant ways this
season. You don’t want to look like you are attending a funeral.
Tights are an essential part of your winter wardrobe and can often be warmer than your everyday trousers.
To add functionality and flair to your wardrobe, you can pair any one of these jeans or shorts with a Miss Me top.
If you choose the most appropriate one, it will choose the stretches
for you. When you sit with your jewellery designer to design your handcrafted jewellery take their advice as to the designs
and style but remember that this is your special day so have your
own input into the design.
Also visit my web-site :: black dress and boots pictures
By sharing your products’ photographs on Instagram that can be purchased at cost-effective value,
you can get many of Instagram individuals.
My web blog … get instagram followers free no download
Hmm it seems like your blog ate my first comment
(it waas super long) so I guess I’ll just sum it up what I submitted and say,
I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m
still new to the whole thing. Do you have any points for beginner blog writers?
I’d really appreciate it.
I don’t even understand how I stopped up right here, but I thought this put up was good.
I don’t recognize who you might be but definitely you’re going to a famous blogger for those who aren’t
already. Cheers!
Nice blog here! Also your site loads up very fast!
What host are you using? Can I get your affiliate link to
your host? I wish my website loaded up as fast as yours lol
Hi i am kavin, its my first time to commenting anyplace, when i read this post i thought i
could also make comment due to this brilliant piece of writing.
If you want to save money on alarm systems or CCTV then you
can use simple home lighting ideas and downlights to make the house or building appear occupied.
one of the most important factors in building a house is
choosing the perfect location. Components such as the kitchen, bathroom, cabinets, dividing walls
and stairs (if needed) can all be built outside of the structure.
my web-site … fenetres pvc
Currently you can find finance institutions worldwide are working appropriately
to aid the clingy people and agencies with various forms of mortgage
loan amenities. Wall materials that are dense and heavy,
like bricks, suck up heat and hamper its conveyance through the walls.
Low income buyers must not have income equal to more than fifty percent (50%) of
the average median income for the area where they
are building their home.
My webpage :: baie vitrée coulissante
Do you have a spam problem on this site; I also am a blogger, and I
was wanting to know your situation; many of us have developed some nice methods and we
are looking to exchange solutions with others, be sure to shoot me
an e-mail if interested.
Currently you can find finance institutions worldwide are working appropriately to aid the clingy people and agencies with
various forms of mortgage loan amenities. For obvious reasons this is one of the most important steps.
The crown has developed a program in 1998 called the Home Owners Protection Office.
Feel free to visit my page :: baie vitrée
Heya i am for the primary time here. I came acrss this board and I find It truly helpful
& iit heloped me out a lot. I am hoping tto give one thing back and help others such as you aided me.
http://www.jwrg.org
Woah! I’m really enjoying the template/theme of this site.
It’s simple, yet effective. A lot of times it’s challenging to get that “perfect balance”between user friendliness and
visual appeal. I must say you have done a amazing job with this.
Additionally, the blog loads very fast for me on Chrome.
Outstanding Blog!
For most up-to-date news you have to pay a quick visit world-wide-web and on internet
I found this website as a most excellent web page for most recent updates.
Hello there! Quick question that’s entirely
off topic. Do you know how to make your site mobile friendly?
My web site looks weird when viewing from my iphone.
I’m trying to find a template or plugin that might be able to fix this
problem. If you have any recommendations, please share.
With thanks!
Heya i am for the first time here. I came across this board
and I in finding It truly useful & it helped me out a lot.
I am hoping to present one thing back and aid others such
as you aided me.
Wonderful blog! I found it while searching on Yahoo News. Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
Hello There. I found your blog using msn. This is an extremely well written article.
I’ll make sure to bookmark it and return to read more of your useful information. Thanks for the post.
I’ll definitely return.
You should use this Clash of Clans defend to build your buildings up due to the
fact it is not going to last permanently.
Feel free to surf to my web blog – ifile clash of clans hack gold – athousandfold.net –
Hello there! This post could not be written any better!
Reading through this post reminds me of my good old room mate!
He always kept talking about this. I will forward this page to him.
Pretty sure he will have a good read. Thanks for sharing!
Fantastic goods from you, man. I have understand your stuff previous to and you’re just too wonderful.
I actually like what you’ve acquired here, certainly like what you are stating and the way in which you say
it. You make it enjoyable and you still care for to keep it smart.
I can’t wait to read far more from you. This is really a terrific site.
It’s tгuly verry complex in tҺіѕ full
ߋf activity life tо listen news οn Television, thus I only սsᥱ ᴡorld wide web for tɦat reason, annd
take tɦе latest news.
Review mү webb site :: iPorn
Be smart and strategy it nicely prior to you develop.
And more experienced buyers may know more about the asking price than you do
‘ whether it’s too high or non-negotiable. But one thing that should
never halt the progress of building work is having the wrong type of concrete,
especially when there are companies such
as these concrete providers who are able to supply a wide range
of concrete Welwyn to a variety of customers.
Feel free to surf to my blog post; volet roulant (http://www.quelvoletroulant.org)
I do believe all of the concepts you’ve presented to
your post. They’re really convincing and can certainly work.
Still, the posts are too short for newbies. May just you please
prolong them a bit from subsequent time? Thanks for
the post.
Oh my goodness! Awesome article dude! Thank you so much, However I
am experiencing issues with your RSS. I don’t understand the reason why I cannot subscribe to it.
Is there anyone else having the same RSS problems? Anyone that knows the solution can you kindly
respond? Thanx!!
Your means of telling everything in this paragraph is in fact nice, all be able to
easily understand it, Thanks a lot.
Just want to say your article is as amazing. The clearness in your post is just nice and
i could assume you’re an expert on this subject. Well with your permission let me to grab your
RSS feed to keep updated with forthcoming post.
Thanks a million and please continue the enjoyable work.
My brother recommended I may like this website. He used to be entirely right.
This post actually made my day. You cann’t imagine just how much time I had
spent for this information! Thank you!
This post presents clear idea in favor of the new users
of blogging, that genuinely how to do blogging.
I’m not that much of a internet reader to be honest but your
blogs really nice, keep it up! I’ll go ahead and bookmark
your website to come back in the future. Cheers
Hi, everything is going sound here and ofcourse
every one is sharing information, that’s in fact good,
keep up writing.
The Body Power IT9910 has 3 inversion table best
(Burton)
settings that are managed by both a strap and a yellow safety bar.
The manages are used as take advantage of to
gradually press back and begin the table inversion (Monique) process.
You have to inspect these and numerous other functions
prior to buying the top rated inversion table (Lloyd) table.
Ahaa, its good conversation concerning this article here at this weblog,
I have read all that, so at this time me also commenting
at this place.
Inversion tables range anywhere from the unsafe and low-quality Ebay and
Walmart tables which normally sell for $100 approximately.
Also visit my webpage :: eliminate back pain [Agnes]
The table inverts up to 180 degrees, supports approximately
300 pounds, and accommodates users with height varying
from 4’10” how to help back pain at home (Phoebe) 6’6″.
The top rated inversion table (Howard) Table loosens stiff muscles and recovers a sense of balance to your body.
If you want to save money on alarm systems or CCTV then you can use simple home
lighting ideas and downlights to make the house or building appear occupied.
The painter applies paint economically, in order to avoid any wastage and decides the
kind of paint according to home-owner’s budgets.
According to the Greenville County codes in South Carolina, permits must be
obtained whenever “a new building is constructed, structural changes made within a building or additions to existing structures.
Here is my weblog; fenetres
The Teeter EP 960 inversion table utilizes tethering straps to manage variety of motion.
Also visit my web site; back therapy equipment (Ismael)
Raise your head, shoulders and upper back pain relief exercises at
home (Warner) up off the table; you should feel a
contraction in your abs.
Hi there friends, its impressive article on the topic of educationand
fully explained, keep it up all the time.
Long straight driveways that end at the house, or roads that stop at the house,
are another problem, but can be corrected with plants or mirrors.
So when I look for chicken house plans, I usually look for ones that offer
step-by-step instructions and also look to see if any other newbies had
success with it. It shows the setting of your house on your overall property.
My site :: porte blinde
Excellent beat ! I would like to apprentice at the same time as you amend your website, how could i subscribe for
a blog web site? The account helped me a appropriate deal.
I have been tiny bit familiar of this your broadcast offered bright clear
concept
As per their choice, parents also can search for Presidium Dwarka and can apply to the schools by filling up the application forms online.
During a house building or remodeling project, it all
adds up in terms of cost, however, so as the homeowner, think about
hardware before you order your interior, prehung doors.
In Germany, just to do an example as soon as near, we
need only to choose our house and all the work beyond will be due by the firm.
My site menuiseries alu
Inversion eases pain and discomfort in the best cure for back pain – Kathi, caused by long term pressure on vertebrae, intervertebral discs, element joints and pinched
nerves.
The Teeter Hang Ups 950 what is a inversion table Table provides premium functions
to improve convenience and efficiency.
It is among lose the back pain [Noble]
more pricey inversion tables in the market with advanced design features for exceptional convenience and results.
Utilized correctly, electric inversion table – Richard, tables present little risk, although care ought to always be exercised.
Thanks very interesting blog!
Another uncomplicated way is on line application strategy this requires anyone to
go to the world-wide-web and need so that you can fill easy application form there.
Marrying a person who has student loans is going to influence
your lifestyle in terms of huge premiums that reduce joint family spending
It is always greatest for you to software ahead and
already have a completely new family price savings
intended for all these expenditures, but it’s sometimes merely unrealistic?
Here is my webpage :: Geocities.com
For this trigger, many enrollees flip to personal
student loans to pay for the distinction
You’ll find four key payment approaches in our retail outlet for
Guild Conflicts 2 Precious metal. To put on, you will need to develop a form referred to as a SF500
and mail it for the Benefit Middle of the town dealing with this
page code space, the varieties can be obtained your Local Jobcentre And also office and are generally issued by using a prepaid mailer, addressed towards the correct
Profit Centre.
Have a look at my weblog :: wikipedia.org
My spouse and I stumbled over here different web
page and thought I might check things out. I like what I see so
now i’m following you. Look forward to looking into your web page again.
Hi, i think that i saw you visited my blog thus i came to return the favor?.I am
trying to in finding issues to improve my web site!I guess
its good enough to make use of a few of your concepts!!
Remember, inversion therapy is clinically proven to work and we
have actually developed the very best cure for back pain (Aretha) offer in the
industry.
Hey! Someone in my Myspace group shared this website with
us so I came to take a look. I’m definitely enjoying the
information. I’m bookmarking and will be tweeting this to my followers!
Wonderful blog and great style and design.
Here is my homepage: Elite Gold Profits
Inversion tables are perfect when in excellent health
and no medical problems exist.
My blog post :: back therapy equipment; Curt,
This is a topic that’s near to my heart…
Cheers! Exactly where are your contact details though?
The use of what is inversion therapy – Phillipp – therapy
may assist promote and invigorate a sluggish and overly-taxed lymphatic system.
Having a good concept isn’t enough to start a business that will last.
This has increased the demand of architects for designing housing plans of residential houses also.
Give the sizes to your architect to incorporate on the
plans.
my weblog: volet battant bois
You can easily simply conveniently have it individualized to match your personal choice.
A responsible builder will have public liability insurance.
Before anything else, pay attention to the land itself.
My site: baies vitrees coulissantes alu (http://www.123baievitree.net)
The main features of its popular inversion table, Teeter Hang Ups EP-550 Sport Inversion Treatment Table, are
listed below.
Here is my web page :: best cure for back pain (Tom)
“With consumers seeking to enhance quality of life, beauty, great changes have taken place. First off, you could be forgiven for assuming that you are staring at a sewing machine if it weren. Find out the shining oven with all the food particles removed out of it.
my blog post – turkey fryers
Hello there! I know this is kinda off topic however , I’d
figured I’d ask. Would you be interested in exchanging links or maybe guest writing
a blog post or vice-versa? My blog addresses a lot of the same
subjects as yours and I think we could greatly
benefit from each other. If you might be interested feel free to send me
an email. I look forward to hearing from you!
Excellent blog by the way!
Broadening your input, and searching best cure for back pain (Patrick) evaluations from both people and business will certainly assist you to make an even smarter educated buy.
Asking questions are genuinely good thing if you are
not understanding anything completely, however this paragraph gives nice understanding yet.
Healing inversion table best, Arnulfo, includes various degrees of
disposition, from a slight angle past vertical to a complete 90-degree hanging position.
I’m gone to say to my little brother, that he should also pay a visit this weblog on regular basis to take updated from latest reports.
Hello, I thіnk yⲟur website might bbe
hаving browser compatibility issues.
When Ι lookk at үⲟur blog site іn Chrome, іt looks fine but աhen օpening іn Interneet Explorer, іt hhas
ѕome overlapping. І just ԝanted tо ǥive ʏⲟu ɑ quicxk hedads
uр! Οther then that, terrific blog!
mʏ blog :: make money fast
I am in fact glad to glance at this website posts
which carries tons of helpful data, thanks for providing these kinds of statistics.
Why people still use to read news papers when in this technological globe the whole thing is presented
on web?
The best what is a inversion table (Esperanza) table for you will
certainly depend on the factors formerly talked about – with the most important one being rates.
Always make sure there is insurance so that if anything does happen you will know that it is going to be fixed.
So you can be sure your vehicle will get where it needs to go in good condition be sure
you have done your homework about the transport company you hire.
Selecting an expert worldwide delivery company is the selection to go ahead with, right away.
After the physician has actually stated you as fit to utilize the top rated inversion table (Douglas) table, then you can go on and
buy it immediately.
Another inversion table advantage is the fantastic support you’ll
get from the inversion community.
My web site; back therapy equipment
We have a detailed area that actively goes over inversion treatment,
and the impacts it has on treating both short-term and long-lasting help with pain – Merlin, in the back.
Ahaa, its nice discussion aƄοut tһіѕ piece of writing аt thіs ρlace ɑt thіѕ blog, I ɦave гead ɑll that,
ѕо at tһіѕ time mee
ɑlso commenting at tһіѕ ρlace.
Also visit my web site :: iPorn
Goood article! We are linking to this partiсularly gгeat ϲontent onn ⲟur website.
Ҡeep uр tɦe great writing.
mу web site – iPorn
Fastidious answer back in return of this query with genuine arguments and describing everything on the topic of
that.
If you are buying or renting a building can you gauge the energy consumption you would encounter just
by it. Exposure to natural Environment In air, rain and other effects, the steel surface, corrosion will automatically
form a protective layer does not need paint protection, materials, life expectancy
is 80 years, and can be 100% recycled. At Canopy Rose Catering in Tallahassee, Florida we served this dressing as our house dressing.
Here is my web page … porte de garage aluminium
For further ideas, a home builder in their area can be consulted to provide more detailed house design options to guide them in the home building process.
Develop a deep conviction about who you are, what your
business does, and what you stand for. This will ensure that you end up with exactly what you want for your children.
Here is my page – fenetres aluminium
Do you mind if I quote a few of your articles as long as I provide
credit and sources back to your site? My blog site is in the very
same area of interest as yours and my users would definitely benefit from a lot of the information you provide here.
Please let me know if this okay with you. Cheers!
Hello there, You’ve done a great job. I’ll certainly digg it and personally suggest
to my friends. I am sure they will be benefited from
this website.
My site – equity trading
There what is a inversion table (Alexandra) likewise a much lower lumbar plate that provides added support and convenience at mid-range inversion angles.
This leaves them open up to assault from a mortar or other defense that is just a number of
methods more absent.
Here is my web-site; password clash of clans hack tool v1.11.4.txt
” Industry information shows that from 2000 to the first half of 2006, China’s appliance market has maintained rapid development momentum, with 50% -70% annually over the market growth rate, market capacity jumped from 100 million to In 2006 nearly 60 million units. But the most trusted option is to seek the best and most reliable residential care in Cambria California or any area near you. If you want to entertain your boss and visitors then you must have quality and durable home office furniture.
For sex toy enthusiasts who want to do their
part for a greener planet, or simply protect themselves from
what may or may not be toxic to the human body through their use (the jury is still out on this one) we have collected a large selection of these phthalate free
sex toys for you. Some have prejudice about glass material, considering it
to be dangerous. How G female appealing Gel works is it
in fact increases the amount of attentiveness that a lady can sense
when applied openly below the hood of the clitoris.
For those who are aiming to discover more about the very
best Inversion Tables, I have compiled a comprehensive choice of
testimonials for you how to help back pain at home
check out.
I get lots of people asking me iin regards to thhe FitBit and
if I really take pleasure in it. So, I figured, why not write slightly bloggy about it!
Also visit my wedbpage Mckenzie
Its collection of inversion table (Mira) tables
consists of several systems that can assist you try various inversion angles to enjoy
your inversion treatment.
With inversion table best (Clint) tables, you’ll have to be
totally sure exactly what your warranty duration is on the item.
Its such as you learn my thoughts! You seem to understand a lot about this, like you wrote the guide in it or something.
I feel that you simply can do with a few p.c.
to power the message house a little bit, however instead of that, this
is fantastic blog. An excellent read. I’ll certainly
be back.
That is a very good tip especially to those fresh to the blogosphere.
Short but very precise info… Many thanks for sharing this one.
A must read article!
Hi there, constantly i used to check weblog posts here early in the dawn, as i enjoy to find out more and more.
The very best inversion table cheap (Isidra) tables are
renown for their sturdiness, permitting you to invert and
stretch at a range of various angles.
The table can invert up to a full 180 degree,
so sophisticated users can get the complete advantage of inversion treatment.
Feel free to surf to my page … eliminate back pain, Kazuko,
The Exerpeutic Convenience Foam Inversion Table can support approximately 300 pounds of
weight.
Review my web site: exercises back pain
When the user returns to an upright position to dismount, the
inversion table, Marguerite, is once again transformed to a seat.
I was recommended this website by my cousin. I am not sure whether this post is written by him as nobody else
know such detailed about my difficulty. You’re amazing!
Thanks!
Hey! This post couldn’t be written any better!
Reading this post reminds me of my old room mate! He always kept
talking about this. I will forward this post to
him. Pretty sure he will have a good read. Thank you for sharing!
Contain Handrails too: Unlike other inversion tables, Body Champ back therapy equipment table
has hand rails that are specifically made to make it safer.
There are actually DOZENS of benefits of making use of
an inversion table inversion (Jewell) …
however I’ll go over a few of most common areas you’re most likely anxious
about.
bookmarked!!, I like your web site!
This was just a little effort from our side to
enhance awareness about inversion table.
My web page … decompression for back pain
Generally speaking, you’ll have the ability to get a more detailed inversion table therapy
experience if you have the ability to spend upwards of $400+.
Feel free to surf to my homepage :: decompression for back pain
Following are a few of the distinct functions that distinguish Body champ inversion table, Darlene,
from other normal tables available in the market.
The table inversion (Lara) likewise includes a
removable lumbar pillow in case one requires an added
back support.
Sydney’s famous Opera House is best known for its outstanding architecture, acoustics and atmosphere.
The best way to visualize what you want is to visit a few model homes and
see for yourself different aspects that you would like to have like ceiling contours, air circulation systems,
and sunlight levels. When you select a site and view
its different house plans, you can consider alternatives and think of modifications that would
suit your own preferences.
Take a look at my website: pergolas
I know this web page offers quality depending posts and extra data, is there any other site
which presents such information in quality?
The Body Power IT9910 has three inversion settings that are managed by
both a strap and a yellow safety bar.
Feel free to visit my page … exercises back pain (Dan)
That period is a realistic and reasonable goal for any business owner.
For obvious reasons this is one of the most important steps.
Green house is one of the fetish of this millennium,
a type of object to research ideally but, particularly in Italy, is not really stimulated with attention to
the peculiar characteristics of regional and national
trade.
My website baie vitrée aluminium
Weighing around 75 pounds, the IronMan Gravity 4000 benefits inversion table –
Lynette – Table
measures 26 x 65 x 49 inches.
I visited various websites but the audio feature for audio songs
existing at this site is actually wonderful.
Superb, what a website it is! This website provides valuable facts
to us, keep it up.
This is very fascinating, You are a very professional blogger.
I’ve joined your feed and look ahead to in quest of extra of your magnificent post.
Also, I have shared your web site in my social networks
The table has sensational effectiveness and plainly created for security and comfort.
Feel free to surf to my weblog :: back pain relief exercises at home
Bricks allow walls to be thinner and of more regular
shape. The moment has actually ultimately come when you are all set to develop
your dream house. Tom Kelly’s adobe mud worked much better with the glass bottles.
Here is my web blog porte blinde (http://www.1porteblindee.net/)
First, we must enter the Town Hall where we want to build our house,
which must issue a permit to build such and such that for
a house of concrete and bricks. A house should not be smothered by the landscaping.
There are two main advantages to building your own summer house from
scratch – vast savings compared with ready-to-assemble kits and flatpacks, and
the ability to choose from a much wider range of designs and customize them
to your exact ideas.
my homepage … menuiseries bois
Other inversion tables can fold up for easy storage, however the Body Champ
in fact collapses, making it very simple to transportation.
my blog post back pain from work (Molly)
Wow! This blog looks just like my old one! It’s on a totally different subject but it
has pretty much the same page layout and design. Superb choice of colors!
The IronMan Gravity 4000 home inversion table – Reyes
– Table showcases a vinyl-covered memory foam backrest that gives extra support to your neck.
May I simply say what a comfort to find someone that genuinely knows what they’re talking about on the net.
You certainly know how to bring a problem to light and make it important.
More people have to check this out and understand this side of your story.
I can’t believe you’re not more popular because you definitely have the
gift.
Hey there just wanted to give you a quick heads up.
The words in your article seem to be running off the screen in Internet
explorer. I’m not sure if this is a format issue or something to do with web browser compatibility but I figured I’d post to let you know.
The layout look great though! Hope you get the issue
fixed soon. Kudos
In order to invert, one needs to understand the handles
or straps on the sides of the table.
Also visit my webpage; best cure for back pain
Cam and Heather are basically making use of the exact same attack approach but at different city hall stages.
my page :: clash of clans hack no survey or password for android
lose the back pain – Johnny – inversion table relies on arm activities to manage its motion during exercises.
As described above, there are numerous threats associated with top rated
inversion table (Claudia)
treatment, however these ought to only be of concern if you work your body too hard.
One can also perform a complete inversion by utilizing the adjustable safety
strap beneath the table.
My web page: back pain relief exercises at home
She constantly informed me to do stretching workouts which I didn’t seem
to make the effort best cure for back pain (Senaida).
The Body Champ IT8070 is more of an entry-level inversion table, and as
such, it does not show up with numerous additional functions.
Feel free to visit my weblog :: back pan (Leia)
The ankle locks use a spring-loaded pull pin to protect the user’s feet to
the bottom of the table.
Also visit my website back pain remedies at home (Adela)
Using inversion treatment, the inversion table (Maya) can help in reducing back tension by relieving pressure on your vertebrae discs.
It was founded in 1981 by Roger advertisement Jenny Teeter to manufacture and design benefits inversion table (Matthew) items.
Wonderful items from you, man. I have bear in mind your stuff prior to
and you’re just too magnificent. I actually like what you
have got here, really like what you are stating and the best way
in which you are saying it. You’re making it enjoyable and
you still care for to keep it wise. I can’t
wait to read far more from you. That is really a great web site.
I all thе timе useɗ tⲟ гead
article іn news papers ƅut noԝ
aѕ Ӏ аm a uѕеr օff web thus from
noա І am ᥙsing net for posts, hanks tߋ web.
Heree iis mу weblog; Free Porn Videos
Lift your head, shoulders and upper back up off the table; you ought to feel a
contraction in your abs.
My page; what is inversion therapy (Patrick)
Low down payment government loans (FHA or VA) are becoming increasingly available
and can be 3% – 6% of the price of the home. Share your experience by leaving a comment or email:
knowcenter_2@yahoo. Each house loan program
will have its own individual set of rules.
Take advantage of this “down” market and the first
time home buyers tax credit. In 2013, 3,000 families purchased homes through one
of IHDA’s programs, generating 1,500 jobs and infusing
$70 million into Illinois’ economy. The interest rate of this
type of home mortgage follows the movements and changes of prime rates by ICICI Bank
Canada.
Many of the homebuyers tend to miscalculate the amount
of money they borrow, most of the time, overestimating them, because they think
that their income will increase after several years and that will make the mortgage
payment be more comfortable for them as the time goes by.
I was able to stay away and do traditional, conventional type financing for people.
Here are a few things to consider when selecting your mortgage professional.
They are going to lie to you, once you sign and see the
fine print you are going to realize that it is a ridiculous
idea to pay that amount of money in fees. Secretary Donovan said
that no one is looking into the homebuyer tax credit at this time.
Assistance may be available through your local Community Planning
& Development office or nonprofit organizations.
The Exerpeutic Convenience Foam benefits
inversion table (Kristofer) Table is
here to assist you eliminate that irritating back pain,
and offer you other advantages also.
Since under certain medical-conditions you are
not expected to make use of the inversion table, the doctor’s verification is essential.
Check out my blog … back pan (Reyna)
Trulу no matterr iff sοmeone ɗoesn’t understand аfter tɦаt іtѕ uup tо οther users tɦat they
ԝill һelp, ѕо here iit ɦappens.
mʏ web ρage :: Free Porn Videos
Whether using furniture modules that fit inside each
other and pull out for a variety of uses, or a sofa bed
or futon, multi-use furnishings are perfect for turning a living room into a comfy space for
guests to sleep.
Feel free to surf to my blog post … Home Decorating Idea
and Property (http://www.hotmitshop.com)
Regular use of best inversion table naturally improves the
posture of your spine assisting you to obtain rid of back pain relief exercises at
home (Kraig) pain completely.
Loan consolidation for debt is the procedure of obtaining a new mortgage loan to pay off alternative
loans plus credit cards (Supplier: a security camera photograph in the Dead Seashore Scrolls bus halt aversion therapy made
section of The Sphinx as well as Mummy Want to Meet You – under the radar
brown papers bag model. If the complete capital to start out the company is assigned
to you just as one individual, therefore you alone
might be responsible for it has the operations and many types of future choices,
it is better to make an LLC.
my blog; yahoo.co.jp
No matter if some one searches for his vital thing,
thus he/she needs to be available that in detail,
so that thing is maintained over here.
What a data of un-ambiguity and preserveness of precious experience on the topic of unexpected emotions.
Good day! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in trading links or maybe guest
writing a blog post or vice-versa? My website covers a lot
of the same topics as yours and I believe we could
greatly benefit from each other. If you are interested feel free to shoot
me an email. I look forward to hearing from you! Awesome
blog by the way!
Extremely Durable: This inversion table is made from tabular steel
makings it extremely durable.
Feel free to surf to my web page: decompression for back pain (Tosha)
Nevertheless, we found some reasonably priced inversion tables
that provide the same level of efficiency at half the retail price.
Check out my blog post – eliminate back pain (Skye)
I am really impressed with your writing skills as smartly as with the structure to your
blog. Is this a paid subject or did you modify it yourself?
Anyway keep up the excellent high quality writing, it is uncommon to peer a
great weblog like this one nowadays..
Also visit my webpage :: The Money Doubler App
When the user returns to an upright position to dismount, the inversion table best is when again converted to a seat.
The majority of people don’t need to totally invert to
get the maximum benefits of lose the back pain (Marita) table.
What’s Going down i am new to this, I stumbled upon this I’ve discovered It absolutely helpful and
it has aided me out loads. I am hoping to contribute & help other users like its helped me.
Great job.
Anyone that has an absence of mobility or that what is inversion therapy (Ermelinda) even incapacitated will discover that inversion chairs provide
the utmost in support and stability.
Simply wish to say your article is as amazing. The clearness in your post
is simply cool and i could assume you’re an expert
on this subject. Well with your permission let me to grab your feed to keep updated with
forthcoming post. Thanks a million and please continue the rewarding work.
My web blog :: visit this site (tsmart.id.au)
It allows for natural back decompression therapy while integrating the most
recent designs and innovations.
Here is my blog: pain help (Jed)
I every time used to read paragraph in news papers but now as I am
a user of web so from now I am using net for posts, thanks to web.
Here is my page: MLC signals
We see a dress in our favorite colour and never once will we forestall and say – is the
lower and shape of this dress flattering to my figure. The most important
thing to note is that we only use the best quality European hair across our entire product range.
Gold by Kim Kardashian has been created by combining quite a variety of perfume notes including the more citrus
blends of bergamot (orange scent), pink grapefruit and pink pepper.
When all the things that you do is analyzed under a microscope, photographed,
recorded in gossip columns, marketed as news, you need to
definitely be primed for just about any situation.
Kardashian was apparently a good sport about the script, which is filled with jokes about her family.
Also visit my web site … unlimited stars kim kardashian game
There are a couple of more affordable designs of inversion table inversion [Keeley] that have an intricate system.
But,fortunately many grants for firsttime home buyersare available to help pay for a new home.
Depending on the loan amount, this could mean a difference of $250.
Nehemiah Program, Ameri – Dream, Partners In Charity, Homes For All Programs.
Sometimes dirty talking over a text message is way easier than doing it live
in person. Please select the type(s) of Alerts you would like to review:
. Dan has brought with him some really, really interesting
facts and figures for people who are wondering whats happening, wondering if we are
at the bottom of the market, wondering how much further we are going to have to go.
I am a complete COC addict who spends a lot on gems and other stuff so this tool will come
extremely useful to me.
My webpage … clash of clans hack password v1.68
The show is looking for high energy individuals that are in the process of buying a new home, condo,
or townhome. Be sure to check the contract details on any grant or loan you’re thinking about applying for, to prevent you from running
into real financial trouble later. There have been a lot of first time homebuyers who have secured their own houses
with the help of downpayment assistance programs. Same goes for the water bills you’ll pay to maintain a pristine landscape.
Secretary Donovan said that no one is looking into the homebuyer tax credit at this time.
Assistance may be available through your local Community Planning & Development office or nonprofit organizations.
This table can old as much as 250lbs and performs much the same as other inversion tables on the market.
Here is my web-site: back pain relief exercises at
home, Bobbye,
Good answers in return of this query with solid arguments
and explaining everything concerning that.
Some of them will require you to be pre-approved for a home loan from your local lender.
Depending on the loan amount, this could mean a difference of $250.
The proven facts of this anti-virus program made it adoptable over a range
of computer users. Sometimes dirty talking over a text message is way easier than doing it live in person. In order to
be eligible for these types of loans, your income will need to be below a certain level, which varies by area, family size,
and house. First time home buyer grants are found right
in your own neighborhoods.
My brother recommended I may like this website.
He used to be entirely right. This submit truly made
my day. You cann’t consider just how much time I had spent for this information! Thank
you!
Basil is good for hair strength as well, application of basil leaves helps you improve
hair strength. White vinegar has antibacterial and antifungal properties helping you keep all the scalp infections at
bay. Sorry, but this is one of those things that most people won.
I do not even understand how I stopped up right here,
however I assumed this put up was once great. I do not realize who you might be but certainly you’re going to
a well-known blogger in case you aren’t already.
Cheers!
This way, you can get a good idea of how they work and what their personality is.
Many people start this practice at a very young age and
excuse themselves by stating that they find relaxation in this habit, others say that it
eases stress, while another group says it helps them to
be slim. Many women all around the world, if asked, would
change something about how they look, but often do not speak of these in public.
Greetings I am so grateful I found your weblog, I really found
you by mistake, while I was looking on Google for something else, Anyhow I am here now and would just like to say
thank you for a remarkable post and a all round interesting blog (I also love the theme/design), I don’t have time to go through it all at
the minute but I have saved it and also added in your
RSS feeds, so when I have time I will be back to read much more, Please do keep up
the great jo.
Therefore, even though you can very easily see, if you
like to appear at films on Netflix you have to obtain use of this web site.
I was pretty pleased to discover this web site.
I want to to thank you for your time for this particularly wonderful
read!! I definitely loved every bit of it and i also have you
saved to fav to see new stuff on your blog.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you
would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and
I look forward to your new updates.
Hi to every body, it’s my first visit of this webpage; this blog contains awesome and truly fine information in favor of readers.
Here is my web site Gold Digger Trading
Magnesium chelate or asporotate may help stop
a severe asthmatic episode. Emphasize fresh, organic, fruits and vegetables, whole grains, fish,
and poultry. It c’uld stave off the incident, or it could see to it that
the crisis is not severe.
Also visit my web-site; treatment of bronchial asthma – Marsha –
Use the pursuing tools below to uncover the best Clash of Clans base for your amount.
Also visit my webpage :: clash of clans in app purchase glitch
Heya i am for the primary time here. I found this board and I in finding It really helpful & it helped me out a lot.
I’m hoping to present one thing back and help others such
as you helped me.
No matter if some one searches for his necessary thing,
therefore he/she needs to be available that in detail,
therefore that thing is maintained over here.
It is one of the more costly electric inversion table (David) tables in the market
with sophisticated design functions for exceptional comfort and outcomes.
inversion table cheap (Kristeen) therapy is seldom utilized to
deal with chronic discomfort, so it is just useful for mild relief.
Teeter Hangups, for instance, supplies fantastic support with its flexible table however does not provide much in the method of cushioning.
Here is my web-site :: inversion back therapy (Efren)
Preventative Care; Inversion Tables are not only helpful for actively combating existing issues, however they are also terrific for preventing future problems.
my weblog – how to help back pain at home (Eulah)
Hi, I do believe your website might be having browser compatibility issues.
Whenever I take a look at your web site in Safari, it looks
fine however, when opening in I.E., it has some overlapping issues.
I merely wanted to give you a quick heads up! Other than that, wonderful website!
I am sure this article has touched all the internet users, its really really
fastidious piece of writing on building up new blog.
The Ironman LX300 could be the budget friendliest of all the
home inversion table
tables.
The rate points for in-back pain remedies
at home (Margarita)
inversion tables vary widely adequate to make expense
a consideration.
hello!,I like your writing very much! share we communicate extra about
your post on AOL? I need an expert in this house to unravel my problem.
Maybe that is you! Looking forward to see you.
Take a look at my page – Perfect Profits
Some inversion tables include added functions such as training videos,
lumbar cushions, and acupressure pads.
My web page; help with pain (Chelsea)
Basil is good for hair strength as well, application of basil leaves helps you improve hair strength.
Article Source: has years of experience in pannelli acustici manufacturing.
If you want to entertain your boss and visitors then you must have quality and durable home office
furniture.
We have actually attempted to offer you with
all the information that is required for
purchasing best inversion table.
Feel free to visit my web-site – back pain relief exercises
at home (Alannah)
Nevertheless, inversion can trigger a state of relaxation that results in a
drop in heart rate and BP (occasionally even lower than back pain relief exercises
at home (Cliff) a resting
state).
Inversion Treatment helps to battle the results of aging by correctly lining up and reinforcing your spine.
my web blog – help with pain
We have a comprehensive section that actively
talks about inversion treatment, and the impacts it has on dealing with both long-term and short-term pain in the back therapy equipment (Ahmad).
Preventative Care; Inversion Tables are not only good decompression for back pain actively combating existing problems,
however they are also terrific for preventing future problems.
It made a huge distinction to know that he is too a back patient who firmly cares about this top rated inversion table (Theda).
I am sure this post has touched all the internet viewers, its really really nice
paragraph on building up new blog.
Teeter inversion table (Lottie) products please rigid
security requirements of Underwriter’s Laboratories.
A variety of other health concerns are contraindicated for using inversion treatment,
states senior medical editor Susan Spinasanta of SpineUniverse.
Here is my site … exercises back pain – Edgardo –
Our foldable table supplies excellent convenience as it permits you to collapse
the inversion table best (Shoshana) down for
easy storage.
Advanced users can likewise carry out core enhancing workouts while inverted
in the chair.
My web site :: inversion table (Titus)
The table can invert up to a full 180 degree, so innovative users can get
the complete advantage of inversion therapy.
My web page … exercises back pain (Ashleigh)
You shouldn’t use inversion therapy if you have high blood pressure, coronary ailment or any eye ailments.
Here is my website how to help back pain at home (Danny)
Hey! Do you know if they make any plugins to protect against
hackers? I’m kinda paranoid about losing everything I’ve worked hard
on. Any tips?
Hmm is anyone else experiencing problems with the pictures
on this blog loading? I’m trying to find out if its a problem on my end or if
it’s the blog. Any responses would be greatly appreciated.
It is essential to get the ideal kind of inversion table
for appropriate security and higher effectiveness.
My homepage – back pain – Latesha
–
Thіs iѕ vesry іnteresting, Уou’rе ɑ ѵery skilled blogger.
Ι’ѵᥱ joined үоur rss feed аnd lοօk forward too seeking more οf уօur magnificent post.
Αlso, Ι’ѵᥱ shared үour website іn mү social networks!
Ꮇy blog :: Free Porn Videos
My kids and her brought out the Inversion table, this very same exact one and I was expecting a guitar as
I play at church and then got this.
Stop by my homepage: help with pain, Jenifer,
My reviews weigh up the sturdiness of each item against
other items – helping you to find the most durable and reliable table
for you.
my website inversion beds (Frances)
Heⅼlߋ to ɑll, іt’ѕ truly
a pleasant fⲟr mᥱ tо pay a quick visit tɦіѕ website, itt
includes heppful Ӏnformation.
Alsso visit mу blog :: Free Porn Videos
Testimonials and opinions vary from person-to-person, and as such, I constantly recommend checking out other reviews and contrasts.
My web page – home inversion table
The Body Champ IT8070 is more of an entry-level inversion table,
and as such, it does not show up help with pain (Modesta) lots of extra features.
I like it. The what is inversion therapy, Rickie,
takes a while to obtain utilized to. A few minutes a day makes a distinction.
Prior to you buy an inversion table, see to it that
you make use of one that is advised by specialists and
that is really good for your current situation.
my web page – back pan, Rosalie,
I really like it when individuals get together and share opinions.
Great website, keep it up!
I’m curious to find out what blog system you happen to be using?
I’m having some minor security issues with my latest site and I would like to
find something more safeguarded. Do you have any recommendations?
I rdad this artice compleetely cοncerning the difference
οf most гecent ɑnd ᥱarlier technologies, іt’ѕ awssome article.
Аlso visit my Һomepage; Free Porn Videos
Essential factors + lots of exceptional consumer testimonials have actually persuaded me that this is truly the very best cure for back pain (Lizette) one out there; for me anyhow!
Usually I do not read post on blogs, but I wish to say that this write-up very pressured me
to take a look at and do so! Your writing style
has been surprised me. Thank you, quite great article.
Purchasers should think about placing bulk orders for those who want to follow through on inversion table (Nathaniel) testimonials.
Teeter Hang Ups is the best home inversion table
(Marcos) table
brand in the market and this model is among their best productions.
The Exerpeutic inversion table packs a substantial
punch for its exceptionally low retail price of
$109.
Here is my weblog – back pain remedies at home, Brandon,
We have actually taken all the very best features
and integrated them into what I consider to be the very best inversion table best
(Rodrick)
table on the market today.
It is one of the few inversion tables in the market that can be modified with devices.
my web page eliminate back pain; Shelton,
A safety tether is developed to control inversion angles of 20 degrees, 40 degrees, 60
degrees, and a full 90 degrees.
Also visit my web blog back pain from work (Precious)
With home inversion table (Wanda) tables, you’ll have to be entirely sure exactly what
your warranty duration is on the item.
The height modifications on this device permit users as brief at 4-foot-7, which is a few inches
much shorter than many other benefits inversion table
(Elliott) tables.
I like it. The inversion takes a while to obtain made use
of to. A couple of minutes a day makes a difference.
My weblog – best cure for back pain (Franklyn)
The table also has a removable lumbar pillow in case one requires an extra exercises back pain (Doug) support.
Inspiring quest there. What happened after? Take care!
Also visit my page: full movies
Contain Handrails too: Unlike other benefits inversion table (Isiah) tables,
Body Champ treatment table has hand rails that are specifically made to make it much safer.
Because an inversion table will have you hanging upside down by your ankles,
you’ll want to feel safe.
my blog; help with pain [Elizabet]
Great info. Lucky me I came across your blog by chance (stumbleupon).
I’ve bookmarked it for later!
My web blog; Insiders Information
Exactly what we suggest is taking in to account all the points we have actually discussed
earlier in the short article while purchasing
inversion table.
my web page – back pain relief exercises at home
The IT8070 is capable of full inversion, however is developed more for healing use than core workouts.
Visit my homepage – help with pain (Millie)
See to it you have a good friend with you when you utilize the
what is inversion therapy (Olive) table for the first time, in case
there are issues.
I am really impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you modify it yourself? Anyway keep up
the nice quality writing, it is rzre to see a great blog like this one today.
It is not my first time to pay a quick visit this site, i am visiting this site dailly and obtain pleasant information from here all the
time.
In the magic forums you can pose different questions you may have so that experienced magicians can guide you to the best answers and solutions.
The AKO system allows all the useability of a normal internet connection but with the added bonus of being a well
monitored and secured connection. We are already becoming a rapid communication society.
Here is my weblog :: facettes dentaires
This said, investors stand on the side of business owners
to assist them within forwarding allows to their organizations,
Take a look at my webpage :: Theguardian.com
I don’t even know the way I ended up here, but I thought this publish was great.
I don’t recognise who you might be but definitely you are going to a well-known blogger when you are not already.
Cheers!
Also visit my blog post First Class Profits
I was curious if you ever considered changing the page layout
of your blog? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with
it better. Youve got an awful lot of text
for only having one or 2 pictures. Maybe you could space it out better?
Thanks , I’ve just been searching for information about this topic for
a long time and yours is the best I’ve found
out so far. But, what in regards to the bottom line? Are you certain in regards to the supply?
hey there and thank you for your information – I have definitely picked up anything new ffom right
here. I did however expertise several technical points using this
site, as I experienced to reload the web site lots of times previous
to I could get it to load correctly. I hadd been wondering if your web hosting is OK?
Not thqt I am complaining, but sluggidh loading instances times will often afcect your placement
in google and could damage your quality score if
advertising and marketing with Adwords.Well I’m adding this RSS to my email and
could look oout for a lot more of your respective fascinating content.
Make sure you update this again soon. http://www.festiberico.com
We’re looking for fun and interesting people who are willing to share their personal and financial struggles during the home-buying process.
But to make the opposite genders clash would be a terrible idea, this could
also be a realization to both genders that maybe there were impulsive actions that we do
which we happily pursue not knowing what could be the damages
given to those persons affected. VA loans are another zero down payment loan opportunity.
We hear a very good deal about how the government
is offering grants and financial assistance but perhaps the most promising among these presents
is the first time home buyers grants. Secretary Donovan said
that no one is looking into the homebuyer tax credit at this time.
It is, therefore , critical to consider all of these cost before
settling for a mortgage.
Although buying a home seems like a daunting task, don’t forget that it’s just like buying anything else in life, only one of the bigger investments you’ll make.
Many people may be able to also reduce the number of years that they sign up for with their
first mortgage. Real Estate Conditions 6 – Mortgage &
First Time Home Buyer Dec08 Loss Mitigation Department.
Dan Havey has been a great promoter for Velocity Financial.
The one big problem is that mortgage money for first time home
buyers in Chicago can be hard to find. Take advantage of this important tool before looking for
a home.
Choose from one of our inversion tables to reverse lose the back pain – Cesar,
results of gravity and feel long term relief.
Hi, Neat post. There is a problem with your web site in web explorer, could check this?
IE nonetheless is the market leader and a big section of folks will
pass over your great writing because of this problem.
While in an inverted position, one can either stay still or carry out strengthening exercises depending upon an individual’s individual experience and goals.
Here is my site help with pain
At a price of simply $114, it’s a effective and budget-friendly alternative to high-end inversion tables that cost hundreds of dollars
more.
My homepage :: eliminate back pain (Kaitlyn)
WOW just what I was searching for. Came here
by searching for wedding forums
If you want to improve your know-how just keep visiting this site and be updated with the hottest news posted here.
Some of the better-quality,.
my website: inversion table cheap (John)
We have actually tried to supply you with all the info that is needed decompression for
back pain [Antonetta] buying best inversion table.
Though, Ironman Gravity 1000 Inversion Table has some downsides but its
advantages exceed them.
Stop by my blog – best cure for back pain [Tracie]
The very best inversion beds (Trinidad) tables meet industry standards on weight, construction, and design ability.
Despite the fact that most top rated inversion table tables look
really comparable, they’re certainly not all created equivalent.
Good quality waterproofing suggests that the binoculars were fulled of nitrogen gas.
When in excellent health and no medical problems are present, Inversion tables are perfect.
Here is my blog post … best cure for back pain (Wilton)
The Body Champ IT8070 utilizes 2 different methods to manage the unit’s range of
inversion table cheap (Nadine).
I do not even understand how I stopped up right here, but I believed this publish was once good.
I do not understand who you’re but certainly you are going to a well-known blogger if you aren’t already.
Cheers!
Users can run the benefits inversion table (Orval) by themselves
without the issue of getting stuck.
Raise your head, shoulders and upper back up off the top rated inversion table – Shawn -;
you should feel a contraction in your abs.
It is well suited to newbies or for using in combination with physiotherapy/chiropractic therapy.
my weblog … lose the back pain (Elvira)
The best inversion tables on our shortlist also integrate useful features like hand grips and quick-release restraints.
My blog – back therapy equipment (Betty)
Good post. I learn something new and challenging on blogs I stumbleupon on a daily basis.
It will always be interesting to read through content from other writers and use something from their websites.
My homepage – prestamos personales online
It’s actually a great and useful piece of information. I am satisfied that you simply shared this helpful
info with us. Please stay us up to date like this.
Thank you for sharing. http://www.njmusicawards.org
In this man or women can get money in a range up to 1000 for you
to 1500 having a repayment period associated with 14 so that you can 30 days.
Also visit my web-site; mapquest.com
We’re a group of volunteers and starting a new scheme in our community.
Your web site offered us with valuable information to work on. You
have done a formidable job and our entire community will
be thankful to you.
Wonderful post! We will be linking to this great post
on our site. Keep up the good writing.
Here is my web blog … Binary Stealth
Nomophobia – The really powerful fear of being without your cell phone or mobile.
And here are my picks for the top search words and phrases of the year.
Yahoo said the dominance of pop culture in the searches shows that the
Internet is being used largely for entertainment purposes.
My web-site … sanalika hilesi
Ƭhanks for tɦе JaνɑЅсrіρt Εхеrciѕᥱ
Ꮮоοκ at my ѡеЬρagе – FARMAKEIO
A multitude of business are making inversion tables however there
are very few companies that are providing quality products.
Feel free to visit my blog post: back pain from work – Berry –
inversion back therapy, Dominga, therapy puts gravity to work for you by putting your body in line with the down force
of gravity.
At such a low rate, the Body Champ IT8070 is a inexpensive and reliable
alternative to high-end inversion tables that cost numerous dollars more.
Also visit my page – back pan (Stephan)
Given that an inversion table will certainly have
you hanging upside down by your ankles, you’ll want to feel safe.
Look at my blog; back therapy equipment
It is essential to adopt home inversion table (Nona) treatment at a
gradual pace – much like you would with other kind of workout.
Another useful building element is the liberal use of foam cushioning, which is discovered from the table to the
head rest to the ankle lock.
Here is my web site; back pain relief exercises at home
(Cyrus)
The putting on of prescribed glasses ONLY will seldom
remedy poor binocular vision refers to the
ability to quizlet (Edgardo) vision.
Likewise, the optical quality of a zoom binocular reviews 2014 uk [Charity] at any given power
is inferior to that of a set power binocular of
that power.
You absolutely 100 % do NOT need to be entirely upside down in order to get
relief utilizing an inversion table.
My web page: eliminate back pain – Daniel,
By strapping yourself into the platform, you can then turn yourself anywhere from a 15-degree moderate inversion table best
(Bettina) to totally upside down.
Our foldable table offers exceptional benefit as it permits you
to collapse the table down best cure for back pain
easy storage.
ağır metal Bu alt kategoride
Nu Metal olarak bilinir
Here is my web-site; siyasetci koray buyukasar
We likewise recommend making use of extra padding, like a little pillow
or foam workout mat, to cover the un-padded locations of the Exerpeutic inversion table.
Also visit my web blog exercises back pain (Levi)
Expdition rapide, article comme dcrit , trs bien, merci !
You should check these and different other functions before buying
the inversion table (Vernita).
You can also go through the user reviews which
will assist you decide whether inversion tables work for actual or not.
Feel free to surf to my web page; back pan (Jeannine)
It assisted me within minutes.
My webpage electric inversion table
Following are some of the distinct functions that distinguish
Body champ what is a inversion table [Kelle] table from
other regular tables available in the market.
Check out the instructions thoroughly when adjusting your what is a inversion table (Essie) considering that each
maker might use different mechanics.
I lіke whzt yyou guys arᥱ սsually uup too.
Ꭲһіs sort οf clever work аnd reporting!
Κeep ᥙρ tɦe wonderful ᴡorks guys І’νе included уⲟu guys tto
оur blogroll.
My page; Free Porn Videos
Halo: Reach is a first-person shooter video Sniper Fury Hack which brought Microsoft
US$200 million on its launch day, making the new record for the company.
The G2x comes equipped with an 8-megapixel rear-facing camera with LED flash and autofocus,
and a front-facing 1. Series: The Sims Platforms: Microsoft Windows, Mac OS
X, i – OS, web – OS, Android, Symbian^3, Nintendo DS, Nintendo 3DS, Wii, N-Gage, Xbox 360, PS 3 Genre: Life Simulation, Social simulation Mode(s): Single-player Ratings: ACB =
M, ESRB = T, PEGI = 12.
What’s up it’s me, I am also visiting this web page regularly,
this site is really nice and the viewers are actually sharing pleasant thoughts.
My web page; peersynergygroup.com – Alethea –
Probably because for them marriage involves sacrificing their most treasured
possession — a free-agent p*n**s — and for
us, it’s the culmination of a princess fantasy so universal, it built Disneyland.
The good news is that I believe every woman who wants to
can find a great partner. Braun became the supervisor of Justin after and held him in the information as much as really possible.
Actually, the Kim Kardashian workout video reviews you can read
online are one of the ways through which she shares her secrets with us about what routines she works out with to lose weight.
Kim Kardashian’s wedding party invitations sent out.
my web site: tap titans hack gold
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get bought an edginess over
that you wish be delivering the following. unwell unquestionably
come more formerly again since exactly the same nearly very often inside case you shield this
increase.
These best binoculars for bird watching 2009 (Rolland) might
have been French, German, or from private individuals ect,
any place they might find them.
Useful information. Lucky me I found your site accidentally, and I’m stunned why this twist
of fate did not took place earlier! I bookmarked it.
It is appropriate time to make a few plans for the
longer term and it is time to be happy. I have learn this publish and if I may just I want to suggest you some attention-grabbing things or advice.
Maybe you can write subsequent articles relating to this article.
I want to learn even more things about it!
It is practically impossible to list animals according to their sense of vision, considering
that all of them have different types of vision.
Here is my page; binocular cues for depth perception include (Tyson)
Hello ! I still do not understand what you ‘re talking about here .
You may say more to help me or see my site and give me comments
Considering that an electric inversion table – Wilhemina,
table will have you hanging upside down by your ankles, you’ll want to feel
safe.
The balance of electric inversion table (Moshe) Table is so accurate that control of the rotation can be effected
by easy arm motions.
Weighing around 75 pounds, the IronMan Gravity 4000 inversion table cheap – Lacey, Table measures 26 x 65 x 49 inches.
This is among the lowest priced best binoculars for bird watching 2015 in our review
to feature ED glass– a clear step up in regards to products
and image.
Optometrists who offer binocular vision disorder [Penni] Treatment are professional specialists who called themselves Developmental optometrists
or behavioral eye doctors.
The IFT 1000 table has to do with the same as the other
2 infared tables mentioned above.
Feel free to surf to my website back pain remedies at home (Margo)
KEEP IN MIND: Please check out the health warnings
at the end of this post prior to you choose to buy an inversion table.
my blog post; back pain (Lenora)
Important elements + lots of outstanding consumer
evaluations have encouraged me that this is truly the very best cure for back pain (Valorie) one out
there; for me anyway!
Lenses: The ocular lens belongs to the eyepiece, where the magnification of the binocular lies.
My site: best binoculars for astronomy reviews
I know this if off topic but I’m looking into starting
my own weblog and was wondering what all is required to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% certain. Any suggestions or
advice would be greatly appreciated. Many thanks
This site truly has all of the information I needed concerning this subject
and didn’t know who to ask.
When comparing best binoculars for coues deer hunting – Chasity,
of equal quality, the larger the difference between the 2 numbers, the sharper and brighter the image.
For those who are planning to find out more about the very
best home inversion table (Gilbert) Tables, I have actually compiled an extensive option of user reviews for you
to check out.
Hello would you mind letting me know which web host you’re working with?
I’ve loaded your blog in 3 completely different internet browsers and I
must say this blog loads a lot quicker then most.
Can you recommend a good hosting provider at a
honest price? Thank you, I appreciate it!
There was speculation that using an inversion table could add to strokes.
my site back pan (Tamara)
Another inversion table benefit is the great support
you’ll get from the inversion community.
Check out my webpage pain help
whoah this blog is fantastic i love reading your posts.
Stay up the good work! You know, lots of individuals are hunting around for this info, you
could help them greatly.
ᕼi mʏ loved οne! Ι wish tto say
tɦаt thuis article іs awesome, nice ᴡritten аnd come with
almkost all vital infos. І’Ԁ likme tо llok more posts ⅼike tҺіѕ .
Allso visit mу blog post: Paid Surveys
See to it you have a buddy with you when you utilize the inversion table for the first
time, in case there are issues.
Here is my homepage exercises back pain (Odell)
Steps Body Upside down: This inversion table moves body upside down launching
pressure from the back pan (Merri) bone that automatically releases discomfort.
I don’t know if it’s just me or if perhaps everybody
else experiencing problems with your site. It appears as if some
of the text in your content are running off the screen. Can someone else please comment and let me know if
this is happening to them too? This could be a problem with my web browser
because I’ve had this happen before. Thank you
Here is my website … Virtnext (Thalia)
Most inversion table evaluations are being shipped around and kept
in the loop for as long as possible.
My weblog … back therapy equipment (Kristi)
Regular use of best inversion table naturally enhances the
posture of your spinal column helping you to get rid
of pain in the eliminate back pain (Casimira) permanently.
To help request money advancement, you must have good position credit,
don’t have any late fees on your statement plus a substantial steadiness on your credit-based card.
my web page; tumblr.com
Hi there just wanted to give you a quick heads up. The words in your article seem to be running off the screen in Ie.
I’m not sure if this is a format issue or something
to do with web browser compatibility but I figured I’d post to let you know.
The design look great though! Hope you get the issue
fixed soon. Many thanks
You can reap the benefits in this particular financial loan once you consider
you cannot cope with an additional purchase in times of emergencies.
Feel free to surf to my weblog digg.com
The media reported the side effects, but researches
on the use of inversion back therapy (Elizabeth) tables found no evidence to support the speculation.
In reality, the United States Military is writing Inversion into its
around the world physical training handbook that will certainly be adopted for the brand-new millennium.
Also visit my site; exercises back pain (Juliana)
Following are some of the unique functions that distinguish
Body champ inversion table from other common tables available in the market.
Review my web-site back pain remedies at home (Lavonne)
The weight is an indicator of its durability, you should
choose the sort of home inversion table [Sheryl] table was
made with strong products.
The IronMan Gravity 4000 Inversion Table features a vinyl-covered memory foam backrest that offers added support to
your neck.
Take a look at my web blog back pain (Dominga)
YouTuber Galadon puts the old saying ‘too much of an excellent everything is bad’ when it concern Lava Hounds in Clash of Clans.
Prior to your kid plays a computer game, play the game yourself.
Don’t only utilize ESRB ratings as well as the word of others.
My web page: Dawn
Tɦanks , Ihave гecently Ьееn looking ffor info аbout thіѕ topic foor ages ɑnd yοurs iѕ tҺе ցreatest I’ᴠе discoveted sο far.
Ⲃut, ѡhat concerning tɦe ƅottom ⅼine?
Aге yоu sur ɑbout tɦе supply?
Τake a ⅼⲟοk at mʏ web ρage:basement shower drain
medyum,medyumlar,ask
buyusu,bütün medyumlar
Alot of online qualifications can be completed entirely on the net, Central Mi University has a presence
using a number of military bases consequently
spouses usually takes some in-person sessions in addition to their on the net studies.
Feel free to visit my web-site; vimeo.com
An inversion table is a device designed to assist you turn over and enable gravity to naturally elongate back muscles and bring back pain relief exercises
at home (Cora) intervertebral spacing.
Thanks for ones marvelous posting! I truly enjoyed
reading it, you happen to be a great author. I will be sure to bookmark your blog and will often come back
very soon. I want to encourage continue your great posts, have a nice morning!
Thanks fⲟr sharing your thoughts. I really appreciate ʏοur efforts
аnd І ԝill Ƅе աaiting fоr
үⲟur neⲭt աrite սps thanks οnce again.
Feel free to surf tto mʏ site; cellulite cream
Fantastic website. Lots of helpful information here.
I am sending it to some buddies ans additionally sharing in delicious.
And certainly, thank you on your sweat!
Here is my web blog … Bmw Key Chain Bmw Key Chain Locket Style Key Chain With The Bmw
Attractive section οf сontent. I just stumbled
սpon ʏоur blog ɑnd іn accession capital
tօ assert tgat Ι ցet in fɑct enjyed account үօur blog posts.
Any ѡay Ι ᴡill Ье subscribing tߋ уοu feeds and еνеn Ⅰ achievement yօu
access consistently ԛuickly.
Μʏ ρage – Free Porn Videos
Due to the fact that inversion treatment relieves the pressure on your discs, you can often repair
the damage caused.
my weblog :: exercises back pain – Selene –
101 102 In March 2013, Netflix announced it signed on The Wachowskis and J.
Michael Straczynski to create and executive produce their new scifi series, Sense8 103 It debuted on June five, 2015.
There was speculation that utilizing an top rated inversion table (Mitchel) table could add to strokes.
If you have a headache when starting inversion treatment, you might
experience a boost in signs.
Check out my site – decompression for back pain (Shawn)
That’s why I want to give you the very best warranty in the inversion table market.
my page; back therapy equipment (Scott)
The other day, while I was at work, my cousin stole my iphone and tested to see if it can survive a twenty five foot drop,
just so she can be a youtube sensation. My iPad is now destroyed and she has 83 views.
I know this is entirely off topic but I had to share it with someone!
My web page: XTP App
Hello, this weekend is fastidious in favor of me, for the reason that this point
in time i am reading this impressive informative article here at my house.
After I initially left a comment I seem to have clicked on the -Notify me when new comments are added-
checkbox and from now on each time a comment is added I get 4 emails with the
same comment. Is there a means you can remove me
from that service? Cheers!
Feel free to surf to my web blog – Full Review (wiki.freearcadescript.net)
Your team will no doubt contain within it a varied skill set.
know that whether he succeeded in his endeavor or not.
However, you should still research each on in turn and find out the main advantages and disadvantages of each particular piece of software.
This is my first time pay a quick visit at here and i am in fact
pleassant to read everthing at single place.
Working out on an inversion back therapy (Antonia)
table relieves the process of flow by dealing with gravity.
Using inversion treatment, the Inversion Table
can help in reducing back therapy equipment tension by
relieving pressure on your vertebrae discs.
This tax is applied at a rate of 1% of the first $200,000 purchase price, and 2%
of every dollar thereafter. Share your experience by leaving a comment or email:
knowcenter_2@yahoo. There have been a lot of first time homebuyers who have secured their
own houses with the help of downpayment assistance programs.
In case, any problem during usage of Mc – Afee antivirus come to you will
be resolvable with quick contact of Mc – Afee Tech Support Phone Number.
If an individual or couples desire to meet the criteria for
a home buyer program, then the history of rental payments
will also be considered. They help out of town investors keep their properties productive.
The dollar amount of the EEM improvements cannot exceed 5% of the property’s value (not
to exceed $8,000) or $4,000, whichever is greater. Qualified
properties are identified on the Help-U-Sell website, . Those that are seeking a Mortgage Ireland opportunity will have to vouch for steady savings buildup as one criterion the First Time Buyer Mortgage program. There are two kinds of home improvement loans available to choose from. An ethical upsell, although one that may not be all that good for your health. I think you are going to go get a second opinion, maybe even a third.
Adjust the inversion table to your height; your
head should rest comfortably on the bed of the
table and not hang over the edge.
Here is my web site :: help with pain
Woah! I’m really loving the template/theme of this website. It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between usability and visual appeal. I must say that you’ve done a excellent job with this. Also, the blog loads super fast for me on Safari. Outstanding Blog!
The kind of cushioning and products on the table will
make a difference in your experience.
Stop by my blog; decompression for back pain (Randy)
A Buyer’s and User’s Guide to Huge Telescopes and best binoculars
for birding under $500 (Edward) by
James Mullaney.
Highly energetic post, I enjoyed that bit. Will there be a part 2?
My web blog; why not try these out (http://www.walshfinancialsolutions.com)
The consumer testimonials are likewise positive meanings that it is useful in alleviating pain in the how to help back
pain at home (Angelo).
Good post however I was wondering if you could write a litte
more on this subject? I’d bbe very thankful if yoou could elaborate a little bit
more. Apprecizte it!
Also visit my webpage – watch
The height adjustments on this device allow
for users as short at 4-foot-7, which is a few inches much shorter than many
other electric inversion table; Bella, tables.
It’s difficult tο find educated people іn thіѕ
ρarticular subject, Һowever, үⲟu
seeem ⅼike үօu қnoա ԝɦɑt ʏоu’ге talking about!
Τhanks
Feel free tо surf tо mʏ blog post ways to make money from home
Testimonials and opinions vary from person-to-person, and as such,
I always advise reading other reviews and contrasts.
Also visit my web-site – eliminate back pain (Ella)
Excellent blog here! Also your web site lots up very fast!
What host are you the usage of? Can I get your associate hyperlink in your host?
I want my web site loaded up as fast as yours lol
If the tether must fail, a secondary security bar attached to
the frame prevents the table from going out of control.
Also visit my site … inversion back therapy, Don,
Offer Numerous inversion back therapy (Hershel) Table
Benefits: This table offer several benefits at a time.
I blog quite often and I really thank you for your information. Your article
has really peaked my interest. I am going to take a note of your website and keep checking for new information about
once a week. I subscribed to your Feed too.
Excellent post. I was checking continuously this blog and I’m impressed!
Very useful information specifically the last part 🙂 I care for such info a lot.
I was seeking this certain information for a long time.
Thank you and good luck.
Armed service Pendants If you want a gift for the
spouse or perhaps a family member, the military ring will be 1 gift that’s
memorable and much appreciated.
Feel free to visit my blog post :: myspace.com
table inversion [Wilda] triggers decompression of the intervertebral
discs in the spinal column enabling them to restore their elasticity and functional durability.
Hi, I do think this is a great site. I stumbledupon it 😉 I will return yet again since
I book-marked it. Money and freedom is the best way to
change, may you be rich and continue to help others.
Body Power IT9910 Deluxe electric inversion table
(Shantae) System is a perfect choice
for individuals with movement constraints or back problems.
Appreciate the recommendation. Let me try it out.
What’s up Dear, are you genuinely visiting this website regularly, if so afterward you will absolutely get fastidious
knowledge.
It is reputable, cost effective and has advanced security functions that one requires from an inverting table.
Here is my homepage how to help back pain at home (Danny)
This is a wonderful function for anybody limited for area,
or who doesn’t desire an inversion beds (Bart) table permanently set
up in their house gym or living space.
As opposed to on the Xbox 360, the Netflix application was initially available on a Blu-ray Disc
(obtainable cost-free to subscribers).
That’s why we’ve chosen to offer the very best support for
home inversion table [Kathi]
tables in the world that we know of … a full 90 days of personal 1-on-1 support.
I’ve been surfing online more than 2 hours today,
yet I never found any interesting article like yours. It’s pretty worth enough for me.
Personally, if all webmasters and bloggers made good
content as you did, the web will be a lot more useful
than ever before.|
I could not refrain from commenting. Well written!|
I’ll right away grab your rss feed as I can’t to find your e-mail subscription link or e-newsletter service.
Do you have any? Please allow me know so that I may
subscribe. Thanks.|
It’s the best time to make some plans for the future and
it is time to be happy. I have read this post and if I could
I want to suggest you few interesting things or suggestions.
Perhaps you can write next articles referring to this article.
I wish to read more things about it!|
It’s appropriate time to make a few plans for the long run and it is time to be happy.
I’ve read this post and if I could I desire to recommend you few fascinating things or tips.
Maybe you can write next articles relating
to this article. I wish to read even more things about it!|
I’ve been browsing on-line greater than three hours lately,
yet I by no means discovered any fascinating article like
yours. It’s lovely worth sufficient for me. In my view, if all website owners and bloggers made just right
content as you did, the web will probably be a lot more useful
than ever before.|
Ahaa, its pleasant dialogue concerning this piece of writing here at this blog, I have read all that, so
now me also commenting at this place.|
I am sure this post has touched all the internet visitors,
its really really pleasant paragraph on building up new website.|
Wow, this article is nice, my younger sister is analyzing these kinds of things, therefore I am
going to inform her.|
Saved as a favorite, I love your blog!|
Way cool! Some extremely valid points! I appreciate you writing this
article and the rest of the website is also very good.|
Hi, I do believe this is an excellent site.
I stumbledupon it 😉 I’m going to revisit once again since i have saved as a favorite it.
Money and freedom is the best way to change, may you be rich and continue to
help other people.|
Woah! I’m really digging the template/theme of this
blog. It’s simple, yet effective. A lot of times it’s very hard
to get that “perfect balance” between superb
usability and visual appearance. I must say you’ve done a excellent job with
this. In addition, the blog loads very fast for me on Opera.
Outstanding Blog!|
These are actually impressive ideas in regarding blogging.
You have touched some fastidious points here.
Any way keep up wrinting.|
Everyone loves what you guys are usually up too. This type of clever work and coverage!
Keep up the terrific works guys I’ve incorporated you guys to
my blogroll.|
Hi there! Someone in my Facebook group shared this site with us so I came to take a look.
I’m definitely loving the information. I’m bookmarking and will
be tweeting this to my followers! Great blog and wonderful design and
style.|
Everyone loves what you guys tend to be up too. This kind of
clever work and coverage! Keep up the very good works guys I’ve
included you guys to our blogroll.|
Hey there would you mind stating which blog platform you’re working with?
I’m going to start my own blog in the near future but I’m having a tough time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for something completely unique.
P.S My apologies for getting off-topic but I had to ask!|
Hi would you mind letting me know which web host you’re using?
I’ve loaded your blog in 3 different web browsers and I
must say this blog loads a lot faster then most. Can you recommend a good internet hosting provider
at a reasonable price? Thanks, I appreciate it!|
I like it when people come together and share ideas. Great site, keep it up!|
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! However, how could we communicate?|
Hello just wanted to give you a quick heads up. The text in your post seem to be running off the screen in Internet explorer.
I’m not sure if this is a formatting issue or something to do with web browser compatibility but I thought
I’d post to let you know. The layout look great though!
Hope you get the problem fixed soon. Thanks|
This is a topic that’s close to my heart… Many thanks!
Where are your contact details though?|
It’s very effortless to find out any matter on net as compared to books, as I found
this post at this web page.|
Does your site have a contact page? I’m having trouble locating it
but, I’d like to send you an e-mail. I’ve got some suggestions for your blog you might
be interested in hearing. Either way, great blog and I look forward to
seeing it improve over time.|
Greetings! I’ve been following your web site for some time now
and finally got the courage to go ahead and give you a shout out from New Caney
Texas! Just wanted to tell you keep up the good job!|
Greetings from Florida! I’m bored to death at work so I decided to browse your website on my iphone during lunch
break. I enjoy the info you provide here and can’t wait to take
a look when I get home. I’m surprised at how fast your
blog loaded on my cell phone .. I’m not even using WIFI, just 3G ..
Anyhow, fantastic blog!|
Its such as you read my mind! You seem to grasp so much about this, such as you wrote the guide in it
or something. I feel that you can do with some p.c. to force
the message house a little bit, however instead of that, this is magnificent blog.
A great read. I’ll certainly be back.|
I visited several sites however the audio feature for audio songs existing at this web page is truly fabulous.|
Hello, i read your blog from time to time and i own a similar one and i
was just curious if you get a lot of spam feedback? If so how do you reduce it,
any plugin or anything you can advise? I get so much lately it’s driving me crazy so
any help is very much appreciated.|
Greetings! Very helpful advice in this particular post!
It’s the little changes that will make the greatest changes.
Thanks a lot for sharing!|
I truly love your website.. Great colors & theme.
Did you develop this web site yourself? Please reply back as I’m attempting to create my own personal blog and want to
know where you got this from or what the theme is called.
Thank you!|
Hi there! This article couldn’t be written any better! Looking through this post reminds me of my previous roommate!
He always kept preaching about this. I will forward
this information to him. Pretty sure he’s going to have a good read.
Thank you for sharing!|
Wow! This blog looks just like my old one! It’s on a completely different
subject but it has pretty much the same layout and design. Great
choice of colors!|
There’s certainly a lot to learn about this topic.
I really like all of the points you have made.|
You’ve made some really good points there. I checked on the net to find out more about the issue and found
most individuals will go along with your views on this website.|
What’s up, I log on to your blog regularly.
Your humoristic style is awesome, keep up the good work!|
I simply could not leave your web site before suggesting that I extremely loved the standard information a person provide for your guests?
Is going to be back frequently to check out new posts|
I wanted to thank you for this wonderful read!! I absolutely enjoyed every little bit of it.
I’ve got you book-marked to look at new stuff you post…|
Hi, just wanted to tell you, I liked this article. It was inspiring.
Keep on posting!|
I leave a response when I like a post on a website or if
I have something to contribute to the discussion. Usually it is triggered by the fire communicated in the article I read.
And on this post JavaScript Exercise – Social Software. I was excited enough to post a comment
🙂 I do have a couple of questions for you if it’s okay.
Could it be just me or do a few of the remarks come across like coming
from brain dead people? 😛 And, if you are posting on other
places, I would like to follow you. Could you list all of all your shared pages like your linkedin profile, Facebook page or twitter feed?|
Hello, I enjoy reading through your article. I wanted to write
a little comment to support you.|
I always spent my half an hour to read this webpage’s posts every day along with a mug of coffee.|
I always emailed this web site post page to all my friends,
since if like to read it after that my friends will too.|
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on various websites for about a year and am concerned about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any kind of help would be greatly appreciated!|
Hi! I could have sworn I’ve been to this blog before but after going through many of
the articles I realized it’s new to me. Regardless, I’m definitely pleased I stumbled
upon it and I’ll be bookmarking it and checking back often!|
Great work! This is the kind of info that are meant to be shared around the net.
Shame on Google for no longer positioning this submit higher!
Come on over and seek advice from my website . Thank you =)|
Heya i’m for the first time here. I came across this board and I find It
really useful & it helped me out a lot. I hope
to give something back and help others like you aided me.|
Greetings, I do believe your site may be having internet browser compatibility problems.
Whenever I look at your site in Safari, it looks fine however, if opening in I.E.,
it’s got some overlapping issues. I simply wanted to provide you with a quick heads up!
Other than that, great website!|
Someone necessarily lend a hand to make significantly posts I would state.
That is the first time I frequented your web page
and so far? I amazed with the analysis you made to make this particular put up incredible.
Magnificent process!|
Heya i am for the first time here. I found this board and I to find It truly useful &
it helped me out much. I am hoping to present something back and
aid others such as you aided me.|
Hi there! I just would like to give you a big thumbs up for your great information you have here on this post.
I am coming back to your blog for more soon.|
I every time used to read piece of writing in news papers but now as
I am a user of web thus from now I am using net for content, thanks to web.|
Your way of describing everything in this article is in fact pleasant, all can without
difficulty understand it, Thanks a lot.|
Hi there, I found your web site by the use of Google at
the same time as searching for a related matter, your web site got here up, it seems good.
I’ve bookmarked it in my google bookmarks.
Hello there, just was alert to your weblog via Google, and located that
it is really informative. I’m going to be careful
for brussels. I’ll be grateful for those who proceed
this in future. Numerous other folks shall be benefited from your writing.
Cheers!|
I’m curious to find out what blog system you have been utilizing?
I’m having some small security issues with my latest blog and I’d like
to find something more risk-free. Do you have any recommendations?|
I’m really impressed with your writing skills as well as with the
layout on your weblog. Is this a paid theme or did you modify it yourself?
Either way keep up the excellent quality writing, it’s
rare to see a great blog like this one these days.|
I am really inspired together with your writing skills and also with the layout on your weblog.
Is that this a paid subject or did you customize it yourself?
Anyway stay up the excellent quality writing,
it’s rare to peer a nice blog like this one
today..|
Hi, Neat post. There is a problem along with your site in internet explorer, might check
this? IE still is the market chief and a large component of folks will omit your wonderful writing because of this
problem.|
I am not sure where you are getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for wonderful information I was looking for this information for my mission.|
Hi, i think that i saw you visited my blog thus i came to
“return the favor”.I’m trying to find things to improve my site!I
suppose its ok to use some of your i
\
We’ve never ever come across a single case released or unpublished where inversion caused a stroke or
popped blood vessels.
my web-site: back pain (Linnea)
There are dozens of web sites out there providing recommendations
on inversion table benefits, inversion table side effects and inversion table
user reviews.
my page; help with pain (Leah)
I now realize that ‘can you lose weight without dieting’ was the best question I had
ever asked my self. It is a healthy eating plan based on typical foods and recipes of Mediterranean-style
cooking. The thing about the Mediterranean diet is that its foods
are often rich and tasty thanks to olive oil.
Genuinely no matter if someone doesn’t be aware
of afterward its up to other viewers that they will
help, so here it takes place.
The Body Power IT9910 has three inversion settings that are controlled by both a
strap and a yellow security bar.
Also visit my web blog :: help with pain
Hey! I just wanted to ask if yyou evеr Һave аny issues աith hackers?
Μy ⅼast blog (wordpress) ѡaѕ hacked and Ι ended ᥙρ losing ѕeveral
ԝeeks оff ɦard ѡork ɗue tο no ƅack սр.
Dο уοu Һave any solutions tto protect against hackers?
Мү website Free Porn Videos
Howdy! This post couldn’t be written much better! Looking at this post reminds me of my
previous roommate! He continually kept talking about this.
I will forward this article to him. Pretty sure he’s going to have a great read.
Many thanks for sharing!
The ATIS 1000 inversion table is a better choice for those on a
tighter budget or do not have lose the back pain (Ellie) space for a bigger ATIS 4000.
Instead, researches show in excellent abundance that inversion therapy works for
treating all types of pain in the how to help back pain at home (Ardis).
Initially, these binoculars for birding reviews 2013 (Julieta) are a
handful– they’re physically huge and weigh in at 2.6 pounds.
Nevertheless, think about that more recent designs are most likely
to visit out quickly. It might be worth it to sell the old ones
and also wait. Keep an eye on children playing video games
online. Do not undervalue the strategy of reductions fire in an on the internet shooter.
my web page http://www.developersratings.com/member.php?action=profile&uid=85700
The table itself is covered with two-and-a-half inches of memory foam and is noticeably more
comfortable than its un-padded/lightly cushioned competitors.
My blog post … inversion beds (Minnie)
The cost points for in-home inversion tables vary commonly sufficient
to make cost a consideration.
Feel free to visit my web blog; back therapy equipment (Dean)
lose the back pain (Art) Ironman Gravity 4000 is
definitely among the heavier inversion table competitors on our
list.
If they strike a surface at too excellent an angle, light rays that have
entered a prism can not get out.
Take a look at my webpage; best binoculars for stargazing 2012, Clay,
These are genuinely wonderful ideas in concerning blogging.
You have touched some pleasant factors here. Any way
keep up wrinting.
inversion beds – Winifred – tables will only supply short-term relief, so you might have to do it more
frequently to get a great take advantage of it.
We have actually never ever heard of a single case published
or unpublished where inversion triggered a stroke or popped blood vessels.
My blog post; exercises back pain
There are lots of sites out there offering recommendations on inversion table
advantages, inversion table dangers and inversion table inversion – Mariana,
evaluations.
Hold the tracing paper on the opposite side of the
magnifying glass from a bright item, such as a light bulb.
Here is my web blog; best binocular magnification for deer hunting [Calvin]
Blood Draining From Much lower Limbs – If you’re dealing with fluid accumulation in your much lower limbs, home inversion table (Adelaide) tables can help.
If you have been suffering from back problems and continuous discomfort, your
medical professional might recommend medications, a back pain from work; Brooks, decompression or inversion treatment.
Harry AJ9 SVSM high school graduation online player account of publicize Jordan 9 launched
NBA 93 Jordan introduced excellent around the first of all time period really ninety four time of year, but without the Jordan’s sanction, Jordan trade name
began looking to buy a considerable amount of on the
NBA, out of PennyHardaway BJ Neil Armstrong, Mitch Richmond, Latrell Sprewell into Kendall branchia each foot over the Air Jordan 9 years from
best from the NBA, can also very detailed few moments
discuss Jordan 9 demographic for the designing
concept of enlightening worldly concern.
my homepage shoes retro
That’s why I agree to provide you the very best assurance in the inversion table inversion
market.
Though, Ironman Gravity 1000 Inversion Table has some downsides but its advantages surpass them.
Visit my web site … back pan
Supporters of inversion back therapy – Kina, therapy think they mitigate
weight on the back disc and nerve endings in the spine and construct the areas between vertebrae.
table inversion (Alannah) Treatment assists to combat the results
of aging by properly lining up and reinforcing your spine.
With time, through using an inversion table, you’ll see an enhancement in blood flow which will favorably impact your everyday activities.
Visit my website :: back pan
Efficient Lock System: This inversion table has an effective lock system that remainings
the table in location when it is not in use.
Here is my page back pan (Jeffery)
The Gravity Inversion tables do not provide the ab training system that the above tables provide.
Also visit my web-site … back pain from work
Nevertheless, we discovered some modestly priced
inversion tables that deliver the exact same
level of efficiency at half the list price.
Here is my weblog; decompression for back pain, Matthew,
The research study released in the Journal of the Canadian Chiropractic Association discovered no increase in heart rate or blood
pressure with top rated inversion table (Dusty) treatment.
Inversion causes decompression of the intervertebral discs in the spine permitting them to regain their elasticity and practical resilience.
my blog … pain help, Elena,
This Pyramid, which represents the optimal, traditional Mediterranean diet, is based on the
dietary traditions of Crete and southern Italy in the 1960s.
Restaurants want your money and the way to get it is to serve you very large plates
with a lot of food and a “supersize” soft drink.
Article Source: is a vital element of everyone’s life.
Restorative inversion table cheap (Rafael) includes various degrees of inclination, from a
small angle past vertical to a total 90-degree hanging position.
There is some concern over the inversion settings: in one possible setup,
the table will certainly invert from zero to 90 degrees with
little user control.
Check out my weblog exercises back pain (Piper)
Improved Posture; Inversion Therapy assists to straighten your spinal column,
thus improving your entire body posture.
Also visit my site – lose the back pain (Son)
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
By the way, how could we communicate?
Hi there, I enjoy reading through your post. I wanted to write a little comment to
support you.
Dieses Kosmetik-Produkt aller Zeiten ist eine Serum, das Ihre Wimpern zu lang, dick und sehr
sexy macht, und Sie werden die Augen zu verführen!
REALASH ist unbestrittene N. 1 in der Welt der Wimper Conditioner – von echten Frauen, von den Dermatologen getestet, von Bloggern aus der ganzen Welt zu empfehlen.
In a new video clip quick guide, a majority Golem infraction in Clash of Clans is
damn near a game-breaking insta-win- when deployed correctly,
obviously. Just a couple of video games give you the benefit
of making a real-world clock obtainable in the game
itself. In addition to the sheer enjoyable of them!
my web site http://www.biaoyanyishu.com/
It is imperative that the store you buy from is reliable
when you are looking to buy video games. Place the pointers as
well as tricks of this short article to excellent use following time you click ‘play’ as well as, enjoy!
Ensure that you understand that your youngsters are playing games with online as well as maintain them risk-free.
Here is my weblog – http://www.adornoartes.com.br
Excellent weblog here! Also your website
quite a bit up very fast! What host are you the usage of?
Can I am getting your associate link for your host? I want my website loaded up as
quickly as yours lol
Quality content is the key to interest the users to visit the website, that’s what
this web site is providing.
Ahaa, its good conversawtion сoncerning tɦіs piece of writing аt tҺіѕ plafe аt tҺіs blog, Ӏ
Һave гead all thɑt, ѕo at tһiѕ time mе ɑlso commenting ɑt tɦіѕ ⲣlace.
Feel free tօ visit mү web ρage; Free Porn Videos
At this time I am going away to do my breakfast, afterward having
my breakfast coming over again to read further news.
Yes! Finally something about how does voice stress analysis work.
You are not a subject, but an object of glory, an object of a rare diamond that
are different from the rest of the other diamonds. It is almost as if through some sort of osmosis, Allen can feel
what specific areas of business will do well
and what areas have potential to fail. Surely God will not fail to
bless and give the ministers who can be trusted to
hold greater responsibility.
Feel free to visit my web page implant dentaire prix
Good post but I was wondering if you could write a
litte more on this subject? I’d be very thankful if you
could elaborate a little bit more. Thank you!
Look at my page … Currency Signals Club
Generally I do not read post on blogs, however I would ike to
say that this write-up very pressured me to try and
do it! Your writing taste hhas bbeen amazed me. Thznk you, very noce
article.
my web page :: pure slim garcinia and Zen cleanse
I have read so many content about the blogger lovers but this article is
genuinely a fastidious post, keep it up.
There is definately a great deal to learn about this topic.
I like all the points you’ve made.
Way cool! Some very valid points! I appreciate you penning this post
and also the rest of the website is extremely good.
What a information of un-ambiguity and preserveness of
valuable know-how about unexpected feelings.
DijitalX, gazeteciliğe gönül vermiş ve bu mesleği istediği gibi yapamasa
da insanlara doğru ve güzel bilgi aktarmayı görev
olarak gören bir insanın çabasından doğmuştur. Yazılımcı arkadaşımın desteğiyle
kopyala/yapıştır haberciliğe karşı durmak için başlattığımız girişim, emeğini savunmayı bilerek işbirliği yapan benzer sitelerin desteğiyle büyümeyi hedefliyor.
Bilim haberlerinin öne çıktığı, teknoloji ve yaşam içeriğinin de
bulunduğu DijitalX’te gündelik gelişmelerden çok astronomi,
siber güvenlik ve internet ile girişimci dünyasındaki gelişmeler yer ediniyor.
Astrofizikçilerle, girişimcilerle, sanatçılarla ve yöneticilerle yapılan röportajların yanı sıra
bilim ve teknoloji dünyasındaki etkinliklere dair haber ve videolar yer
alıyor.
DijitalX’in ana amacı, yeni neslin rutin ve sansasyonel haberlerden başını kaldırarak 3D
yazıcılar, yenilenebilir enerji, siber güvenlik ve yazılım, robotik teknolojisi ve uzay keşfi yeni alanlara
ilgi göstermesini sağlamak, bu alanlardaki bilgisini güçlendirerek hayal güçlerini zenginleştirmektir.
Sosyal medya ve üniversitelerde yapılan kampanyalara da destek vererek, ana akım medyanın çürümeye yüz tutmuş yapısından uzaklaşarak, güncel ve
trend haberleri derinlemesine ve farklı açılardan ele alan sitelerle
büyümeyi hedefliyoruz. Her yaştan insanın DijitalX’te Facebook veya Google hakkında farklı bir haber görmesini, Ay ile Mars kolonisi planlarını okumasını, Güneş Sistemini incelemesini,
hacker‘ların dünyasına
derinlemesine bakmalarını, Çin ile ABD arasındaki siber savaşı incelemelerini istiyoruz.
Biliyoruz ki Mars keşif aracı Curiosity’nin kullandığı teknolojiden, YouTube’da keşfedilmeyi bekleyen birçok değerli bilgiyi anlatmak, emek isteyen bir iş.
DijitalX, kardeş olacağı siteleri artırarak Türkiye’deki emek hırsızı ana akım
medyanın inadına tersini yapacak ve bir gün kendini kanıtlamış bir marka olacak.
Bu yolda ilerlerken niş haberlerin yanı sıra ilgilendiğimiz konuları geniş pencereden sunmaya
da çalışacağız. Sinema ve televizyon dünyasında kullanılan teknolojilerden çizim dünyasının takip ettiği yeniliklere, gıda sektöründeki değişimden havacılık sektöründeki gelişmelere kadar bilim ve tekniğin girdiği her alanı takip edeceğiz.
Tabii ki tüm bu haberlerin ve videoların arkasında, haberlerin temeli olan insanlar olacak ve onlara
da değineceğiz. Çevre, sağlık, kimya, astrofizik, matematik,
kuantum fiziği, astrobiolyoji, tarih ve psikoloji gibi birçok alanda çalışma yapan dünyanın dört bir yanındaki
insan, haberlerimizde yer alacak. Çalışmaları ve haberlerinin kaynaklarını vereceğiz ki öğrenciler daha fazla
bilgiye ulaşabilsin ve çalışmalarını güçlendirebilsin.
Bilim, Teknoloji, Mühendislik ve Matematik alanlarındaki insanlar ve gelişmelerin yanı sıra, sosyal
medyanın harmanladığı popüler kültür içinde olan bitenleri de gözden kaçırmayacağız.
İnternette insanların başına gelenler,
alışılmadık tesadüfler, kazalar ve tuhaf olaylar yaşadığımız çağın genel yapısını analiz etmeye yarayacak.
CERN’den Zürih Politeknik Enstitüsü’ne, Caltech’ten MIT’ye ve ESO’dan NASA’ya kadar bilim ve teknoloji
alanında en çok üreten ve yayım yapan kurumların çalışmalarını es geçmemek ve anlaşılır biçimde sunmak için bu
kurumlardan yardım almaya çalışacağız. Dahası, Instagram, Facebook,
YouTube, Twitter gibi sosyal medya kanallarında
öne çıkan alanındaki önemli insanlarla konuşmaya çalışacağız.
Umuyorum, sabır, kararlılık ve ekip çalışmasıyla iyi işler çıkaracağız ve birçok
insana fayda sağlayacağız.
Thank you for every other informative site. The
place else may I get that type of info written in such a perfect way?
I have a venture that I’m just now working on, and I have been on the look out for such information.
DijitalX, gazeteciliğe gönül vermiş ve bu mesleği istediği gibi yapamasa da insanlara doğru
ve güzel bilgi aktarmayı görev olarak gören bir insanın çabasından doğmuştur.
Yazılımcı arkadaşımın desteğiyle kopyala/yapıştır haberciliğe karşı durmak için başlattığımız girişim, emeğini savunmayı bilerek
işbirliği yapan benzer sitelerin desteğiyle büyümeyi
hedefliyor.
Bilim haberlerinin öne çıktığı, teknoloji
ve yaşam içeriğinin de bulunduğu DijitalX’te gündelik gelişmelerden çok astronomi, siber güvenlik ve internet ile girişimci dünyasındaki gelişmeler yer ediniyor.
Astrofizikçilerle, girişimcilerle, sanatçılarla ve yöneticilerle yapılan röportajların yanı sıra
bilim ve teknoloji dünyasındaki etkinliklere dair
haber ve videolar yer alıyor.
DijitalX’in ana amacı, yeni neslin rutin ve sansasyonel haberlerden başını kaldırarak 3D yazıcılar,
yenilenebilir enerji, siber güvenlik ve yazılım, robotik teknolojisi ve uzay
keşfi yeni alanlara ilgi göstermesini sağlamak, bu alanlardaki bilgisini güçlendirerek hayal güçlerini zenginleştirmektir.
Sosyal medya ve üniversitelerde yapılan kampanyalara da destek vererek, ana akım medyanın çürümeye yüz tutmuş
yapısından uzaklaşarak, güncel ve trend haberleri derinlemesine ve
farklı açılardan ele alan sitelerle büyümeyi hedefliyoruz.
Her yaştan insanın DijitalX’te Facebook veya Google hakkında farklı bir haber görmesini,
Ay ile Mars kolonisi planlarını okumasını, Güneş Sistemini incelemesini,
hacker’ların dünyasına derinlemesine bakmalarını, Çin ile ABD arasındaki siber savaşı incelemelerini istiyoruz.
Biliyoruz ki Mars keşif aracı Curiosity’nin kullandığı teknolojiden, YouTube’da keşfedilmeyi bekleyen birçok değerli bilgiyi
anlatmak, emek isteyen bir iş. DijitalX, kardeş olacağı siteleri artırarak Türkiye’deki emek hırsızı
ana akım medyanın inadına tersini yapacak ve bir gün kendini kanıtlamış bir marka olacak.
Bu yolda ilerlerken niş haberlerin yanı sıra
ilgilendiğimiz konuları geniş pencereden sunmaya da çalışacağız.
Sinema ve televizyon dünyasında kullanılan teknolojilerden çizim dünyasının takip ettiği yeniliklere, gıda sektöründeki
değişimden havacılık sektöründeki gelişmelere kadar bilim
ve tekniğin girdiği her alanı takip edeceğiz.
Tabii ki tüm bu haberlerin ve videoların arkasında,
haberlerin temeli olan insanlar olacak ve onlara
da değineceğiz. Çevre, sağlık, kimya, astrofizik, matematik, kuantum fiziği, astrobiolyoji, tarih
ve psikoloji gibi birçok alanda çalışma yapan dünyanın dört bir yanındaki insan, haberlerimizde yer alacak.
Çalışmaları ve haberlerinin kaynaklarını vereceğiz ki öğrenciler
daha fazla bilgiye ulaşabilsin ve çalışmalarını güçlendirebilsin.
Bilim, Teknoloji, Mühendislik ve Matematik alanlarındaki insanlar ve
gelişmelerin yanı sıra, sosyal medyanın harmanladığı popüler kültür içinde
olan bitenleri de gözden kaçırmayacağız.
İnternette insanların başına gelenler, alışılmadık
tesadüfler, kazalar ve tuhaf olaylar yaşadığımız çağın genel yapısını analiz
etmeye yarayacak.
CERN’den Zürih Politeknik Enstitüsü’ne, Caltech’ten MIT’ye
ve ESO’dan NASA’ya kadar bilim ve teknoloji alanında en çok üreten ve yayım yapan kurumların çalışmalarını es geçmemek ve anlaşılır
biçimde sunmak için bu kurumlardan yardım almaya çalışacağız.
Dahası, Instagram, Facebook, YouTube, Twitter gibi sosyal medya kanallarında öne çıkan alanındaki önemli insanlarla konuşmaya çalışacağız.
Umuyorum, sabır, kararlılık ve ekip çalışmasıyla iyi işler çıkaracağız ve birçok insana fayda sağlayacağız.
Look at my site Android
As a result, you may be rewarded for that with various discounts,
free offers and other schemes. Another big advantage
of Android devices is availability in wide price range from low
to high. Currently The site may be supposedly wanting to know $1.
Wow that was strange. I just wrote an incredibly long comment
but after I clicked submit my comment didn’t
show up. Grrrr… well I’m not writing all that over again. Regardless,
just wanted to say great blog!
The type of 23-inch screen is already placed on Apple’s website because “Discontinued. To an earth-friendly off Bluetooth, Open System Preferences, click on Bluetooth, and mark as uncheck the box near to “ON”.
Here is my website :: sell macbook, apple mac pro review, macbook gives
freedom, macbook air, computer repair, apple macbook pro, fix macbook, apple mac,app store, iphone 4 accessories, iphone
covers coupon codes, tablets for business
Do you mind if I quote a few of your posts as long as I
provide credit and sources back to your blog? My blog
is in the exact same area of interest as yours and my users
would truly benefit from a lot of the information you present here.
Please let me know if this okay with you.
Appreciate it!
Cаn І simply say wɦat a relief tօ discover ѕomeone tҺat
actually кnows աҺаt
they’гᥱ talking about օn tɦᥱ web.
Уоu certainly realize һow tⲟ ƅгing an issue
to light annd make it іmportant.
Ϻore people neᥱⅾ tο гead
tɦіѕ and understand tɦіѕ ѕide ⲟf tһе
story. Ⅰ ϲan’t believe үⲟu’ге not more popular given thhat yοu most certaiinly
possess the gift.
Μy blog: CB Passive Income Review
If ѕome onne desires tо Ƅᥱ updated ѡith latest technologies then hе must Ьe ɡо to ѕee thhis site ɑnd
Ье ᥙρ tο ɗate everyday.
Ꮋere iis myy ρage – Free Porn Videos
But what are causes behind growing interest in video production and advertising and marketing?
It’s actually ɑ nice ɑnd helpful piece oof info.
Ι am satisfied tһаt уоu
јust shared thіѕ helpful
info ԝith սs. Please stay սѕ informed like
tҺіs. Thanks fοr sharing.
ᕼere is my blog post …
Free Porn Videos
sıcak şimdi Galifianakis ile ”
Also visit my webpage – besiktas koray buyukasar
What’s Going down i amm new to this, I stumbled upon this I have
discovered It absolutely useful and it has aided me out loads.
I’m hoping to give a contribution & help other userrs like its aided me.
Great job.
My webpage :: Garcinia Thin Secrets And Lies Tv
Hі there Dear, are yoou really visiting tɦis web ρage oon a regular basis, іf ѕο after tɦat уоu աill without doubt ǥеt fastidious experience.
Αlso visit mү weblog – Free Porn Videos
Thank yߋu fоr sharing yοur thoughts.
Ⅰ гeally аppreciate уօur efforts аnd ӏ аm աaiting
fοr ʏߋur neҳt post thanks οnce аgain.
Му website … Free Porn Videos
I truly love your website.. Pleasant colors & theme. Did you create this web site yourself?
Please reply back as I’m hoping to create my very own site and would like to
find out where you got this from or just what the theme
is called. Many thanks!
Feel free to surf to my web page: albanian translator, french translation services, chinese language translation
My partner and I stumbled over here coming from a different
website and thought I might as well check
things out. I like what I see so i am just following you.
Look forward to exploring your web page for a second
time.
Ꭲhis website was… һow do ʏօu ѕay іt?
Relevant!! Finally ӏ’ᴠе found ѕomething tһat helped me.
Ꭲhanks!
Аlso visit myy homepage … Free Porn Videos
If you bet -11 on the Longhorns, you will get -110 odds.
They may have been paid handsomely for this small indiscretion, and so think there has been no harm done.
Most of the time, the dog doesn’t come in, but they hardly
notice.
Iwas pretty pleased to find this site. I need to to thank you for ones time just
for thіѕ fantastic гead!!
Ι ɗefinitely loved eᴠery ρart of
іt ɑnd і also Һave ʏⲟu book-marked too ѕee
neա stuff ߋn yⲟur wweb site.
mү web-site … Free Porn Videos
Great weblog riցht here! Additionally уօur website а lot ᥙρ νery fast!
Ꮤhаt web host arе уοu
tɦе սѕе οf? Caan ӏ ǥеt ʏߋur asskciate link οn үߋur host?
Ι ᴡant my site loaded uρ as fast ɑs
yߋurs lol
Мy web page :: Free Porn Videos
Choose intelligently. In the meanwhile, we have a wonderful Clash of
Clans upgrade sneak top for you to take pleasure in prior to the upgrade goes
real-time, courtesy of YouTube Galadon. This short article will certainly provide you every little
thing you desire or require to know about video gaming.
Also visit my web page … http://www.minecraft-family.de
My brpther suggested Ι might ⅼike tҺіѕ web site.Ηe ᴡaѕ еntirely гight.
Tһis post actually made
mʏ day. Υоu can not imagine simply ɦow much time ӏ ɦad spent
ffor tɦiѕ іnformation! Ƭhanks!
Ꮋere іѕ mу site görükle escort
I seriously love your website.. Very nice colors
& theme. Did you develop this website yourself? Please reply
back as I’m trying to create my very own blog and would love to find out where you got this from or what the theme is called.
Appreciate it!
Woah! I’m reaⅼly loving the template/themeof tҺіs site.
ӏt’ѕ simple, үet effective.
A ⅼot оf times іt’ѕ νery difficult too ցеt tҺаt “perfect balance” Ƅetween usability and appearance.
I must ѕay tɦat уⲟu’vе
ɗⲟne ɑ awesome job wwith tɦіѕ.
In addition, thee blog llads νery quick fߋr mᥱ
ⲟn Opera. Excellent Blog!
Αlso visit mу website ::Free Porn Videos
It is in point of fact a nice and helpful piece of information. I
am happy that you shared this useful information with us.
Please stay us up to date like this. Thank you for sharing.
Feel free to surf to my web page In 2016 BMW Will Launch An M Car With OLED
Great delivery. Sound arguments. Keep up the good effort.
He instructed the buyer supposed to be about how they made use of the finest materials to make their icons and how that they just gained an award in Canada for developing
quality.
Here is my homepage; adobe.com
Heya i am for the first time here. I found this board and
I find It really useful & it helped me out a lot. I hope to give something back and aid others like you helped me.
Here is my web site … link homepage – hwrezepte.de,
Wonderful items from you, man. I’ve consider your stuff previous to and
you are simply too wonderful. I really like what you’ve received here, certainly like what you’re saying and the way in which through which you assert it.
You make it entertaining and you continue to take care of to stay it wise.
I can not wait to learn much more from you. This is actually
a wonderful web site.
my blog post … g99games.com (Lily)
After lookіng ovеr a numbеr οf tҺe blοg aгtіclᥱѕ ⲟn уоᥙг ѡeƅsіtᥱ, Ӏ геallʏ liҝе yοuг tеcҺniԛue οf Ьⅼߋɡǥіng.
Ι Ƅⲟοҝ marқеԁ іt tο mү Ƅօoκmarκ աebѕіtᥱ lіѕt аnd wіjll bе ϲһecҝіng ƅаcҝ ѕⲟоn. Ꮲlеɑѕе ᴠіsіt
mу աᥱƄ ѕіtе tоо ɑnd tᥱlⅼ
mе Һօԝ ʏоᥙ fееⅼ.
Ϻу wеƄ-ѕіtᥱ Refit Tru Garcinia Cambogia
Im unsure of the honey-cinnamon drink but try this positrim drink which
is a meal replacement flushes away water from your physique and helps
in weight management.
Good day! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really appreciate
your content. Please let me know. Many thanks
I know this if off topic but I’m looking іnto starting mmy
օwn blog аnd ᴡaѕ wondering աɦat alll іs
neᥱded too get setup? Ӏ’m
assuming hhaving ɑ blog likme үоurs ᴡould cost a pretty penny?
Ι’m not very web savy sօ Ι’m not 100% certain. Αny recommendations ⲟr
advice աould be greatly appreciated.
Cheers
Lߋߋk at myy web site: Free Porn Videos
Hi there colleagues, nice post and pleasant
arguments commented here, I am in fact enjoying by these.
I like the helpful info you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I am quite certain I’ll learn lots of new stuff right
here! Best of luck for the next!
Hello! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no data backup.
Do you have any methods to stop hackers?
You simply have to create a system that enables you to make room for new games that you intend to play.
Rather, exercise some self discipline if you can. Don’t simply cross out video games since you assume they’re all
blood as well as gore!
My page – http://anodospc.gr/?option=com_k2&view=itemlist&task=user&id=48631
Saved aѕ а favorite, I like ʏοur web site!
Feel frde tօ surf tо myy website :
: Free Porn Videos
For instance, my TELEVISION’s energy outlet shuts off at 11 am, and turns again on when my FitBiit reaches three
miles (courtesy of IFTTT).
Also visit my website; hiring sound agents
Excellent pieces. Keep posting such kind of info on your site. Im really impressed by it.
Hi there, You’ve done a fantastic job. I will definitely digg it and for my part suggest to my friends. I’m confident they will be benefited from this web site.
Children are not the just one playing computer game today.
Do you take pleasure in playing video games whenever you
have a spare minute? In addition, a new training switch has likewise verified to be an useful and a
much more orderly attribute with the Summertime 2015 upgrade.
Also visit my blog Andrea
Hello to all, how is all, I think every one is getting more from this web page, and
your views are good designed for new people.
Thanks a lot for sharing this with all folks you really recognize what you’re speaking approximately!
Bookmarked. Kindly additionally seek advice from my site =).
We can have a hyperlink exchange arrangement between us
We find that many inversion table consumers put a
higher premium on durability and individual security
than preliminary cost.
My website back therapy equipment
An actually important thing to think about with the home
inversion table (Logan) table
is that you have to utilize it moderately, slowly at first.
This is a tricky one to pin down unless you are inspecting your
inversion back therapy (Chau) table face to face.
There are lots of web sites out there offering suggestions on inversion table benefits, inversion table risks and
inversion table user reviews.
Also visit my weblog pain help (Louann)
Most people don’t have to entirely invert to obtain the maximum advantages of lose the back pain (Lon) table.
After a tough day and aching muscles, you just need some R&R – thanks to the Inversion Table.
Check out my site – back therapy equipment; Tobias,
Easy to Fold: Another positive feature of this inversion table (Abby) is that
you can quickly fold it for storage functions.
Our foldable table offers exceptional benefit as it enables you to collapse
the table down for simple storage.
Review my web site – pain help – Evelyne,
what is a inversion table (Gerard) large number of business are manufacturing inversion tables but there are few business that are offering
quality products.
Exercising on an inversion table develops proper abdominal/core muscles while supporting the
back pain relief exercises at home
to avoid injury.
Awesome! Its genuinely amazing paragraph, I have got much clear
idea on the topic of from this piece of writing.
Hurrah, that’s what I was exploring for, what a material!
existing here at this weblog, thanks admin of this web page.
Loreen
I love your blog.. very nice colors & theme. Did you design this
website yourself or did you hire someone to do it for you? Plz reply as I’m looking to
construct my own blog and would like to find out where u got this from.
thanks a lot
tablet baratas
It is perfect time to make some plans for the future
and it is time to be happy. I have read this post and if I could I want to suggest you some interesting things or advice.
Perhaps you could write next articles referring
to this article. I wish to read more things about it!
This is a topic which is close to my heart… Take care! Exactly where
are your contact details though?
ᕼi theгe, juhst Ьecame alert tο уоur blog
through Google, and found tһat іt’ѕ гeally informative.
І am ǥoing tⲟ watch оut fօr brussels.
Ι աill аppreciate іf уou continue tɦіѕ in future.
Numerous people ᴡill Ƅᥱ benefited
from yoiur writing. Cheers!
Lοⲟk at mу web blog Free Porn Videos
Cardinal Pursuit 2, Free Cardinal Quest 2: the game does not mess around,
and neither do its updates. The problem is that Supercell does something that many
business in Finland do – firm trip during the summer.
my web page; http://konajavabeans.com/Every_little_thing_You_Should_Know.
I think this is one of the most important info for me.
And i am glad reading your article. But want to remark
on few general things, The web site style is perfect, the articles is really excellent
: D. Good job, cheers
Highly Durable: This inversion table what is a inversion table (Flora) made from tabular
steel makings it extremely long lasting.
I realⅼʏ like your blog.. vеry nice colors & theme.
Dіɗ уߋu design tһіѕ website
уourself οr ԁiԀ ʏߋu hide ѕomeone tߋ dο іt for үоu?
Pllz respond aѕ I’m looking tօ construct mү ⲟwn blog and wluld like tо find oout աɦere u ցot tһіs from.
many thanks
Ꮋere iѕ mү website; Free Porn Videos
constantly i used to read smaller posts which also clear their motive, and that is also happening with this
post which I am reading at this place.
37 on city raiders within your national football league team master
Charles woodson while not too long ago set out employing atmosphere Jordan 12 lowcleats general look.
Woodson uncontrolled climaxes release produced
clothing patent of invention natural leather, link-by raiders’ black-and-white
old shirt particularly stylish.
Feel free to visit my web blog … cheap jordans
It is an inversion back therapy (Louise) table that is popular for both its effectiveness and comfort.
My family every time say that I am wasting my time here at net, except I
know I am getting familiarity every day by reading such fastidious content.
My weblog … New 2013 BMW R1200GS Water Boxer Officially Revealed BMW
Have you ever thought about including a little
bit more than just your articles? I mean, what you say is important and all.
Nevertheless think of if you added some great images or videos to give your posts more, “pop”!
Your content is excellent but with images and videos, this website could certainly be one of the most beneficial in its field.
Excellent blog!
To get these loans, you need not to pledge anything.
For those with a Commonwealth Seniors Health Card as well as a WS Seniors Card, the
rebate is 50 percent and eligibility for fee deferment.
Loans range from $100 to $1500 for a very short period of 14 days
until your next paycheck.
binocular cues for depth (Madie) the rate it is excellent and still
very good image being a Nikon binoculars.
In general with these binoculars for bird watching uk [Juliane] you will certainly be
able to for example identify a person from approximately
2-3 Km.
Much larger best binoculars for hunting 2014 (Mae) have been made by amateur
telescope makers, basically using two refracting or reflecting huge telescopes.
The specific size can be determined by dividing the objective
lens by the magnification of the best binoculars for birding 2012 (Augusta).
So 7X35 is a binocular vision refers to the ability to quizlet (Ima) that can zoom 7x and has
an unbiased with a diameter of 35mm.
Kindly suggest with your proficiency couple of bands of binoculars which fits my requirements.
Visit my blog best binocular magnification for deer hunting (Flynn)
It is a simple sufficient concept but regularly misinterpreted – a light year is not a measure of time, it is a procedure of distance.
Here is my web-site: best binoculars for birding uk – Lelia,
Images getting in a binocular (or telescope) are both upside
down and the wrong way round.
Take a look at my page :: best compact binoculars under 100
Hurrah! At last I got a blog from where I be capable of truly take valuable data concerning my study and knowledge.
A multitude of business are making inversion tables but there are very few
business that are supplying quality products.
Here is my web page: back therapy equipment (Cecelia)
We are authorised suppliers of Fujinon (FujiFilm) binoculars in Australia and stock all their models.
My web page – binocular vision refers to the ability to quizlet (Roxanna)
The straight-line roofing system prism is comfy to hold and
offer much of the optical efficiency of best binoculars for hunting under 200 (Bret)
costing numerous dollars more.
Great Finishing: In addition to the strong body, this table has an outstanding
completing.
Visit my webpage – exercises back pain
I had often heard of the benefits of inversion back therapy – Leonida, treatment however had never ever experience it very first hand.
A slightly larger variation of the Conquest 32s, with
larger unbiased lenses best binoculars for stargazing 2012
better efficiency in low light.
Field of vision: The field of view of a pair of best binoculars for stargazing uk (Antonia) is figured out by its optical design.
I have been browsing online more than three hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if all website owners and bloggers made good content
as you did, the net will be much more useful than ever before.|
I couldn’t resist commenting. Very well written!|
I will immediately snatch your rss as I can’t in finding your
e-mail subscription link or e-newsletter service. Do you
have any? Please permit me recognise in order that I
could subscribe. Thanks.|
It’s appropriate time to make some plans for the future and it is time
to be happy. I’ve read this post and if I could I wish to suggest you some interesting things or suggestions.
Perhaps you can write next articles referring to this article.
I desire to read even more things about it!|
It is perfect time to make a few plans for the future and it
is time to be happy. I have learn this put up and if I could I wish to counsel you some attention-grabbing things or tips.
Maybe you can write subsequent articles referring to this article.
I wish to learn more things approximately it!|
I’ve been surfing online greater than three hours lately, but I never found any fascinating article like yours.
It is beautiful value enough for me. Personally, if all webmasters and bloggers
made just right content as you did, the net might be a lot
more helpful than ever before.|
Ahaa, its fastidious dialogue concerning this paragraph here
at this webpage, I have read all that, so now me also
commenting here.|
I am sure this article has touched all the internet users,
its really really fastidious article on building up new weblog.|
Wow, this post is good, my younger sister is analyzing these things, thus I am going to convey her.|
Saved as a favorite, I like your blog!|
Way cool! Some very valid points! I appreciate you
writing this article and also the rest of the site is really good.|
Hi, I do think this is an excellent site. I stumbledupon it 😉 I’m going to come back once again since i have bookmarked it.
Money and freedom is the best way to change, may you be rich and continue to help
other people.|
Woah! I’m really enjoying the template/theme of this website.
It’s simple, yet effective. A lot of times it’s tough to get that
“perfect balance” between superb usability and visual appearance.
I must say you have done a very good job with this.
In addition, the blog loads very fast for me on Internet explorer.
Excellent Blog!|
These are in fact impressive ideas in about blogging. You have touched some
good points here. Any way keep up wrinting.|
I love what you guys tend to be up too. This
sort of clever work and coverage! Keep up the wonderful works
guys I’ve incorporated you guys to my own blogroll.|
Hi! Someone in my Facebook group shared this website with us so I came to check it out.
I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers!
Outstanding blog and amazing design.|
Everyone loves what you guys tend to be up too. Such clever work and exposure!
Keep up the awesome works guys I’ve included you guys to my blogroll.|
Hey would you mind stating which blog platform you’re working with?
I’m looking to start my own blog in the near future but I’m having a tough time
deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different
then most blogs and I’m looking for something unique.
P.S Sorry for being off-topic but I had to ask!|
Hey there would you mind letting me know which hosting company you’re
working with? I’ve loaded your blog in 3 completely different internet browsers and I must say this blog loads a lot faster then most.
Can you recommend a good web hosting provider at a honest price?
Kudos, I appreciate it!|
I love it when people come together and share opinions.
Great website, continue the good work!|
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However,
how can we communicate?|
Howdy just wanted to give you a quick heads up. The text in your post seem to be running off the screen in Ie.
I’m not sure if this is a format issue or
something to do with internet browser compatibility but I thought I’d post to let you know.
The layout look great though! Hope you get the issue fixed soon. Cheers|
This is a topic which is near to my heart… Thank you! Where are your contact
details though?|
It’s very effortless to find out any topic on net as compared
to books, as I found this piece of writing at this
web page.|
Does your blog have a contact page? I’m having a tough time locating it but,
I’d like to shoot you an email. I’ve got some ideas for
your blog you might be interested in hearing. Either way,
great site and I look forward to seeing it expand over time.|
Hey there! I’ve been following your website for a while now and finally got the bravery
to go ahead and give you a shout out from New Caney Tx!
Just wanted to mention keep up the good job!|
Greetings from Los angeles! I’m bored to tears at work
so I decided to check out your blog on my iphone during lunch break.
I really like the info you present here and can’t wait to take a look when I
get home. I’m surprised at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, superb blog!|
Its like you learn my mind! You appear to know so much about
this, like you wrote the guide in it or something. I think that
you just could do with a few percent to force the message home a little bit, however instead of
that, this is excellent blog. A fantastic read.
I’ll certainly be back.|
I visited multiple sites except the audio feature for audio songs present at
this web page is actually excellent.|
Hello, i read your blog occasionally and i own a similar one and
i was just wondering if you get a lot of spam remarks?
If so how do you protect against it, any plugin or anything
you can advise? I get so much lately it’s driving me mad
so any help is very much appreciated.|
Greetings! Very helpful advice in this particular post!
It is the little changes that will make the most significant changes.
Thanks for sharing!|
I truly love your website.. Pleasant colors & theme. Did you build this
site yourself? Please reply back as I’m hoping to create my
own personal blog and would love to find out where you got this
from or exactly what the theme is named. Appreciate it!|
Hi there! This post couldn’t be written much better! Going through
this article reminds me of my previous roommate!
He constantly kept talking about this. I am going to send this information to him.
Fairly certain he’ll have a very good read. Thank you for sharing!|
Whoa! This blog looks just like my old one! It’s
on a entirely different subject but it has pretty much the
same layout and design. Excellent choice of colors!|
There is definately a great deal to know about this topic.
I love all of the points you have made.|
You’ve made some good points there. I checked on the
web to learn more about the issue and found most individuals will
go along with your views on this site.|
Hi, I check your blogs daily. Your writing style is awesome, keep it up!|
I simply couldn’t leave your website prior to suggesting
that I extremely enjoyed the standard info a person supply on your guests?
Is going to be again often to investigate cross-check new posts|
I needed to thank you for this good read!!
I certainly loved every little bit of it. I’ve got you book-marked to check out new
things you post…|
What’s up, just wanted to mention, I enjoyed this article. It was funny.
Keep on posting!|
I drop a leave a response each time I like a post on a site or if I
have something to valuable to contribute to the discussion. It’s triggered by the
sincerness displayed in the article I browsed.
And on this article JavaScript Exercise – Social Software.
I was excited enough to drop a comment 🙂 I actually do have
2 questions for you if it’s allright. Is it only me or does it appear like a few
of these remarks come across as if they are coming from brain dead visitors?
😛 And, if you are posting at other places, I’d like to keep up with everything new you have to post.
Would you make a list every one of your social pages like your
linkedin profile, Facebook page or twitter feed?|
Hello, I enjoy reading all of your article post. I like
to write a little comment to support you.|
I every time spent my half an hour to read this web site’s posts daily along with
a cup of coffee.|
I constantly emailed this blog post page to all my contacts,
for the reason that if like to read it then my friends
will too.|
My programmer is trying to convince me to move to .net
from PHP. I have always disliked the idea because of the
costs. But he’s tryiong none the less. I’ve been using Movable-type on numerous
websites for about a year and am nervous about switching to another platform.
I have heard great things about blogengine.net. Is there a way
I can import all my wordpress posts into it? Any kind of help would
be greatly appreciated!|
Hi! I could have sworn I’ve visited your blog before but after going through a few of
the posts I realized it’s new to me. Regardless, I’m certainly delighted I discovered it and I’ll be bookmarking it and checking back
often!|
Terrific article! That is the kind of info that are supposed to be shared around the web.
Disgrace on the search engines for not positioning this submit higher!
Come on over and talk over with my site . Thank you
=)|
Heya i’m for the first time here. I came across this board and
I find It really useful & it helped me out a lot. I hope
to give something back and aid others like you helped me.|
Greetings, I think your blog might be having browser compatibility issues.
When I take a look at your web site in Safari, it looks fine however, if opening in Internet Explorer, it has some
overlapping issues. I just wanted to give you a quick
heads up! Other than that, fantastic site!|
Someone essentially lend a hand to make significantly
articles I would state. That is the very first time I frequented your web page and up
to now? I surprised with the analysis you made to create this particular put up amazing.
Excellent task!|
Heya i am for the first time here. I came across this board and I find It
really useful & it helped me out a lot. I am hoping to give
one thing back and help others like you helped me.|
Howdy! I just want to give you a big thumbs up for
the great info you have here on this post.
I am returning to your site for more soon.|
I all the time used to read paragraph in news papers but now as I am
a user of web thus from now I am using net for articles, thanks to web.|
Your means of telling all in this article is actually fastidious, all be able to without difficulty be aware
of it, Thanks a lot.|
Hi there, I found your web site by the use of Google at the
same time as searching for a related topic, your website got
here up, it seems to be good. I’ve bookmarked it in my google
bookmarks.
Hi there, just was alert to your weblog via Google, and found that it’s really
informative. I’m going to be careful for brussels.
I will be grateful if you happen to continue this in future.
Many people will likely be benefited from your writing. Cheers!|
I’m curious to find out what blog system you are working with?
I’m having some small security problems with
my latest website and I would like to find something more safe.
Do you have any recommendations?|
I am really impressed with your writing skills and also with
the layout on your blog. Is this a paid theme or did you modify it yourself?
Anyway keep up the excellent quality writing, it’s
rare to see a great blog like this one these days.|
I’m extremely impressed along with your writing abilities and also
with the format for your weblog. Is that this a paid subject or did you customize
it your self? Either way keep up the nice high quality writing,
it is rare to see a great blog like this one these days..|
Hi, Neat post. There’s an issue together with your web
site in internet explorer, may test this? IE nonetheless is the
market leader and a good part of folks will miss your wonderful writing because of this problem.|
I’m not sure where you’re getting your info, but good topic.
I needs to spend some time learning much
more or understanding more. Thanks for excellent information I was looking for this info for my
mission.|
Hi, i think that i saw you visited my site thus i came to “return the
favor”.I’m attempting to find things to enhance my web site!I suppose
its ok to use some of your i
\
best binoculars for birding reviews with short
eye relief can also be tough to use in circumstances where it
is difficult to hold them steady.
I was pretty pleased to discover this web site. I want to to thank you for your time due to this fantastic read!! I definitely appreciated every bit of it and i also have you saved as a favorite to see new information on your blog.
, if you think about anything over 12x magnification you may desire to invest in a stand or tripod that will hold the binoculars with camera (Broderick) for you.
This is natural, considering that the front objective can not increase the size of to let in more light as the power is enhanced, so
the view gets dimmer.
Here is my blog :: binocular reviews 2014 uk (Declan)
Whenever the term “math” is mentioned, many people tend to
get intimidated sending chills down their spine. You can drive to the embarkation port of
Miami, which will take you about 12 hours, or you can fly down to Miami from Charlotte’s Douglas International Airport, which will take you about two hours.
Forty years ago there were ten places you could play, but the rooms had just a few tables.
If some one needs to be updated with most up-to-date technologies
afterward he must be pay a visit this site and be up to date everyday.
Feel free to visit my page :: enquiry (culturadigitalcampinas.org)
To learn more on treating back pain with inversion therapy, see our
thorough post on back pain relief exercises at home (Verla) pain.
Porro prism binoculars do not divided beams and best binocular size for deer hunting that reason they do not require any stage finishings.
The very best inversion table inversion [Malinda] for you will depend upon the
elements previously discussed – with the
most important one being rates.
When rating range of movement and safety features,
we considered elements such as foot restraints, lumbar support,
and inversion changes.
my web page … back pain remedies at home – Romaine –
Pretty! This was an incredibly wonderful post. Thank you for supplying this
info.
binocular cues for depth birdwatching the Prostaff 8 × 42 is
just as great as the more costly King 5 – so you can definitely conserve
some $$ by selecting them.
Love it want I would of had it years ago … thank you for a quality,
well made, right physical therapy machine!
my web page – inversion table
Check out my web blog … electric inversion table –
Daniela,
It is essentially impossible to list animals according to their sense
of vision, given that all of them have different types of vision.
my web-site :: binoculars definition (Aurelio)
A lot less light reaches your eye from compact best binoculars for hunting deer than it does from standard size binoculars.
Right now it looks like Expression Engine is the preferred blogging platform available
right now. (from what I’ve read) Is that what you are using on your blog?
Contain Handrails also: Unlike other inversion tables, Body Champ therapy table has
handrails that are specifically made to make it
more secure.
Also visit my web page; pain help
It is crucial that the establishment you buy from is trusted when you are looking to purchase video games.
This can help to conserve a great deal of time and effort in the future.
Know how long you are willing to wait.
Look into my page :: http://www.cnlsburundi.org
Just want to say your article is as amazing. The clearness in your post is simply excellent and i can assume you are
an expert on this subject. Well with your permission let
me to grab your feed to keep up to date with
forthcoming post. Thanks a million and please carry on the rewarding work.
With Flipkart \’s variety of binoculars
and optical enhancers, you can satisfy your requirements.
My homepage; binocular reviews cornell
Do yоu Һɑve ɑ spam pгօblеm оn thіѕ Ƅlⲟɡ; Ι aⅼѕο
am ɑ blоgցег,
аnd Ⅰ ᴡaѕ cuгіoᥙѕ ɑЬօսt үοuг
ѕіtսatіоn; ᴡе ɦavᥱ crеatеⅾ ѕοmе nicе ρrɑctіcеs and ᴡe ɑre ⅼoߋкing to trаɗe ѕtгatеɡiеѕ witɦ otɦегs, Ьe ѕսге tߋо ѕҺοоt
mе ɑn е-maіⅼ іf іntᥱrеѕteԀ.
mʏ һοmᥱрɑցe:
neurocell Anderson cooper
Magnificent site. A lot of helpful info here. I’m sending it
to several friends ans additionally sharing in delicious. And of course, thank you on your
effort!
my web-site – oolsa.com [Cyrus]
Do not ignore this short article! If the answer is
no, do not stress, as you are not alone.
my web-site :: tradingvideo.Ru
When initially utilizing an inversion table, starting with gentle angles is the very best method to get the full health advantages.
my web blog; back therapy equipment (Eva)
Notification that part of the videos were made
before the current clash of clans upgrade (the air sweeper update).
Comprehending the landscapes is exceptionally important to winning.
Do not hesitate to shed. It is all-natural to want to bet challengers which go
to or listed below your skill level. Nevertheless, it’s no fun to continuously lose!
Also visit my web-site – http://serenity.we-planning.com/?option=com_k2&view=itemlist&task=user&id=191818
This lower zoom also has the advantage of increasing the amount of light readily available to the camera’s sensing unit.
Also visit my homepage – binocular vision disorder (Becky)
Nylon Seat: Another good thing about this table is its nylon backrest makings it reasonably comfortable compared to other tables.
Here is my weblog :: back pain remedies at home (Charmain)
You will certainly see a brilliant circle in the center
of the eyepiece if you hold best binoculars for astronomy reviews away from your eyes and up to the light.
Ok, I usually don’t do this sort of stuff however I had to write
this to let you learn about this inversion table best (Monique).
It’s constantly convenient to be able to fall back on a guarantee
to pain help (Werner) you
get a brand-new inversion table directly from the manufacturer
if and when this happens.
Hi there it’s me, I am also visiting this
web site on a regular basis, this web site is truly fastidious and the viewers are in fact sharing nice thoughts.
Thank you a lot for sharing this with all of us you really recognise what you’re
talking about! Bookmarked. Please additionally visit my site =).
We can have a link exchange agreement among us
Though, Ironman Gravity 1000 Inversion Table has some disadvantages however its benefits exceed
them.
Also visit my blog post; back pan – Madie,
I like thᥱ valuable info yоu provide inn уοur articles.
Ι’ll bookmark уⲟur weblog аnd check again ɦere regularly.
Ӏ ɑm գuite suire I’ll learn plenty
оf neew stuff гight here! Ԍood luck
for thᥱ neхt!
Μу web page … Free Porn Videos
However, the stabilization is basically ideal when the best binoculars for coues deer hunting are made use of
while seated, which enhances the efficiency of all ISBs to some extent.
o
Fransa’da, tasarımcı, 1922 yılında İtalya’da küçük bir kasabada doğdu onun adını
yapılmış olsa
my website; http://www.koraybuyukasar.com/
When you look through a pair of best binoculars for birding 2014 (Flynn), prisms are what let you see a correctly oriented image.
First, due to the fact that best binoculars for birding reviews; Chanel, can include a great deal
of hiking, light-weight binos are preferable.
Our binoculars choice is huge, so browse the selector lists above, see our finest
selling binoculars section, or e-mail or call us with questions!
My site … binocular reviews cornell (Julius)
Comfort: In addition to electric inversion table – Teresita – table benefits and
features, you should examine the comfort it offers.
Great deals of light needs big objective lenses, which would render the binocular unwise in regards to mobility.
Feel free to visit my web blog; best compact binoculars for birding uk [Beatriz]
The size of the unbiased lens will certainly figure out how much light the
binocular can obtain best binoculars for hunting 2014 – Jamison, effective watching.
Start slowly with an inversion table best – Floy – therapy program, according
to Susan Spinasanta, senior medical editor at Spine Universe.
I’m not that much of a internet reader to be honest but your blogs
really nice, keep it up! I’ll go ahead and bookmark your website to come back
later. Many thanks
comprar tablet wolder advance
Vortex Vulture binoculars are their mid-range with a bigger, bulkier design and various products.
my blog post :: binocular reviews 2015 uk; Vonnie,
I was suggested this blog by my cousin. I am not positive whether or not
this put up is written through him as nobody else realize such distinct approximately my trouble.
You are amazing! Thanks!
This website was… how do I say it? Relevant!! Finally I have found something which
helped me. Thanks!
Here is my page Xtra booster
Calculate binocular power or magnification by dividing the focal length of the binocular tube by the focal length of
the eyepiece.
Here is my homepage … best binoculars for hunting elk (Alberta)
Full-best binocular size for deer hunting [Silas] Binoculars (like EO
Denali 8×42 or 10×42 binoculars) will certainly provide much better image quality than compact binoculars.
Whoa! This blog looks just like my old one!
It’s on a totally different subject but it has pretty much the same page layout and design.
Excellent choice of colors!
See to it you’re getting a good duplicate. Read on for more
specifics concerning a few of the brand-new functions including the Clash of Clans Summer season 2015 upgrade.
Before you head out and also spend hundreds of dollars on a video gaming system, think
of just what sort of games are readily available on each system.
Here is my homepage … http://Www.delmiehousecleaning.com
Here is my web page – hiking boots for men (Margherita)
Its such as you read my thoughts! You appear to know so much approximately
this, like you wrote the book in it or something.
I think that you simply can do with a few p.c.
to drive the message house a bit, however other than that, this is
fantastic blog. An excellent read. I’ll definitely be back.
My webpage; SUPERCARS NET Comprehensive Specifications Galleries Amp Forums
Hello, I enjoy reading all of your article post. I wanted to write a little comment to support you.
Numerous binoculars today utilize prisms which
bend the light as it enters the objective lens and helps to magnify the image as it passes through the frame.
Here is my web blog; binocular cues ap psychology
Appreciate the recommendation. Let me try it out.
Take a look at my weblog … hunting hitler history – Scot –
MOTOACTV uses Motorola AccuSense expertise and GPS to
make sure measurement accuracy of your performance.
Also visit my webpage: youtube music videos free download
Hey There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and return to read more of
your useful info. Thanks for the post. I’ll certainly comeback.
Completely multi-coated optics increase the amount of light entering
the best binoculars for hunting elk – Charis – for bright images with excellent resolution and color integrity.
It permits natural spinal decompression treatment while incorporating the latest developments and designs.
Visit my site inversion table best (Suzanna)
Wonderful website you have here but I was curious if you knew of any community forums that cover the same topics talked about in this article?
I’d really like to be a part of online community where I can get opinions from other experienced people that share the same interest.
If you have any suggestions, please let me know.
Many thanks!
With havin so much written content do you ever run into any problems of plagorism or copyright infringement?
My site has a lot of exclusive content I’ve either created myself or outsourced but it looks like a lot
of it is popping it up all over the internet without my authorization.
Do you know any ways to help prevent content
from being stolen? I’d definitely appreciate it.
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year
old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and
screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
¡Débiles son las luces, en sus frías.
Animated Feature Film was ‘Up’ Pete Docter, which also took Music (Original Score) Michael Giacchino.
Understand that your discussions together with your mate are
going to be integral for the good results or failure of the uncontested divorce.
After the last couple of updates customers rapidly noticed they just don’t have
adequate wall surfaces to do just what they desire.
Choose war games. This is the most effective way to end up being a leading
gamer. Renting computer game is considerably less expensive compared to getting them.
my site: http://www.thehoopy.com
Nice post. I was checking constantly this blog and I am impressed!
Extremely useful information particularly
the last part 🙂 I care for such information a lot.
I was looking for this certain information for a long time.
Thank you and best of luck.
Also visit my blog post :: Old Bmw X1 Versus New Bmw X1 (Emelia)
Great article.
Quality articles is the key to invite the people to pay a visit the
website, that’s what this website is providing.
It’s a pity yⲟu dօn’thave ɑ donate button! Ι’Ԁ definiitely donate
tо tɦiѕ outstanding blog!
Ⅰ suppose forr noѡ і’ll settle fօr book-marking аnd aeding үߋur
RSS feed tо myy Google account. І ⅼооk forwsard tо
fresh updates and ᴡill talk ɑbout tҺіѕ website ѡith mу Facebook ցroup.
Chat ѕoon!
Ꮮߋοk іnto mу web
site – Watch Porn
Hey there Ι am ѕo thrilled I found yοur site, ӏ reallly fond үou ƅү mistake, ᴡhile Ӏ ᴡаs looking onn
Askjeeve ffor ѕomething еlse, Regardless I аm Һere noѡ аnd
ѡould jujst like tο say thanks fⲟr ɑ tremendous post ɑnd a all гound entertaining blog (І ɑlso love thᥱ theme/design), Ӏ ԁоn’t Һave time tⲟ browse
іt ɑll att tһе moment but Ӏ Һave
saved it and also included ʏօur RSS feeds,
ѕⲟ ᴡhen Ι have time Ӏ
ᴡill bе ƅack tⲟ гead ɑ ցreat deal more,
Ρlease doo кeep սρ tɦᥱ superb ᴡork.
Stop bʏ myy Һomepage; Swipe Vault Review
Hurrah, that’s what I was exploring for, what a material!
existing here at this web site, thanks admin of this web page.
I’ve been surfing online more than 4 hours today, yet I never found any interesting article like yours.
It’s pretty worth enough for me. Personally, if all
website owners and bloggers made good content as you did, the net will be a lot more useful than ever
before.
One microscope captured our interest throughout the research study procedure: the B690A-PCT200INF-PL
binocular substance microscope from AmScope.
Here is my blog post; best compact binoculars for birding uk [Glenna]
While you have a friend on your team who helps you out with some stuff,
you can also look for a bigger hip hop music manager. Dre fell down a few slots, coming in at
number four with $33 million. Throw on some junky
jewelry, a gold or silver chain, and a few rings, and there you go, a perfectly cool hip hop look with no extra cash at all.
my homepage: rohff le rohff game 2015
Attractive portion of content. Ι simply stumbled upon yοur website ɑnd іn accessiopn capital tߋ ѕay tɦаt
Ⅰ ɡᥱt actually enjoyedd account уօur
blog posts. Ꭺnyway I’ll bе subscribingg
оn ʏօur augment ɑnd eѵen I success ʏⲟu ǥеt entry tο consistently գuickly.
Тake ɑ օοk аt my weblog:
channel drain grate cover
Fantastic beat ! I would like to apprentice at the same time
as you amend your web site, how could i subscribe for a blog website?
The account helped me a acceptable deal. I had been tiny bit acquainted of this your broadcast offered shiny transparent concept
I havе rea sо mɑny posts concerning
tһᥱ blogger lovers ᥱxcept tɦiѕ piece ߋf writing
iѕ genuinely а pleasant article, қeep
it uⲣ.
Αlso visit mү web рage ::Free Porn Videos
Hey Therᥱ. I found ʏour blog tһе usage οf msn. Tһіѕ іѕ an extdemely skartly ѡritten article.
Ι’ll ƅᥱ suree to bookmark іt and return tо гead extra oof уοur helpful іnformation. Thanjk yоu fօr tҺе post.
Ӏ ԝill ⅾefinitely comeback.
mʏ web-site Free Porn Videos
Hello there! This post could not be written any better!
Reading this post reminds me of my previous room mate!
He always kept talking about this. I will forward this article to him.
Fairly certain he will have a good read. Many thanks for sharing!
The inversion table best, Roxanna,
is designed to hold the body comfortably and firmly while hanging upside down.
Do you mind if I quote a few of your posts as long as I provide credit and sources back to your webpage?
My blog site is in the exact same niche as yours and my visitors would really
benefit from some of the information you provide
here. Please let me know if this alright with you. Thanks a lot!
Hi, everything is going sound here and ofcourse every one is
sharing data, that’s truly excellent, keep up writing.
Whatever your reason for inverting, TeeterTM top rated
inversion table [Selene] Equipment supplies a simple and comfortable technique to turn your
world upside down.
Feel free to visit my web site; fishing knots for swivels (Jonathon)
It’s amazing for me to have a web page, which is good designed
for my know-how. thanks admin
I do not know if it’s just me or if everybody else encountering
issues with your blog. It looks like some of the text
on your content are running off the screen. Can somebody else please provide feedback and let me know if this is happening to
them too? This might be a problem with my browser because
I’ve had this happen previously. Thank you
I really like what you guys are usually up too. This type of clever work and exposure!
Keep up the excellent works guys I’ve incorporated you guys to my personal blogroll.
my web-site; ig
This is how the game turns a profit: You need the energy to keep completing tasks and make a polite rating on your gigs.
As a result of this failure to pay, Kourtney’s lawyers sent a cease and
desist letter to Kim. “What happens after class is entirely up to the individuals involved, but in class a sexual response would be totally inappropriate.
Feel free to surf to my web blog kardashian hack ios
I’ll right away clutch your rss as I can not to find
your email subscription hyperlink or e-newsletter service.
Do you’ve any? Please let me recognize in order that I could
subscribe. Thanks.
my homepage – Bail bonds Pasadena ca
Ԝay cool! Տome νery valid ρoints!
І appreciate үօu penning tһіѕ ѡrite-uⲣ ɑnd аlso tҺе
rest оf the webzite іѕ really
good.
mʏ blog post … pool drain grate covers (Kala)
Fastidious answers іn return օf tҺіѕ
issue ԝith solid arguments аnd telling thе ᴡhole thing about that.
Ꮋere іѕ my webpage; Free Porn Videos
Heya i am for the first time here. I found this board and I find
It truly useful & it helped me out a lot. I hope
to give something back and aid others like you aided me.
my web blog: prestamos con asnef
If ѕome ߋne neᥱds
exper ᴠiew оn tɦᥱ topic
οf blogging аnd site-building then i ѕuggest ɦim/һеr tⲟ pay а
quick viit tɦіѕ blog, Ꮶeep սρ
thе fastidious job.
Нere іѕ mmy web рage …
Free Porn Videos
Hey there! I know this is kind of off topic but I was wondering which
blog platform are you using for this website? I’m getting fed up of WordPress because I’ve had issues with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good platform.
Paragraph writing is also a excitement, if you know after that you
can write if not it is complicated to write.
Hey! This is my first comment here so I just wanted
to give a quick shout out and tell you I genuinely enjoy
reading through your blog posts. Can you recommend any other blogs/websites/forums that go over the same subjects?
Thank you so much!
Asking the prospect if they want to sell or lease
a property is too blunt and direct. It is almost as if through some sort
of osmosis, Allen can feel what specific areas of business will do well
and what areas have potential to fail. Motion Sickness: Though there are a number of chemically-induced drugs had been provided for in the market for most consumers who frequent the road and even brave the seas,
a number of health experts swear by ginger for relieving most patients of motion sickness.
Feel free to visit my homepage – prix blanchiment des dents
Hi there! Quick question that’s completely off
topic. Do you know how to make your site mobile friendly?
My website looks weird when browsing from my iphone4. I’m trying to find a
theme or plugin that might be able to fix this problem.
If you have any recommendations, please share. Many thanks!
Hi all, here every person is sharing these kinds of
experience, therefore it’s nice to read this blog, and I used to pay a visit this webpage everyday.
Hey there! I’ve been reading your blog for a long
time now and finally got the courage to go ahead and give you a shout out from Dallas Texas!
Just wanted to say keep up the excellent work!
my homepage; camping checklist app
For most recent news you have to go to see web and on internet I found this web page as
a best site for newest updates.
Here is my website; huntington bank careers [Alan]
I’ve read some excellent stuff here. Certainly price bookmarking for revisiting.
I wonder how much effort you put to make any such magnificent informative site.
Here is my web-site; DOWNLOAD GAMES FOR FREE (Clara)
Good day! I could have sworn I’ve visited this blog before but after going through some of the posts I realized it’s new to me.
Regardless, I’m definitely pleased I came across it and I’ll be bookmarking it and checking back often!
You ought to first take a look at limit weight to see
if you can be held by the table itself.
Look at my web-site … back pan
This layer increases the quantity of light entering the eye, and improves vision in low light conditions.
Also visit my weblog :: best binoculars for birding 2014 (Randell)
I’m extremely impressed along with your writing abilities and also with
the layout for your weblog. Is this a paid subject matter or did you modify
it yourself? Anyway keep up the nice quality writing, it is uncommon to peer a nice blog like this one these days..
Look at my blog; natural clear vision does it work
Just you can feel how binoculars with camera (Dominique) fit in your hands and how well they deal with your spectacles.
Testimonials and opinions differ from person-to-person, and as such, I always
recommend reading other reviews and comparisons.
Take a look at my weblog: pain help, Sommer,
Exceptional post however I was wondering if you could write a litte
more on this topic? I’d be very grateful if you
could elaborate a little bit further. Appreciate it!
My relatives aⅼl the time saу tɦɑt Ι ɑm waseting my time Һere ɑt
web, however I қnoѡ І am ցetting familiarity ɑll tҺe time Ьy reading
ѕuch nice posts.
Feel free tߋ visit mу ɦomepage ::
swimming pool grating suppliers
You actually make it seem really easy together with your presentation but I to find this topic to be really one thing that I feel I would
never understand. It seems too complicated and very broad for me.
I’m taking a look forward in your next submit, I’ll attempt to
get the grasp of it!
Here is my webpage wikifight.ru (Kyle)
Wonderful article! We will be linking to this great content on our website.
Keep up the good writing.
My web page … Used Bmw 3 Series 325i Car In Mumbai Maharashtra
What i don’t understood is actually how you are not really a
lot more smartly-preferred than you may be right now.
You’re so intelligent. You recognize therefore considerably in terms
of this subject, produced me in my opinion believe it
from numerous varied angles. Its like men and women don’t seem to be involved unless it’s one thing to do with Lady
gaga! Your own stuffs great. All the time maintain it up!
It’s genuinely very complex in this active life to listen news on Television, so I simply use web for that purpose,
and obtain the newest information.
Hi there! I realize this is somewhat off-topic but I had to ask.
Does managing a well-established blog such as yours require a
large amount of work? I am brand new to blogging however I do write in my diary on a daily basis.
I’d like to start a blog so I can easily share my experience and views online.
Please let me know if you have any recommendations or tips for brand new aspiring bloggers.
Appreciate it!
I couldn’t resist commenting. Perfectly written!|
my webpage … todo erotico
I am now not positive the place you are getting your
information, however good topic. I needs to spend
a while finding out much more or figuring out more.
Thanks for great information I used to be on the lookout for this information for my mission.
Also visit my web site; Global Tourism Places
I believe everything published was actually very logical.
However, think on this, suppose you typed a catchier post
title? I am not saying your content isn’t solid., but what if you added a headline that
makes people want more? I mean JavaScript Exercise – Social
Software is kinda boring. You should glance at Yahoo’s home page and note how they
create post titles to get viewers to open the links.
You might add a video or a related picture or two to get
people excited about everything’ve written. Just my opinion, it could make your
posts a little livelier.
My kids and her drawn out the inversion table cheap table, this very same precise one and I was
anticipating a guitar as I dip into church then got this.
The bed is made from optimal decompression surface that
makes sure minimal friction; lose the back pain (Antoinette) body slides efficiently on the
table.
Requirement Porro Prism Binoculars: A lot of binoculars
referred to as general-purpose are basic porro prism designs.
Feel free to surf to my web-site binocular cues for depth perception include (Meagan)
Both of these designs represent their best lens covering and superior light intake and
colour reproduction.
My blog … binocular vision definition
All binoculars have a hinge to allow you to change the barrels to match the distance between your eyes.
Here is my homepage … binocular cues for depth (Sherrill)
In this case we sold the zoom best binoculars for birdwatching uk (Jamison) and got a fantastic
response from the purchaser.
I am sure this piece of writing has touched all
the internet people, its really really fastidious article on building up new webpage.
Many small companies prefer to hire SEO specialists as consultants rather than full time employees, unless they have a certain amount of websites that need to be continuously maintained and optimized.
The Internet has changed the way we attain information forever and
Google has been the main driving force and proponent behind this instant access to information. Depending on how how much time you have
you can do this about once per week. Webmaster
follows a long process to promote a website
in top search engines (Google, Yahoo and Bing).
insanlar, yerler ve iyi için Koray Büyükasar etkilenmiş olabilir şeyler
sadece çağrılmasının ardından var. Gidiş asla
Koray Büyükasar bu oldu, bu hayali ünlü dedikodu değildi sayısız önceki zamanlarda farklı ve
Also visit my web-site: siyasetçi koray büyükasar
Yoᥙr ѕtyle is reallу սniqᥙе іn сߋmρаrіѕօn tо оtҺеr fоlҝѕ I hɑνе rᥱaɗ
stսff frߋm.
Ι aрρгеciatᥱ үοuս foг ρоѕting ԝҺᥱn yօս Һɑѵе thе ⲟpрогtunitү, Ԍսeѕѕ Ι ᴡіⅼl јᥙst boοҝ mɑгк tҺiѕ bⅼοɡ.
Ɍᥱvіеԝ mу hοmеρage: nanox androx q12 review 360
What’s up, I want to subscribe for this web site to get most up-to-date updates, thus where can i do it please
assist.
Beginning inversion back therapy (Patrick) table users are prompted to start out at a 20 or 40-degree rotation and work their way slowly toward 60 or full 90-degree inversions.
Hi, i think that i saw you visited my web site so i came to “return the
favor”.I am attempting to find things to enhance
my website!I suppose its ok to use some of your ideas!!
For example, an 8×42 binocular reviews 2014 uk (Jeffrey) would have a brightness score of 5.25 (42 divided by 8),
whereas a 10 x 25 would have a rating of 2.5 (25 divided by 10).
Da jeg nevnte at jeg kun hadde satt opp med GSM nevnte han at sønnen hans hadde fått seg en GSM
jammer fra dealextreme for en slikk og en ingenting.
Big objective lenses will certainly let a-lot more light
in and allow you to see a brighter image in the evening.
Feel free to surf to my webpage best binocular magnification for deer hunting, Jonathon,
Heya i am for the first time here. I found this board and I to find It truly
useful & it helped me out a lot. I’m hoping to provide one thing again and aid others such as you helped
me.
Howdy just wanted to give you a quick heads up. The text in your article
seem to be running off the screen in Internet explorer. I’m
not sure if this is a formatting issue or something to do with web browser compatibility but I
figured I’d post to let you know. The layout look great though!
Hope you get the problem fixed soon. Thanks
işyerindeki, yolda, iş, hükümet, aile içinde,
pek çok
diğerleri bizim güven koyun hayatımızın her gün, sokakta yürürken
Feel free to visit my website … koray büyükasar skandal
Heya i’m mortgage for rental property the
first time here. I came across this board and I
find It truly useful & it helped me out much. I hope to give something back and help others like you aided me.
Each of them has a different function according to the intensity of the misspelled keywords.
Two: Research different services – Assuming that you are going to hire someone to do it for you, the next step is to research as many different services as possible.
Unlike TV, radio and other traditional marketing channels that need big budgets to be effective, SEO
can be cost effective. In this way, it is informed about the kind of information that a surfer is looking for.
At $429, Teeter Hang Ups EP 960 is among the more costly of our leading 5 top rated inversion table; Hudson,
table contenders.
Every weekend i used to pay a quick visit this site, because i wish for enjoyment, since this this website conations really
fastidious funny information too.
Wonderful, what a webpage it is! This blog
presents valuable data to us, keep it up.
The ankle locks are padded and safe and secure, but similar to many other inversion tables,
they are not necessarily very comfy.
my blog post – decompression for back pain –
Raphael –
Outstanding post however I was wondering if you could write a
litte more on this topic? I’d be very thankful if you could elaborate a little
bit further. Appreciate it!
They rely on their huge eyes, which are really larger than their brains,
to let in as much light as possible.
Look into my weblog :: binocular reviews 2015 uk
Greetings! Very helpful advice in this particular post! It
is the little changes that make the most important changes.
Thanks for sharing!
Some binoculars are perma focus and never ever need adjustment, simply receive and use them.
Here is my website :: best binocular magnification for deer hunting
I would like to thank you for the efforts you have put in writing
this blog. I’m hoping to view the same high-grade blog posts from you later on as well.
In fact, your creative writing abilities has motivated me to get my very own website now 😉
I got one of the first copies hot off the press and took it and a great
pair of best compact binoculars for birding uk with me on a recent vacation with dark skies.
Terrific article! That is the kind of information that are supposed to be shared around the web.
Disgrace on the search engines for not positioning this publish higher!
Come on over and consult with my website . Thanks =)
A really active, useful overview of birdwatching that
includes information of the best binocular size for deer hunting [Tamela] ways
to choose and use binoculars.
If you are on a tight budget plan and you think that an inversion table can actually benefit you, then this table
is the one for you.
my web-site – back pain (Emanuel)
IControl 600 is one such special inversion table by IronMan that provides terrific advantages to its users.
Look at my page – help with pain; Rodney,
Thanks for one’s marvelous posting! I quite enjoyed
reading it, you can be a great author. I will be sure to bookmark your blog and will often come back someday.
I want to encourage you to ultimately continue your great work, have a nice evening!
Other non-wide-angle binoculars have field of visions of maybe 270 ft.
at 1000 yds.
Also visit my web-site binocular reviews cnet [Vernell]
Thanks for ones marvelous posting! I definitely enjoyed reading it,
you can be a great author.I will remember to bookmark your blog and definitely
will come back later in life. I want to encourage
that you continue your great work, have a nice evening!
my blog :: Pre Owned Bmw Cars For Sale In Temple Hills
You coulⅾ dᥱfіnitеlү ѕеe уoսr ᥱntҺսsіaѕm ᴡіthіn tһе aгticle ʏօu ѡrіtе.
Thе ɑгеna hоρеѕ fօг mߋrе ρɑsѕіοnatе wгіtᥱrѕ ѕuсɦ аѕ ʏօᥙ ԝɦo ɑге not affгaіⅾ tо mentiߋn Һοᴡ tһеʏ ƅelіеνe.
At alⅼ tіmᥱs fоⅼlߋѡ үoᥙг hеагt.
Неrе іѕ my
ɦօmᥱрaɡᥱ
Omnipotence infotech Reviews on garcinia
Hey would you mind stating which blog platform you’re working with?
I’m planning to start my own blog in the near future but I’m
having a tough time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most
blogs and I’m looking for something unique.
P.S Apologies for being off-topic but I had to ask!
Here is my web blog; Greece Friendly Planet Travel
Falck henviser til at tallene kommer fra Finansnæringens Hovedorganisasjon (FNH), som viser antall
forsikringssaker.
Asking questions are genuinely pleasant thing if you are not understanding something completely, but this article gives nice understanding even.
Excellent post. I was checking continuously this weblog and I’m impressed!
Extremely helpful info particularly the final section :
) I maintain such information much. I was looking for this particular information for a long time.
Thanks and best of luck.
So, in outsourcing, cost is confined only into finished product or delivery.
In this honeymoon package you have a luxurious Seaview
Villa, complete with welcoming flowers, local Belizean chocolates, and a bottle of
Champagne. a’s emphasis in its vineyards is on sustainability.
Before you buy an inversion back therapy – Carma,
table, make certain that you make use of one that is recommended by experts
and that is actually good for your current scenario.
I følge tall fra Finansnæringens Hovedorganisasjon og NHO Service har private hjem uten innbruddsalarm har 4,5 ganger høyer risiko for innbrudd enn boliger med alarm.
I am actually thankful to tthe holder of this web page who has shared
this emormous piece of writing at at this time.
Also visit my page Cleanse Blast supplement
Excellent post however , I was wanting to know if you could write a litte more on this
topic? I’d be very grateful if you could elaborate a
little bit further. Thank you!
Magnification is one of the primary reasons
someone purchases binoculars in the first location; to enable a far off image to appear better.
Here is my page :: hunting binocular reviews 2014 (Marylin)
The balance of Inversion Table is so precise that control
of the rotation can be effected by basic arm motions.
Visit my web blog; back therapy equipment
A great binocular dealer can assist you select the best binoculars for astronomy reviews – Waldo
– that finest fit your needs.
Bushnell Legend HD 8 × 42 best binoculars for bird watching 2009 (Elida) – As the name recommends they utilize HD
glass so offer a high resolution like image.
Please suggest with your knowledge couple of bands of binoculars which fits my requirements.
Also visit my web-site: binocular vision book
Good day! I simply wish to offer you a big thumbs up for the great information you’ve got here on this
post. I’ll be returning to your site for more soon.
If you are viewing a specific binocular vision book (Leonie) model on the Procular site
simply scroll down and click on the horizontal tab that checks out Video Testimonial”.
While a poker site may give a 100% bonus, the
playing requirements to ever see that bonus are so steep that it is probably useless
for all but the highest stakes players. When you play online poker it is
impossible to pick up physical tells like you can at a live game.
This is usually a single table tourney, but you can also play this with multi-tables.
Everything is very open with a really clear clarification of the
challenges. It was truly informative. Your website is useful.
Thanks for sharing!
binocular vision disorder (Clara)
treatment can be called physical therapy for the visual system that includes the brain and eyes.
Hmm it seems like your website ate my first comment (it was
super long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog.
I as well am an aspiring blog writer but I’m still new to the whole thing.
Do you have any recommendations for first-time blog writers?
I’d certainly appreciate it.
If you desire to grow your know-how just keep visiting this site and be updated with the most up-to-date news update posted here.
Due to the cushioned ankle holders and foam rollers, these when partnered with the foam of the inversion table, makes everything really
comfy.
Also visit my web page – back pain from work
So right here we are revealing facts about among the most acknowledged inversion back therapy [Janna] tables on the market today, the Body Champ.
Simply desire tօ say your article iѕ aѕ
astoniѕhing. Tɦe cⅼеɑгnesѕ іn уⲟսr рοst iѕ
jսѕt ցгеat
and і ϲɑn aѕѕᥙme ʏοu
aге an ехрert օn thіѕ
ѕսЬјᥱct. Ϝine
wіth үߋᥙг рᥱгmіѕѕіоn alⅼօѡ mе tⲟ ɡгab үоսг
fᥱеd to κeеp uρԀаtᥱd ԝith fߋгtɦϲomіng ρߋѕt.
Ꭲɦаnkѕ ɑ mіllіօn and рleɑѕe қееρ
սⲣ tɦe ᥱnjоуаƄlᥱ wоrκ.
my ѡеblߋց: mens health journal extreme fx spray men
Anybody that has a lack of mobility or that ares
paralyzed will find that inversion chairs provide the utmost in support and stability.
Feel free to surf to my web page how to help back pain at home
(Alejandro)
The Health Mark IV Pro home inversion table – Leilani – Therapy Chair
is advised as the best option for people with lower back issues.
If the table inverts to its optimum, lots of individuals discover it tough to return to the original upright position.
Here is my site – decompression for back pain (Julio)
Celebrities are constantly searching for easy ways to stay healthy, discomfort- complimentary
and stunning … and make use of table inversion (Aileen) tables on a
regular basis.
Way cool! Some very valid points! I appreciate you writing this write-up and the rest
of the site is very good.
Utilizing inversion treatment, the Inversion Table can help
in reducing decompression for back pain (Brian) stress by
alleviating pressure on your vertebrae discs.
Alleviate pain in the back and enhance your general health
help with pain (Claribel) inversion treatment and a brand brand-new inversion table.
Thanks a lot for sharing this with all people you actually realize what you’re speaking about!
Bookmarked. Please additionally talk over with
my website =). We will have a hyperlink change agreement between us
Gone are the days of one way marketing or merely just posting comments about your site or other
related topics. The usual SEO methods include keyword research, link
building and such. Depending on how how much time you have you can do this about
once per week. A guy named Alan Emtage, a student at the University of Mc – Gill, developed the first search
engine for the Internet in 1990.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time
a comment is added I get three e-mails with the same comment.
Is there any way you can remove people from that service?
Many thanks!
You’re so awesome! I don’t think I’ve truly read anything like
this before. So wonderful to find someone with a few genuine thoughts on this subject.
Seriously.. many thanks for starting this up.
This web site is something that’s needed on the web, someone with a bit
of originality!
Hey there would you mind stating which blog platform you’re using?
I’m going to start my own blog soon but I’m having a hard time making a
decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs
and I’m looking for something completely unique.
P.S Sorry for being off-topic but I had to ask!
Select an inversion table inversion – Lurlene – that can give you the optimum convenience, security,
and above all, a possibility to enjoy your inversion treatment substantially.
Vital aspects + lots of outstanding consumer reviews have actually convinced me that this is truly the very best one
out there; for me anyhow!
Here is my web page :: home inversion table – Nereida
–
The Health Mark Pro Inversion Table is the only design of
its kind in the market; it is bi-positional and non-motorized.
Here is my web site :: back pan (Shelton)
A number of inversion treatment chair require hours
or an expert to put it together.
Feel free to surf to my page :: back pain remedies at home [Franklyn]
The Teeter Hang Ups EP-950 Inversion Table is an innovative item that is
packed with innovative functions.
Feel free to surf to my web page: back therapy equipment (Miquel)
fantastic publish, very informative. I ponder why the other specialists of this sector don’t understand this.
You must continue your writing. I am confident, you have a great readers’ base already!
Take a look at my web blog – 2014 BMW K1600GTL Review
In time, through utilizing an inversion table, you’ll see
an improvement in blood flow which will favorably impact your daily activities.
Also visit my webpage; back pain relief exercises at home (Clara)
Hi there! This blog post couldn’t be written much better! Reading through this article reminds me of my
previous roommate! He constantly kept talking about this.
I will send this information to him. Fairly certain he’ll have
a very good read. Many thanks for sharing!
Overall, this inversion table – Marion – is better than other tables readily available in the market.
A lot of the inexpensively made inversion tables have a restricted range
of motion which defeats the entire purpose of inversion table cheap (King) therapy.
You actually make it seem so easy with your presentation but I find this matter to be really something that I think I would never
understand. It seems too complex and extremely broad for
me. I am looking forward for your next post, I will try to
get the hang of it!
Hello, this weekend is good in support of me, because this time i am reading this enormous educational post
here at my home.
What a stuff of un-ambiguity and preserveness of precious experience on the topic
of unexpected emotions.
My web page webpage (Elva)
Another helpful building aspect is the liberal use of
foam padding, which is found from the top rated inversion table
to the head rest to the ankle lock.
You simply have to use this inversion table cheap (Annie) for
a couple of minutes whenever you feel discomfort in your back.
Bu sonuçta şirket başlattı ve ABD’deki
görmesini sağladı bu koleksiyon oldu
Here is my homepage … koray büyükasar kimdir
Buyers ought to think about placing bulk orders for those who wish to follow
up on table testimonials.
my webpage: back pain remedies at home (Phillis)
Hey there would you mind sharing which blog platform you’re using?
I’m going to start my own blog soon but I’m having a difficult time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style
seems different then most blogs and I’m looking for something completely unique.
P.S Apologies for getting off-topic but I had to ask!
I like it. The inversion back therapy – Chun
– takes a while to obtain used to. A couple of minutes a day
makes a distinction.
Howdy exceptional blog! Does running a blog like this require a large amount of work?
I have absolutely no understanding of coding but I had been hoping to start my own blog in the near future.
Anyway, if you have any recommendations or techniques for new blog owners please
share. I know this is off subject nevertheless I just needed to ask.
Thank you!
Hello fantastic blog!Does running a blog like this taie a great deal oof
work? I have very little understanding oof coding however I
was hoping to start my own blog soon. Anyway, should you have any ideas or tips for new blog owners
please share. I understand this is off subject however I juhst had to ask.
Appreciate it!
My web-site – get your ex back with law of attraction (Bob)
If you desire to get much from this article then you have to apply such strategies to your won web site.
Here is my page … huntington bank app (Hanna)
Also visit my homepage :: camping world truck series
Also visit my blog huntington beach restaurants, Alejandra,
my blog camping gear storage (Everette)
Feel free to visit my web-site – camping gear near me
My weblog huntington bank routing number (Regena)
Hello! I’ve been reading your site for some time now and finally got the bravery to go ahead and give you
a shout out from Houston Texas! Just wanted to say
keep up the excellent work!
Here is my website huntington bank routing number (Catalina)
I have read several just right stuff here. Certainly price bookmarking for revisiting.
I wonder how so much effort you put to create the sort of wonderful
informative website.
Take a look at my site :: camping gear sale
Stop by my web-site; hiking boots
It’s great that you are getting ideas from this piece of writing as well as from our discussion made here.
De fleste oppfatter innbruddsalarm som et godt tiltak når man skal sikre
boligen sin mot innrbuddstyver.
Also visit my site – camping tents amazon
Here is my website camping world locations (Larry)
Very nice post. I certainly appreciate this website.
Thanks!
Also visit my website :: camping gear, Ernesto,
My site camping tents at target (Monte)
Hi there! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on.
Anny suggestions?
My web-site; Binary options trading Signals pro
I’m curious to find out what blog system you have been using?
I’m having some minor security problems with my latest website and
I would like to find something more safeguarded.
Do you have any suggestions?
My site :: hiking trails in colorado, Mariel,
Check out my blog; camping checklist for rv (Celia)
Here is my blog: huntington beach restaurants (Natasha)
Hello i am kavin, its my first occasion to commenting anywhere, when i read this article i thought i could also make comment due to this
sensible piece of writing.
Thanks for finally writing about > JavaScript Exercise – Social Software < Loved it!
It’s really a nice as well as useful piece of info.
I’m glad that you just shared this helpful info with us.
Please keep us informed. Many thanks for sharing.
Check out my website … coconut oils
My web page hiking trails near me app (Florine)
Alternatively, it would be significantly better to
Avoid all those chemicals by adding some frozen fruit juice mix to some seltzer water.
Although it is medically not as life threatening as that but
it can leave horrible scars on a woman’s body and also on her mental and psychologically well being.
Her very first question during the assessment was wanting to know what
exercises she could do to help her get rid of the se débarrasser du cellulite on the back of her
legs which she then showed me.
Feel free to visit my web page – fishing boats nj (Nancy)
Why viewers still use to read news papers when in this technological world
all is accessible on net?
Here is my website … 2015 Bmw 320i Sedan
Gaming on mobiles gadgets there are also created
for the iPhone app development company which really give the
app. Java is known mainly for a pixel dungeon cheats holiday staple: an entertaining element and enjoy throughout.
Let’s see some exciting applications on the castle’s overview.
Game ConsolesDuring 2010, adding pixel dungeon cheats that the
ambitious project that really come out of fun and your children. If you know what you should
have to offer than just calling functions.
My family always say that I am wasting my
time here at net, except I know I am getting knowledge all the time by reading such
pleasant content.
Feel free to visit my web site: Bmw Z4 P Jpg
Hello to all, how is the whole thing, I think every one is
getting more from this web site, and your views are fastidious for new users.
Good post, i definitely enjoy this fantastic website,
keep posting.
Stop by my web blog; earthing mat for dogs (http://www.smore.com)
There are many kitchen accessories stores from, which you can choose
to buy items, which you require. Both also have their safety risks -they do produce high temperatures after all.
A good place to shop is a wholesale furniture
liquidator.
my website :: meat grinder ebay
My web blog; fishing kayak walmart, Josephine,
Unquestionably consider that that you stated. Your favourite reason seemed
to be at the net the simplest factor to understand of.
I say to you, I definitely get annoyed whilst people think about issues that they
plainly do not recognise about. You controlled to hit the nail
upon the top as smartly as outlined out the whole thing without having side effect ,
other people can take a signal. Will probably be back to get
more. Thank you
Review my web-site :: causes of muscle aches in Legs And arms
my blog post … hunting hitler 2015 (Marcelino)
Here is my website :: camping checklist food (Temeka)
Also visit my web site – camping checklist for baby
Hello There. I found your blog using msn. This is an extremely well written article.
I will be sure to bookmark it and return to read more of your useful info.
Thanks for the post. I’ll definitely return.
You arre so awesome! I do not believe I have read something like tgis before.
So wonderful to find someone with a few original thoughts on his
subject matter. Seriously.. many thanks for starting this up.
This website is something that is needed on the internet,
someone with a bbit of originality!
Here is my webpage :: watch online free (https://www.reddit.com/r/nashville/comments/3ryj2m/crit_watch_crimson_peak_2015_full_movie_free/)
Have a look at my webpage: camping tents amazon (Darren)
Spot on with this write-up, I seriously feel this
site needs far more attention. I’ll probably be returning to see more, thanks
for the advice!
Oh my goodness! Impressive article dude! Thank you, However I am experiencing problems with your
RSS. I don’t know the reason why I cannot subscribe to it.
Is there anybody getting identical RSS issues?
Anyone that knows the answer can you kindly respond?
Thanx!!
Check out my blog – Recommended Web site; navegadores.pt,
After I initially commented I seem to have clicked the
-Notify me when new comments are added- checkbox and from now on every time
a comment is added I get 4 emails with the exact same
comment. There has to be a way you can remove me from that service?
Thanks!
Hello, this weekend is fastidious for me, as this moment i am reading this great educational piece of
writing here at my residence.
I have been browsing online more than three hours today, yet I never found
any interesting article like yours. It is pretty worth enough for me.
In my view, if all webmasters and bloggers made
good content as you did, the internet will be much more useful than ever before.
My web blog … Bmw 5 Series Sunroof Street Mitula Cars
Here is my web blog – camping recipes (Ian)
After exploring a few of the blog posts on your
web site, I honestly appreciate your technique of blogging.
I added it to my bookmark site list and will be checking back in the near future.
Take a look at my web site too and tell me your opinion.
We would suggst this system for anyone that wants to decrease their consumption of tar and nicotine, or perhaps is wanting help quit smoking.
my weblog Micah
Thhis is the right web site for anyone who wants to find out
about thiss topic. You understand so much its almost tough to argue with you (not that I realy
will needd to…HaHa). Youu definitely put a fresh spin on a
topic that’s been written about for ages. Wonderful stuff, just great!
Check out my web site … adantages of body language in communication (Dorine)
Feel free to surf to my homepage hiking trails near mechanicsburg
pa [Zoe]
Also visit my site :: hunting hitler imdb (Emma)
My blog post hiking trails near memphis (Florian)
I visited multiple web pages however the audio feature for audio songs current at this website
is in fact superb.
bookmarked!!, I love youur website!
my blog: ex factor guide free ebook
I’m extremely impressed with your writing skills and also with the
layout on your blog. Is this a paid theme or did you modify it yourself?
Either way keep up the nice quality writing, it’s rare to see a great blog like this one nowadays.
Since mobile phones entertainment are – you’ll find in the company road riot hack
announced today. The significant success factor of
graphical is the early day of slot and is definitely best for improving one’s skills.
What’s Going down i’m new to this, I stumbled upon this I’ve found It positively helpful and it
has aided me out loads. I hope to give a contribution &
aid other customers like its aided me. Great job.
As mentioned, bamboo clothing styles are a popular phenomenon that has
taken hold recently. This is the diet supplement that she and her sister endorse.
But once you’ve been there, you will remember it forever for its outstanding natural
splendors or the captivating 3000-years old history.
my weblog: kim kardashian hollywood cheats
I read this article completely on the topic of the resemblance of laterst and preceding technologies, it’s amazing article.
I like it when folks get together and share views.
Great site, keep it up!
My family members every time say that I am killing my time here at net, but I know I
am getting familiarity everyday by reading thes pleasant articles.
Svakstrøm kan også bistå med service på
diverse typer innbruddsalarmer og innbruddsalarmanlegg som Premier,
Agility 3, Texecom og flere.
Everything is very open with a precise clarification of the challenges.
It was definitely informative. Your site is extremely helpful.
Thanks for sharing!
Here is my weblog forex binary options trading signals
Thank you for sharing your thoughts. I really appreciate your efforts and I will be waiting for your
further write ups thank you once again.
It’s a pity you don’t have a donate button! I’d certainly donate to this
outstanding blog! I suppose for now i’ll settle for bookmarking
and adding your RSS feed to my Google account. I look forward
to new updates and will share this site with my Facebook group.
Chat soon!
gerçekleşmesi O çok sevdim müzik
Take a look at my blog post; koray buyukasar tecavuz
It’s truly a great and useful piece of info.
I am happy that you simply shared this useful info with us.
Please keep us up to date like this. Thank you for sharing.
I am genuinely grateful to the holder of this site who has shared
this enormous paragraph at at this time.
Hello! I know this is kinda off topic but I was wondering if you
knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m
having difficulty finding one? Thanks a lot!
Hello friends, its impressive piece of writing regarding cultureand fully explained, keep it up all
the time.
Keep on writing, great job!
Excellent blog! Do you have any tiips for aspireing writers?
I’m hoping to start my own site soon but I’m a little loost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There are
soo many choices out there that I’m completely ovberwhelmed ..
Anny recommendations? Many thanks!
Here is my site – Jazz Guitar Video Masterclass Volume 2
Program (http://Www.Sagalina.Com/Index.Php?Do=/Blog/83144/Ideas-To-Find-Out-The-Instrument-And-Rock-And-Roll-Out/)
Nowadays, there was walking war robots hack only few games available for download purpose.
There is also due to its cave. Among mobile games are not
liking the game publishers should invest in the gambling community and the App
Store.
There are various websites offering free mobile games can be received while you hollywood story cheats take shortcuts to give players the
access of playing games online too. Through its multi player games, now the requirements of this game for auditions.
However, games such as action, puzzle, adventurous, snake,
pool and many of the users to personalize their phones
and make your customer base to perform all the time and as an entertaining element.
Attractive component of content. I just stumbled upon your blog
and in accession capital to claim that I acquire actually loved account
your weblog posts. Anyway I will be subscribing on your feeds
or even I fulfillment you get right of entry to persistently quickly.
What Platforms Can” Angry Bird on your handset.
You can play mobile pokies for fun and relaxing.
Like chess is a very rewarding experience for an Enhanced web browsing
of flash games at affordable cost for successful development Project.
Using the standard spider-man unlimited hack
manually. The aim is to clear all the customized requirements.
Good day! This is my 1st comment here so I just wanted
to give a quick shout out and tell you I genuinely enjoy reading through your blog posts.
Can you recommend any other blogs/websites/forums that go over the
same subjects? Thank you!
I’ve been surfing online more than 2 hours today, yet I never found any
interesting article like yours. It is pretty worth enough for
me. In my opinion, if all site owners and bloggers made good content as you did, the internet will be a lot more useful than ever before.|
I couldn’t refrain from commenting. Well written!|
I will immediately seize your rss as I can not find your email subscription link or newsletter service.
Do you have any? Kindly allow me recognize in order that I may just subscribe.
Thanks.|
It is the best time to make some plans for the future and it’s time to be happy.
I have read this post and if I could I desire to suggest
you some interesting things or tips. Perhaps you can write next articles referring to this article.
I want to read even more things about it!|
It’s perfect time to make some plans for the long run and it
is time to be happy. I have learn this post and if I could I wish to suggest you few fascinating issues or tips.
Maybe you can write subsequent articles relating to this article.
I desire to learn even more issues about it!|
I’ve been surfing on-line more than 3 hours as of
late, but I never found any fascinating article like yours.
It is pretty value sufficient for me. In my opinion,
if all website owners and bloggers made good content as you did, the web will probably be much more helpful
than ever before.|
Ahaa, its nice discussion regarding this post here at this website,
I have read all that, so at this time me also commenting
here.|
I am sure this paragraph has touched all the internet people,
its really really nice post on building up new webpage.|
Wow, this post is good, my younger sister is analyzing these kinds of
things, thus I am going to tell her.|
Saved as a favorite, I love your website!|
Way cool! Some extremely valid points! I appreciate you penning this article and the rest of the website is also
really good.|
Hi, I do think this is a great site. I stumbledupon it 😉 I’m going to come
back once again since i have book-marked it. Money and freedom is the best way to change, may you be rich and continue to guide other people.|
Woah! I’m really enjoying the template/theme of this site.
It’s simple, yet effective. A lot of times it’s challenging to get that
“perfect balance” between superb usability and visual
appeal. I must say you have done a awesome job with this. Also, the blog
loads very fast for me on Safari. Excellent Blog!|
These are really fantastic ideas in about blogging. You have touched some good things here.
Any way keep up wrinting.|
I like what you guys are up too. This kind of clever work
and reporting! Keep up the amazing works guys I’ve incorporated you guys
to my own blogroll.|
Hi! Someone in my Facebook group shared this website with us so I
came to check it out. I’m definitely enjoying the information. I’m book-marking and will be tweeting this to my followers!
Fantastic blog and terrific design.|
I like what you guys are usually up too. This sort of clever work
and coverage! Keep up the very good works guys I’ve incorporated you guys
to blogroll.|
Hello would you mind stating which blog platform you’re working with?
I’m planning to start my own blog in the near future but I’m having a difficult time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and
I’m looking for something completely unique.
P.S Apologies for being off-topic but I had to ask!|
Hello would you mind letting me know which web host you’re working with?
I’ve loaded your blog in 3 different browsers and I must say this blog
loads a lot faster then most. Can you recommend a good
web hosting provider at a fair price? Kudos,
I appreciate it!|
I like it when individuals get together and share opinions.
Great website, continue the good work!|
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! However,
how could we communicate?|
Hey just wanted to give you a quick heads up. The words in your post seem to be running off
the screen in Firefox. I’m not sure if this is a formatting issue or something to do
with browser compatibility but I thought I’d post to let you know.
The layout look great though! Hope you get the
issue fixed soon. Thanks|
This is a topic which is near to my heart… Cheers! Exactly where are
your contact details though?|
It’s very simple to find out any topic on web as compared to books, as
I found this piece of writing at this web site.|
Does your site have a contact page? I’m having a tough time locating
it but, I’d like to send you an email. I’ve got some ideas for
your blog you might be interested in hearing. Either way, great
website and I look forward to seeing it improve over time.|
Hola! I’ve been following your weblog for a long time now and finally got the courage to go
ahead and give you a shout out from Austin Texas!
Just wanted to say keep up the excellent job!|
Greetings from Carolina! I’m bored at work so I
decided to check out your blog on my iphone during lunch break.
I love the knowledge you present here and can’t wait to
take a look when I get home. I’m shocked at how quick your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow,
great site!|
Its like you learn my mind! You appear to know a lot about this, such as you wrote the e-book
in it or something. I feel that you simply could do with some p.c.
to force the message home a bit, however other than that, that is excellent blog.
A fantastic read. I’ll definitely be back.|
I visited various blogs however the audio feature for
audio songs current at this website is genuinely superb.|
Hi there, i read your blog occasionally and i own a
similar one and i was just wondering if you get a lot
of spam responses? If so how do you reduce it, any plugin or anything you can recommend?
I get so much lately it’s driving me crazy
so any support is very much appreciated.|
Greetings! Very useful advice within this post! It
is the little changes that produce the most important changes.
Thanks a lot for sharing!|
I seriously love your site.. Excellent colors & theme.
Did you build this web site yourself? Please reply back as I’m wanting to
create my very own site and would like to find out where you got this from or exactly
what the theme is named. Thanks!|
Howdy! This post could not be written much better!
Looking at this post reminds me of my previous roommate!
He constantly kept talking about this. I will send this post to him.
Fairly certain he will have a good read. Many thanks for sharing!|
Amazing! This blog looks just like my old one! It’s on a totally different subject but it has pretty much the same layout and
design. Wonderful choice of colors!|
There is definately a great deal to find out about this subject.
I like all the points you’ve made.|
You have made some decent points there. I checked on the net for additional information about the issue and found most individuals
will go along with your views on this website.|
Hi there, I read your blogs on a regular basis.
Your writing style is witty, keep it up!|
I just couldn’t leave your web site before suggesting that I really enjoyed the usual information an individual provide in your visitors?
Is gonna be again continuously to investigate cross-check new
posts|
I want to to thank you for this fantastic read!! I definitely loved every bit of it.
I have you book marked to check out new stuff
you post…|
Hi there, just wanted to say, I loved this blog post.
It was helpful. Keep on posting!|
Hi there, I enjoy reading through your post. I
like to write a little comment to support you.|
I always spent my half an hour to read this webpage’s articles
daily along with a cup of coffee.|
I every time emailed this weblog post page to all my associates, as
if like to read it then my friends will too.|
My coder is trying to persuade me to move to .net
from PHP. I have always disliked the idea because
of the expenses. But he’s tryiong none the less.
I’ve been using WordPress on various websites for about a
year and am nervous about switching to another platform.
I have heard great things about blogengine.net. Is there a way I can transfer all my wordpress posts into it?
Any help would be really appreciated!|
Hi there! I could have sworn I’ve been to this blog before but after browsing through
many of the posts I realized it’s new to me. Anyways, I’m definitely pleased I came across it and I’ll be book-marking it and checking back frequently!|
Terrific work! This is the kind of info that should be shared around the internet.
Disgrace on the search engines for not positioning this submit higher!
Come on over and consult with my web site . Thank you =)|
Heya i am for the first time here. I came across this board and I find
It truly useful & it helped me out a lot.
I hope to give something back and aid others
like you helped me.|
Howdy, I do believe your web site could be having web browser
compatibility problems. Whenever I take a look at your blog in Safari, it looks fine but when opening in Internet Explorer, it’s got some overlapping issues.
I simply wanted to provide you with a quick heads up!
Aside from that, excellent website!|
A person essentially lend a hand to make critically posts I’d
state. This is the very first time I frequented your website page and up to now?
I surprised with the analysis you made to make this actual
put up amazing. Wonderful task!|
Heya i am for the primary time here. I came across this board
and I to find It really useful & it helped me out a lot.
I’m hoping to present one thing again and aid others such as you aided me.|
Good day! I simply would like to offer you a huge thumbs up for the excellent information you have
right here on this post. I am returning to your
website for more soon.|
I every time used to study piece of writing in news papers but
now as I am a user of web therefore from now I am using net
for articles or reviews, thanks to web.|
Your means of describing everything in this paragraph is
really fastidious, all can simply understand it, Thanks
a lot.|
Hello there, I found your website by way of Google at the same time as searching for a similar matter, your
website came up, it seems great. I have bookmarked it in my google bookmarks.
Hello there, simply was aware of your blog through Google,
and located that it is truly informative. I’m gonna watch out for brussels.
I will appreciate in the event you continue this in future.
Numerous other folks might be benefited out of your writing.
Cheers!|
I am curious to find out what blog system you have been using?
I’m experiencing some minor security issues with my latest blog and
I would like to find something more safe.
Do you have any suggestions?|
I am extremely impressed with your writing skills and also with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Either way keep up the nice quality writing, it is rare to see a great blog like this one nowadays.|
I am extremely impressed with your writing abilities and also with the format for your weblog.
Is this a paid topic or did you customize it yourself?
Either way keep up the excellent quality writing, it is uncommon to
look a great weblog like this one these days..|
Hello, Neat post. There’s a problem along with your website in web explorer, may test this?
IE still is the marketplace leader and a big component to folks will pass over your fantastic writing due
to this problem.|
I am not sure where you’re getting your info, but good topic.
I needs to spend some time learning more or understanding more.
Thanks for magnificent info I was looking for this
info for my mission.|
Hello, i think that i saw you visited my blog thus i came
to “return the favor”.I am trying to find things to improve my website!I suppose its ok to use a few of your ide\
Moreover, slotomania cheats there are hundreds of
new scenes. Plan out the latest issue of scalability as the over-priced game.
Hello, i feel that i noticed you visited my website
so i came to return the choose?.I am attempting to to find things to improve my web site!I assume its good enough to use a few of your ideas!!
Marlboro 8 filter ssystem throwaway cigarette
filters considerably eliminate tar, smoking also dangers from cigarette smoking without changing the taste of your cigarette.
Also visit my web-site smokers
After checking out a number of the blog posts on your website, I truly like your way of writing a
blog. I added it to my bookmark site list and will be checking back in the near future.
Take a look at my web site as well and tell me how you feel.
Hi there! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no
backup. Do you have any methods to stop hackers?
Now excellent WoW guides must also deal with the help of open source
platform, tease the reader into reading the main hollywood u cheats game play review, system
requirement, VoIP Services. The gadget has
been improved in its online game. You should use the promotional code for
AT&T phones. The main reason behind playing the more complicated the word that would typically be hollywood u cheats cheaper if you
tend to be cumbersome.
Hiya very nice site!! Man .. Excellent ..
Wonderful .. I will bookmark your website and take the feeds additionally?
I am happy to find so many helpful information here within the put up, we want work out
more techniques on this regard, thank you for sharing.
. . . . .
I was very happy to find this website. I wanted to thank
you for ones time just for this fantastic read!! I
definitely savored every part of it and I have you book marked to see new information on your blog.
Admiring the time and energy you put into your blog
and in depth information you offer. It’s nice to come across a
blog every once in a while that isn’t the same old
rehashed information. Fantastic read! I’ve bookmarked your site and I’m including your RSS feeds to
my Google account.
I am regular reader, how are you everybody? This piece of writing
posted at this web page is truly fastidious.
This is very fascinating, You’re an overly skilled blogger.
I’ve joined your rss feed and sit up for searching for extra of your magnificent post.
Also, I’ve shared your site in my social networks
Keep on working, great job!
Also visit my web blog … 101 Most Beautiful Places To Visit Before You Die Part Iii 99t
Also visit my web blog: hunting hitler (Virgie)
My web site: camping checklist for rv – Brianna –
Appreciating the persistence you put into your site and detailed information you present.
It’s awesome to come across a blog every once in a
while that isn’t the same out of date rehashed material.
Fantastic read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
I constantly emailed this weblog post page to all my contacts,
because if like to read it next my friends will too.
Also visit my web page: Boys Cute Dolls Images Latest Cute Dolls Profile Pictures Boys Dolls
Everything is very open with a precise explanation of the challenges.
It was definitely informative. Your website is very helpful.
Many thanks for sharing!
Here is my weblog: Bmw K1200s 2007
I believe that is one of the such a lot important information for me.
And i’m happy reading your article. However wanna statement on some common issues,
The web site taste is perfect, the articles is truly excellent :
D. Good job, cheers
He escrito una reseña Sobre la utilidad de las bases de datos de empresas, ya que much gente no tiene ni
idea de usarlas
Es una de las armas favoritas de cualquier emprendendor.
Espero que os guste
I am really loving the theme/design of your site.
Do you ever run into any internet browser compatibility problems?
A handful of my blog readers have complained about my blog not operating correctly in Explorer but looks great in Safari.
Do you have any suggestions to help fix this issue?
The other day, while I was at work, my cousin stole my apple ipad and
tested to see if it can survive a 25 foot drop, just so she can be
a youtube sensation. My iPad is now destroyed and she has 83 views.
I know this is totally off topic but I had to share it
with someone!
I’m truly enjoying the design and layout of
your blog. It’s a very easy on the eyes which makes it much more pleasant
for me to come here and visit more often. Did you
hire out a developer to create your theme? Excellent work!
It should what restaurant cheats be offering these deals with the
uniquely new technologies.
Appreciating the commitment you put into your blog
and in depth information you provide. It’s great to come across a
blog every once in a while that isn’t the same out of date rehashed
information. Fantastic read! I’ve saved your site and I’m adding
your RSS feeds to my Google account.
I am regular visitor, how are you everybody? This
article posted at this website is truly pleasant.
my weblog :: BMW E90
Hey There. I found your blog using msn. This is an extremely well written article.
I will bee sure to bookmark it and come back to learn extra of your useful information. Thank you
for the post. I’ll certainly return.
Here is my homepage – wztch (https://www.reddit.com/)
Yes! Finally something about detox foot pads.
WOW just what I was looking for. Came here by searching
for social network marketing
I was curious if you ever considered changing the structure of
your site? Its very well written; I love what youve got to
say. But maybe you could a little more in the way of content so people
could connect with it better. Youve got an awful lot
of text for only having one or two pictures. Maybe you could space it
out better?
You can certainly see your skills in the article
you write. The sector hopes for more passionate writers like you who are not afraid to mention how they believe.
Always go after your heart.
I’m amaᴢed, I have to admіt. Rarelү dо
I encouynter a blοg thаt’ѕ еգuɑllʏ educɑtіνе and amuѕing, and
ԝitһоt ɑ
ԁⲟuƅt, ʏⲟᥙ һaνе ɦit tҺҺe naіl οnn thе Һᥱаⅾ.
Tһᥱ ρгоblеm іѕ аn iѕѕuе thnat toо fеԝ
mеn ɑnd ԝоmᥱn arе sρеaқing іntеⅼⅼіցеntlʏ abօᥙt.
І’m ᴠeгʏ һaѕррy that І fօᥙnbɗ
tһіs dսring mү
hᥙnt foг sοmеtҺіng rеgaгԀіng tɦіs.
Аⅼѕⲟ іѕіt mү ѕіte :
: iproperty Singapore
What’s up, this weekend is pleasant for me, since this time i am reading
this wonderful educational article here at my residence.
Visit my weblog; huntington beach california
Here is my webpage … hunting hitler (Shanon)
Also visit my web-site camping gear (Kevin)
Feel free to visit my page … hiking boots for men (Margaret)
my webpage :: huntington beach california
Feel free to visit my site huntington beach hotels
Here is my blog post: hiking trails in colorado
Check out my weblog – hiking boots for men
My web blog – camping food (Clarice)
Hi there, I discovered your web site by means of Google
whilst searching for a comparable matter, your site got here up, it looks great.
I’ve bookmarked it in my google bookmarks.
Hello there, simply became aware of your weblog via Google, and located that it is really informative.
I am going to watch out for brussels. I will be grateful for
those who proceed this in future. Numerous people will likely
be benefited from your writing. Cheers!
Greetings from California! I’m bored at work so I decided
to check out your blog on my iphone during lunch break. I love the
information you present here and can’t wait to take a look when I get home.
I’m surprised at how fast your blog loaded on my phone .. I’m not
even using WIFI, just 3G .. Anyhow, wonderful site!
If there should be problems encountered, you can review
your research or get the phone and ask a friend,
neighbor or anyone you know have been able to put up a functional solar panel.
Without the passkey, a tarot reading can sound more like a multiple choice test than a
useful tool for finding answers. 2) You make contacts and getting to
know people to collaborate with.
Here is my web blog :: comment avoir dents blanches rapidement
I’ll right away snatch your rss feed as I can not to find your email subscription hyperlink or newsletter service.
Do you have any? Kindly let me realize in order that I may just subscribe.
Thanks.
I have been surfing on-line more than three hours nowadays, but I by no means found any fascinating artcle like yours.
It’s beautiful price sufficient for me. In my opinion, if all web oners annd bloggers made good content ass you did,
the wweb can be a lot more helpful than everr
before.
Feel free tto surf to myy site: pituitary growth hormone side effects (Frederic)
Great work! This is the type of information that are meant to be shared across the net.
Disgrace on Google for not positioning this put up higher!
Come on over and consult with my web site . Thanks
=)
Do you mind if I quote a couple of your articles as long as I provide
credit and sources back to your weblog? My blog site is in the exact same area of interest as yours and my visitors would definitely benefit
from some of the information you present here. Please let
me know if this ok with you. Thank you!
obviously like your website however you have to take a look at the
spelling on several oof your posts. Several of them are rife with
spelling problems and I find it very troublesome to tell the reality nevertheless I will certinly come back again.
Also visit my homepage – sd7 deep wrinkle
Excellent post. I am facing many of these issues as well..
Wow, this paragraph is pleasant, my younger sister is analyzing these kinds of things,
therefore I am going to convey her.
my web site; cheap bridging loan quide
Feel free to surf to my homepage – hiking backpack small (Maybelle)
Thank you for any other informative website. The place else could I get that
kind of information written in such an ideal manner? I’ve a
undertaking that I am just now operating on, and I’ve been on the
look out for such information.
Feel free to visit my webpage; camping tents for rent; Tommie,
If some one wishes expert view about blogging and site-building after that i advise him/her to visit this web site,
Keep up the good job.
Woah! I’m really enjoying the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s hard to get that “perfect balance” between user friendliness and visual appearance.
I must say that you’ve done a very good job with this.
Additionally, the blog loads very fast for me on Firefox.
Outstanding Blog!
My web site; camping gear sale (Andrew)
My web-site – hunting hitler history channel (Dalton)
My webpage – camping world rv sales, Malcolm,
Asking the prospect if they want to sell or lease a property is too blunt and direct.
The AKO system allows all the useability of a normal internet connection but with
the added bonus of being a well monitored and secured
connection. We are already becoming a rapid communication society.
Also visit my web page blanchir les dents
That really worries me since I also read a story about teens being arrested
for this because it’s considered distributing child pornography.
Guilt, mistrust and anger about pornography can hurt marriages.
Porn satisfies them, Porn relieves them, Porn gives happiness to them.
Also visit my blog post … hiking near nyc, Lieselotte,
Here is my web blog: camping tents kmart (Joan)
Hi there, I enjoy reading all of your post. I wanted to write
a little comment to support you.
Check out my website hunting hitler tv show (Roberto)
My page: fishing report md (Magda)
I do not even understand how I ended up right here, but
I believed this put up was once great. I don’t realize who you’re however certainly you are going to a
famous blogger in the event you are not already.
Cheers!
If you are going for finest contents like myself, only go to see this web page everyday because it offers feature contents, thanks
Here is my webpage million dollar duplicator
Hi, constantly i used to check weblog posts here in the early
hours in the dawn, because i love to gain knowledge of more and more.
I all the time used to read piece of writing in news papers but now as I am a user of net thus from now I
am using net for content, thanks to web.
Asking the prospect if they want to sell or lease a
property is too blunt and direct. True or false:
A 15-year mortgage typically requires higher monthly payments
than a 30-year mortgage but the total interest over the life of the loan will
be less. If you knew how to treat vomiting in your dog you would have cleaned up
the mess, put up her regular food bowl, and made sure she had plenty of water.
Take a look at my web-site clinica odontologica
Asking questions are genuinely nice thing if you are not understanding something fully,
however this paragraph gives fastidious understanding yet.
My page hunting hitler (Kandy)
Do you have a spam issue on this blog; I also am a blogger,
and I was curious about your situation; we have developed some nice practices and
we are looking to swap techniques with others, be sure to shoot me an e-mail if interested.
My homepage :: camping tents kmart (Ricky)
Here is my website :: hunting hitler tv show
Incredible! This blog looks exactly like my old one! It’s on a completely
different topic but it has pretty much the same layout and design. Superb choice of colors!
Here is my website – White Husky Dog Desktop Background Funny Cute Black Pet HD Wallpa
My blog post :: fishing report nj, Florida,
Here is my website :: hiking boots walmart
– Loren –
Here is my site; camping checklist for rv (Pauline)
Incredible quest there. What happened after? Take care!
My blog: fishing report long island (Mikki)
It is actually a great and helpful piece of info.
I am satisfied that you just shared this useful information with us.
Please stay us up to date like this. Thank you for sharing.
my website … camping checklist for rv (Millie)
We are a group of volunteers and starting a new scheme iin our community.
Your website provided uus with valuable information to work
on. You have done a formidable job and our entire ommunity will be grateful
to you.
Feel free to visit my blog Siobhan
Check out my web site … camping tents kmart (Lasonya)
She regularly attends small business networking
events, has a web page that stands out and a
facebook presence that can’t be missed. In his post Nevertheless Much more Proof of Hunkering Down Amid Little Small business,
Jeff Cornwall expresses concern that if entrepreneurs aren’t positioning their enterprises to increase, a total economic
recovery seems distant at most effective. The Roman architecture and fixtures along with all that marble
in the lobby impressed us from a visual standpoint.
You can study far more about this in an report I wrote
for American Express OPEN Forum-Five Finance Trends Every Entrepreneur Wants to Know.
Tony Romo, on the other hand, not only has the stats, but has showed his value as effectively.
How does the staff do with and without the player?
Justin Glenn, Anthony Gobern, and Adam Prolonged all had the talent to play final
season but fortunately invested a yr acquiring more powerful.
The record that has created 1 illustration is has seem from your
votes from all over fifty,000 qualified footballers who had been polled.
My wife certainly admires the decor and areas to loosen up and go through right here.
Here are the major eleven items you have to have to
do to assure that you keep a winning aggressive edge.
Several versions of the “Gas Out” myth periodically make their rounds, particularly when gas charges
get as high as they are now. But their conferences aren’t as excellent as the SEC.
He has almost certainly the stiffest competitors ever to grace the American Idol stage.
This e mail warns you not to open anything at all with the attachment
“Invitation.” The claim is that it will open an “Olympic Torch” that will ruin your complete
CD drive. To depart a game out of a Canon is to say such a game is not important enough to be really worth
remembering and most possible this game will be forgotten, if
it hasn’t been previously. First of all, the place code
have to have not be 809, for the requesting amount to hook you up with a scam.
There were 1,376,646 in 2008 and in 2009 it grew to 1,5,74,649 – an increase of 198,003.
The following represents our cash hack top eleven decisions (in no particular purchase,
although MGM Grand is the preferred) for Vegas
casino – hotels based mostly on actual previous visitation experiences.
It just doesn’t make sense, unless of course the lengthy-phrase approach
is to wipe-out the cap, at present set at $106,800, altogether, to match the exact same way the medicare
tax is currently treated. By making use of this listing and communicating with your
loved one particular, they need to be able to chill out realizing that
there are many others who enjoy and care about their new life transition.
Leslie and two reliable guards in Ryan Harrow and Lorenzo
Brown. Not absolutely sure if what I have heard of these efforts so far, is actually
thoughts blowing, but I absolutely applaud the work and a spin off is that classical music is discovering a bigger audience.
The inherent ground breaking nature of video gaming sets
it apart from other media, therefore a Canon that would incorporate this legacy
of revolutionary video video games and innovations in video gaming would be additional related.
my web site: house music songs (Gaye)
Also visit my page :: hunting hitler history channel – Thurman –
my site – camping checklist for baby (Melanie)
My website :: fishing report nj (Dakota)
Feel free to visit my web-site – hiking boots for women; Roseann,
Feel free to surf to my site – fishing report long
island (Rita)
Hello just wanted to give you a quick heads up.
The text in your article seem to be running off the screen in Internet explorer.
I’m not sure if this is a format issue or something to do with browser
compatibility but I thought I’d post to let you know. The design look
great though! Hope you get the issue resolved soon. Thanks
Review my web-site: hunting hitler
Look into my web-site :: huntington bank careers – Christiane,
Review my web site – hunting hitler 2015
I got this web page from my friend who shared with me about
this site and now this time I am browsing this website and reading very informative
content at this place.
Greetings I am so grateful I found your blog page, I really found you by mistake, while I was researching on Google
for something else, Anyhow I am here now and would just
like to say kuxos for a tremendous post andd a all round thrilling blog (I also love
the theme/design), I don’t have time to browe it all aat the moment bbut I hae book-marked it and also added your RSS feeds, so when I hzve time I will
be back to read a lot more, Please do keep up the great jo.
Feel frere to surf to my homepage – cinema
Here is my website … camping recipes (Meagan)
Here is my web-site … huntington beach hotels (Elva)
Thanks for finally writing about > JavaScript Exercise – Social Software < Loved it!
First of all I would like to say great blog!
I had a quick question that I’d like to ask if you do
not mind. I was curious to find out how you center yourself and clear your thoughts before writing.
I have had difficulty clearing my thoughts in getting my thoughts out there.
I truly do take pleasure in writing however it just seems like the first 10 to
15 minutes are usually wasted simply just trying to figure out how to begin. Any suggestions or hints?
Thank you!
Stop by my website … fishing boats (Justin)
Integrated as portion of this delivery was GAME’s allocation of the Splatoon +
Squid Inkling Amiibo and as a outcome we are unable to honour pre-orders for this item in GAME.
Feel free to surf to my website splatoon gratuit
I have wanted to write about something like this
on my web page and you gave me an idea. Many thanks.
my web blog :: locksmith greenville sc
Hey! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m
not seeing very good success. If you know of any please share.
Cheers!
my webpage – camping checklist food (Moises)
My weblog :: huntington beach california [Margarita]
my web page :: hiking near nyc [Inez]
my homepage hiking trails in colorado, Karolin,
Every weekend i used to pay a visit this website, as i want enjoyment,
for the reason that this this site conations in fact
fastidious funny material too.
Here is my blog :: camping gear walmart
I pay a visit each day some blogs and blogs to read articles, but this website provides quality based articles.
Also visit my web blog: huntington bank credit card (Elmer)
my web page :: camping checklist app (Ernie)
Hi there to every single one, it’s really a good for me to visit this site, it includes useful
Information.
Stop by my homepage camping world rv sales
There is definately a lot to learn about this topic.
I really like all of the points you made.
Also visit my web site – hiking boots walmart (Oliva)
Feel free to surf to my weblog – fishing kayak setup (Charlotte)
I know this if off topic but I’m looking into starting my
own weblog and was curious what all is needed to get set
up? I’m assuming having a blog like yours would cost
a pretty penny? I’m not very internet smart so I’m not 100% sure.
Any tips or advice would be greatly appreciated.
Thank you
Here is my web site – hiking backpack baby – Geri –
If some one needs to be updated with most up-to-date technologies therefore he must be pay
a quick visit this web site and be up to date everyday.
We’re a gaggle of volunteers and opening a brand new scheme in our community.
Your web site provided us with useful information to work on. You have performed an impressive job and our whole group will be
grateful to you.
Its not my first time to pay a visit this web page, i am browsing this website dailly and
get nice facts from here everyday.
Feel free to visit my homepage :: Recommended Resource site (wiki.fifidong.com)
Here is my web blog; camping gear walmart (Amber)
My homepage; fishing boats nj [Leandra]
The motor smoothly transitions as you click through 7 different functions.
This could have been something from a BDSM sex film. The campaign issued an emailed press release referring to an article in the Texas Observer, a far left magazine, that not only suggested that Davis’ Republican opponent might be in favor
of a ban in interracial marriage, but was in favor
on a ban on sex toys.
Hi there to every body, it’s my first pay a visit of this website;
this web site includes awesome and genuinely
excellent material for visitors.
Here is my blog – 2017 BMW X7 Car Review Top Speed
If you desire to take much from this article then you have to
apply such techniques to your won weblog.
my web blog – hiking boots for women; Dino,
Feel free to surf to my web site :: camping world catalog
[Luciana]
Thank you for the auspicious writeup. It
in fact was a entertainment account it. Glance advanced to more introduced agreeable from you!
However, how can we keep up a correspondence?
Your style is really unique in comparison to other people I
have read stuff from. Thanks for posting when you have the
opportunity, Guess I’ll just bookmark this web site.
Its such as you learn my thoughts! You seem to understand so much approximately this, such as you wrote
the ebook in it or something. I think that you just can do with
a few percent to force the message home a bit, but instead of that, this is magnificent blog.
A great read. I’ll definitely be back.
Asking questions are actually nice thing if you are not understanding anything entirely, except this article offers nice understanding yet.
Hi! Do you know iff they make any plugins
to help with SEO? I’m trying to get my blog to rank ffor some targveted keywords but I’m not seeing very good success.
If you know of any please share. Thank you!
Look into my web page … cream foor accident scarsdale (Ahmad)
Hello there! I know this is kind of off topic but I was wondering which
blog platform are you using for this site? I’m getting fed
up of WordPress because I’ve had issues with hackers and I’m looking at alternatives for another
platform. I would be fantastic if you could point me in the direction of a good platform.
A person necessarily lend a hand to make seriously articles
I would state. That is the very first time
I frequented your web page and so far? I amazed with the research you made
to create this actual submit amazing. Fantastic activity!
Saved as a favorite, I love your website!
my blog … Highly recommended Internet page (http://www.grazianobraschi.org)
When some one searches for his necessary thing, therefore he/she desires to be available that in detail, thus that thing is maintained
over here.
I am sure this paragraph has touched all the internet users, its really really fastidious paragraph on building up new blog.
Wonderful post! We are linking to this great post on our
site. Keep up the great writing.
Here is my web site :: metin2enygme.com [Shannon]
Hi there just wanted to give you a quick heads
up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show the same outcome.
Hi there, after reading this awesome article i am also happy to share my experience here with friends.
Hi there to everу bodʏ, іt’ѕ mү fігѕt ρɑу ɑ ᴠіѕіt οf tһіѕ ѡᥱƄⅼоɡ;
thіѕ ԝеbⅼоǥ
incluԁеѕ геmarқablе ɑnd іn fact
ɡоߋԁ іnfοгmatіοn іn fаνⲟг
ߋf ѵіѕіtогѕ.
Fᥱеⅼ fгее tօ ѕսгf tο my ɦomᥱⲣagе – male enhancement cream target Pharmacy rewards
Why users still make use of to read news papers when in this technological globe all is
available oon web?
Alsso visit my website: pc software to leaarn guitar
(Derick)
You’re so interesting! I don’t think I have read through something like that before.
So wonderful to discover someone with some genuine
thoughts on this issue. Seriously.. many thanks for starting this up.
This web site is something that is required on the internet, someone with a bit of originality!
I’ve been surfing online more than three hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my view, if all website owners and bloggers
made good content as you did, the net will be much more useful than ever before.|
I could not refrain from commenting. Perfectly written!|
I will immediately grab your rss feed as I can’t find your email subscription hyperlink or newsletter service.
Do you’ve any? Kindly permit me understand so that I may subscribe.
Thanks.|
It’s the best time to make some plans for the future and it
is time to be happy. I’ve read this post and if I could I wish to suggest you few interesting things or
tips. Perhaps you can write next articles referring to this article.
I want to read even more things about it!|
It is appropriate time to make some plans for the future and it’s time to be happy.
I have learn this submit and if I may I want to
recommend you some fascinating things or tips. Maybe you
can write next articles referring to this article.
I desire to read more things about it!|
I have been surfing on-line greater than three hours lately,
but I by no means discovered any fascinating article like yours.
It’s pretty value sufficient for me. In my view, if all webmasters and bloggers made good content as
you probably did, the web can be a lot more helpful than ever
before.|
Ahaa, its nice dialogue about this piece of writing here at this web site,
I have read all that, so now me also commenting at this place.|
I am sure this article has touched all the internet users, its really really good
paragraph on building up new blog.|
Wow, this post is nice, my sister is analyzing these kinds of things, so I am going to inform her.|
bookmarked!!, I really like your site!|
Way cool! Some very valid points! I appreciate you penning this
write-up and also the rest of the website is extremely good.|
Hi, I do believe this is a great website. I stumbledupon it 😉 I will revisit once again since I saved as a
favorite it. Money and freedom is the best way to change, may
you be rich and continue to guide others.|
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between user friendliness and visual appeal.
I must say you have done a fantastic job with this. Also, the blog loads super quick for me on Chrome.
Excellent Blog!|
These are actually impressive ideas in about blogging.
You have touched some pleasant factors here. Any
way keep up wrinting.|
I like what you guys tend to be up too. This sort of clever work and exposure!
Keep up the terrific works guys I’ve added you guys to blogroll.|
Hi! Someone in my Myspace group shared this website with us
so I came to take a look. I’m definitely loving the information. I’m
bookmarking and will be tweeting this to my followers!
Terrific blog and terrific design and style.|
I enjoy what you guys are up too. This sort of clever work and coverage!
Keep up the superb works guys I’ve included you guys to our blogroll.|
Hi there would you mind sharing which blog platform you’re working with?
I’m planning to start my own blog in the near future but I’m having a hard time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m looking for something unique.
P.S Apologies for getting off-topic but I had
to ask!|
Hey there would you mind letting me know which hosting company you’re utilizing?
I’ve loaded your blog in 3 different browsers and I must
say this blog loads a lot quicker then most. Can you recommend a good
web hosting provider at a fair price? Thank you, I appreciate it!|
I love it when people get together and share ideas. Great site, stick with it!|
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! However, how could
we communicate?|
Hi there just wanted to give you a quick heads up.
The text in your article seem to be running off
the screen in Safari. I’m not sure if this is a formatting
issue or something to do with browser compatibility but I thought I’d post to
let you know. The design look great though! Hope you get the issue
solved soon. Kudos|
This is a topic that is near to my heart… Cheers!
Exactly where are your contact details though?|
It’s very easy to find out any topic on net as compared to books,
as I found this piece of writing at this
web site.|
Does your website have a contact page? I’m having problems
locating it but, I’d like to shoot you an e-mail.
I’ve got some ideas for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing
it expand over time.|
Hey there! I’ve been reading your site for a while now and finally got the bravery to go ahead and give
you a shout out from Porter Tx! Just wanted to mention keep up
the fantastic work!|
Greetings from Florida! I’m bored to death at work so I decided to check out your website on my iphone during lunch break.
I love the knowledge you provide here and can’t wait to take
a look when I get home. I’m surprised at how fast your blog loaded
on my phone .. I’m not even using WIFI, just 3G .. Anyways, amazing blog!|
Its such as you read my thoughts! You seem to understand so much about this,
like you wrote the ebook in it or something. I think that you
could do with a few % to pressure the message home a bit, but instead of that, that is excellent blog.
A great read. I will definitely be back.|
I visited various websites except the audio quality
for audio songs existing at this site is in fact excellent.|
Hello, i read your blog from time to time and i own a similar one and i
was just wondering if you get a lot of spam feedback?
If so how do you reduce it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any assistance is
very much appreciated.|
Greetings! Very useful advice within this post!
It’s the little changes that make the most significant changes.
Many thanks for sharing!|
I truly love your blog.. Great colors & theme. Did you create this website
yourself? Please reply back as I’m attempting
to create my own site and would love to find out where you got this from
or exactly what the theme is named. Kudos!|
Hello there! This blog post couldn’t be written much better!
Looking at this post reminds me of my previous roommate!
He continually kept preaching about this.
I am going to forward this post to him. Fairly certain he
will have a very good read. Thanks for sharing!|
Wow! This blog looks just like my old one!
It’s on a totally different subject but it has pretty much the same layout and design. Outstanding choice of colors!|
There’s certainly a great deal to find out about this topic.
I love all of the points you have made.|
You have made some really good points there. I checked on the internet for more info about
the issue and found most individuals will go along with your views on this site.|
Hi there, I log on to your blogs like every week. Your story-telling style is
witty, keep up the good work!|
I simply could not leave your web site before
suggesting that I extremely loved the usual info an individual supply on your
guests? Is gonna be again incessantly in order to inspect new posts|
I want to to thank you for this very good read!!
I certainly enjoyed every little bit of it.
I have got you bookmarked to look at new stuff you post…|
Hello, just wanted to mention, I loved this blog post. It was helpful.
Keep on posting!|
I drop a comment each time I especially enjoy a article on a site or
if I have something to contribute to the conversation. Usually it is caused by the sincerness displayed in the article I looked at.
And on this post JavaScript Exercise – Social Software.
I was actually moved enough to leave a thought :
-) I do have some questions for you if you usually do not mind.
Is it simply me or do some of these remarks come across
as if they are coming from brain dead individuals?
😛 And, if you are posting on other online sites,
I would like to keep up with you. Would you make a list all of your public pages like your linkedin profile,
Facebook page or twitter feed?|
Hi there, I enjoy reading through your post.
I wanted to write a little comment to support you.|
I constantly spent my half an hour to read this blog’s posts everyday along with a mug of coffee.|
I constantly emailed this website post page to all my friends, for the reason that if like to read it next my friends will too.|
My developer is trying to convince me to move to .net from
PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a number of websites for about a year and am worried about switching to another
platform. I have heard very good things about blogengine.net.
Is there a way I can import all my wordpress posts into it?
Any help would be greatly appreciated!|
Hi there! I could have sworn I’ve visited your blog before but after going through some of the posts
I realized it’s new to me. Nonetheless, I’m definitely pleased I found it and I’ll be book-marking it and checking back frequently!|
Wonderful article! That is the kind of info that are supposed to be
shared across the internet. Disgrace on the search
engines for now not positioning this submit higher!
Come on over and visit my web site . Thanks =)|
Heya i am for the first time here. I found this board and I find
It truly useful & it helped me out a lot. I hope to give something back and aid others like you aided me.|
Hi there, I believe your blog might be having internet browser
compatibility problems. Whenever I take a look at your
blog in Safari, it looks fine but when opening in IE,
it has some overlapping issues. I merely wanted to give
you a quick heads up! Apart from that, great
blog!|
A person necessarily assist to make significantly posts I would state.
This is the very first time I frequented your website page and
so far? I surprised with the analysis you made to
make this particular submit incredible. Fantastic activity!|
Heya i am for the first time here. I came across this board and I in finding It truly helpful & it helped me
out much. I am hoping to offer one thing again and help others like you aided me.|
Good day! I just wish to give you a big thumbs up for your
excellent information you’ve got right here on this post. I’ll be returning to your web site for more soon.|
I every time used to read paragraph in news papers but now as I am a user of web therefore
from now I am using net for content, thanks to web.|
Your mode of explaining the whole thing in this article is really pleasant, all
be able to easily know it, Thanks a lot.|
Hi there, I discovered your site by means of Google even as looking for a related subject, your website came up, it seems to be good.
I’ve bookmarked it in my google bookmarks.
Hello there, just become alert to your blog through Google, and located that it is really informative.
I am going to watch out for brussels. I’ll appreciate if you continue this in future.
Numerous other folks might be benefited from your writing.
Cheers!|
I am curious to find out what blog platform you are utilizing?
I’m having some minor security problems with my latest
site and I would like to find something more risk-free.
Do you have any suggestions?|
I am really impressed with your writing skills and also with the layout on your weblog.
Is this a paid theme or did you customize it yourself? Anyway keep up
the nice quality writing, it’s rare to see a great blog
like this one today.|
I’m really impressed with your writing skills as well as with the format for your blog.
Is this a paid subject or did you customize it yourself?
Either way keep up the nice quality writing,
it’s rare to look a great blog like this one nowadays..|
Hi, Neat post. There’s an issue along with your website in web explorer, would check this?
IE nonetheless is the market leader and a huge part of people will
omit your magnificent writing due to this problem.|
I’m not sure where you are getting your info, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for wonderful information I was looking for this info for my mission.|
Hello, i think that i saw you visited my site so i came to “return the favor”.I’m trying
to find things to improve my site!I suppose its ok to use
some of your i
\
Feel free to visit my weblog fishing boats (Kit)
Feel free to visit my site :: camping tents kmart (Asa)
Also visit my page :: huntington beach restaurants (Kelley)
Here is my web-site; fishing boats with hucksters bargaining for fish
– Tracie –
My homepage; hiking backpack baby (Tabitha)
Check out my blog post: hiking boots for women (Tyrell)
Also visit my homepage huntington beach hotels – Rolland –
Here is my homepage :: hiking trails in maine, Octavio,
Here is my homepage … hiking backpack baby (Beau)
Feel free to surf to my web-site … camping checklist for rv (Winfred)
Look into my homepage: camping food – Evie –
My blog camping gear near me (Marcela)
If some one needs expert view concerning blogging and site-building then i
suggest him/her to go to see this blog, Keep up the nice job.
Also visit my web blog: sr-organisation.org
my blog post – fishing knots for swivels (Estela)
Take a look at my blog post :: hunting hitler; Hilario,
Take a look at my web blog – hiking boots for men (Juliane)
Look at my web-site: camping gear walmart (Shirley)
Awesome issues here. I am very satisfied to look your article.
Thank you so much and I am having a look ahead to contact you.
Will you please drop me a mail?
Here is my web page – camping gear sale (Sidney)
my page – fishing report (Aracely)
My page; camping gear clearance
Feel free to visit my homepage; hiking backpack baby; Bertie,
Feel free to surf to my web page – hiking boots walmart, Kristi,
Here is my webpage – hunting hitler history
My blog: huntington bank routing number (Reva)
My homepage: huntington library (Bonnie)
my web site – hiking boots
Feel free to visit my webpage – huntington bank credit
card (Terrell)
Here is my web site; fishing kayak with motor (Brandi)
Also visit my weblog fishing report long island (Angelita)
Here is my weblog … fishing report md (Janette)
We’re a group of volunteers and opening a neew scheme in our community.
Your site provided us with valuable info to work on. You’ve
done a formidable job and our entire community will bbe thankful to
you.
Also visit myy web-site … forex trend reversal
Look into my blog – fishing boats – Evelyn –
My blog post … camping checklist food (Freeman)
Also visit my website hunting hitler 2015
Here is my site: hiking trails near me app
Here is my web-site :: huntington bank careers [Kristeen]
Remarkable! Its actually awesome piece of writing,
I have got much clear idea about from this paragraph.
Feel free to visit my blog :: hunting hitler tv
show (Ines)
Feel free to surf to my page :: camping gear clearance (Koby)
my blog post: huntington library
Hey I know this is off topic but I wwas wonderding if you knew of anny widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some timke and was hoping maybe you woulpd have some expesrience wiuth
something like this. Please let me know if you
runn into anything. I truly enjoy reading your blog and I look forward to your new updates.
Take a look at my blog post – cara delevingne age
Also visit my web blog fishing report nj
Also visit my blog: hunting hitler trailer (Damaris)
Here is my page … huntington bank app (Glenna)
my web-site :: hunting hitler history (Arletha)
Check out my blog post … camping gear; Bette,
Purchasing from individuals, especially if they have not uninstalled
the programs from their own systems, bypasses the legal chain of supply that
ensures producers receive their payment for the license.
Optimize these pages for SEO and employ redirects to take visitors to the appropriate zone or page of the site.
Rockstar Games stated previously that users who unwilling accepted the
hacked money gifts do not have to worry about being disciplined.
my homepage; http://Www.facebook.com/NewChaturbateTokenHack
Stop by my homepage: hiking boots for men (Ilana)
Feel free to surf to my site – fishing kayak with motor
my webpage – fishing boats with hucksters bargaining for
fish (Alonzo)
I every time used to studyy piece of writing in news
papers but noow as I am a user of internet therefore from
now I am using net for content, thanks to web.
My web blog how to burn fat at home without equipment
Also visit my website … hiking backpack baby (Corey)
Feel free to visit my web-site; camping gear sale – Tahlia,
Look at my weblog … huntington bank app
Review my blog post fishing kayak with motor (Shavonne)
My homepage – hiking trails near me app (Raquel)
my webpage camping recipes (Gertrude)
Also visit my homepage :: camping gear near me
Stop by my web site: fishing knots for swivels
I delight in, lead to Ӏ ɗіѕcονегeԁ еⲭactlу աҺaѡt Ⅰ աաɑѕ hɑνіng а ⅼⲟo foг.
Уߋս’νe endеⅾ mу fօᥙг ɗaу lоng hᥙnt!
Gߋd Ᏼlеsѕ ʏⲟᥙ mɑn. Ηɑνе a niϲе day.
ᗷуe
Ⲏеге iѕѕ mʏ Һоmераɡe: botanique Showflat
my homepage :: hunting hitler history channel (Lionel)
Here is my webpage – hiking backpack small
Feel free to visit my blog … camping gear clearance (Jamaal)
Look into my site hiking trails in nc (Chance)
Here is my weblog: fishing kayak walmart
my homepage – fishing kayak with motor (Blake)
Feel free to surf to my webpage: hiking boots walmart (Anya)
Also visit my page; hiking boots walmart (Lenard)
Why visitors still make use of to read news papers when in this technological world everything is existing on web?
My blog post fishing report long island
Fantastic blog, I’m going to spend more hours reading regarding this subject.
Also visit my web-site :: earthing mattress
Also visit my site … camping gear walmart (Nadia)
My weblog; hunting hitler tv show (Christena)
I just could not go away your site before suggesting that I actually loved
the standard information a person supply to your visitors?
Is gonna be again regularly in order to check out new
posts
Feel free to visit my site :: huntington library (Michelle)
Every weekend i used to ppay a quick visit this web site, because
i wish for enjoyment, as this this web page conations in fact fastidious funny stuff too.
My websiute :: Virgil
Thanks on your marvelous posting! I certainly enjoyed reading it, you might be a great
author. I will make certain to bookmark your blog and definitely
will come back from now on. I want to encourage that you continue your great writing,
have a nice holiday weekend!
my web blog; fishing report md, Lyle,
Feel free to surf to my webpage; fishing kayak walmart (Bradford)
my weblog; camping world locations (Margarette)
Here is my page – fishing knots for swivels (Grace)
Thank you for the good writeup. It in fact was a amusement
account it. Look advanced to more added agreeable from you!
However, how can we communicate?
my blog post :: Funny White Dog Dogs Picture
Also visit my blog post: camping gear near me (Mai)
my page camping gear
my web site … huntington bank credit card [Hwa]
my web-site … camping world rv sales, Bessie,
Feel free to visit my weblog: hunting hitler history channel
My weblog – camping gear (Gabrielle)
My blog :: camping checklist app [Cristine]
my homepage – camping checklist food (Brandy)
Also visit my web-site – fishing boats (Marisol)
My webpage: camping checklist app
Also visit my blog :: hiking trails near mechanicsburg pa (Tyrell)
Here is my web-site: fishing rod (Sandy)
It’s amazing to visit this web page and reading the views of all
mates concerning this article, while I am also zealous of
getting know-how.
Keep on working, great job!
Hello, Neat post. There is a problem together with your site in internet explorer, may test this?
IE still is the market leader and a huge component of people will pass over your great
writing because of this problem.
Hi everyone, it’s my first go to see at this web site,
and post is really fruitful for me, keep up posting these articles.
I could not refrain from commenting. Very well written!
Yes! Finally something about weather experienced wedding.
Hello, I think your site might be having browser compatibility issues.
When I look at your blog site in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other
then that, fantastic blog!
A motivating discussion is definitely worth comment.
I do think that you should write more about this issue, it might not be a
taboo matter but typically people don’t discuss
such topics. To the next! Many thanks!!
Acknowledging I had just thrown away an overall working day playing a game, I strike the delete button.
This will probably obvious practically all of the
board, and is pretty much a prerequisite for winning this level.
Midas – Player, which is better identified as King — the emblem and
name that exhibits up when the cellular app is started off — is indeed doing so,
according to a Tuesday report in the Wall Road
Journal.
Also visit my web-site: summoners war hack
But if you need a good reference on the matter of programming drums, take
a look at Ray Badness’ book entitled ‘Drum Programming – A Complete Guide
To Program And Think Like A Drummer. Those tracks were dark, thick,
funky; it felt as if you could cut through them literally.
Although some moves were gang rivalry related most were a way for teenagers
to get away from gang violence and dance instead.
Also visit my web blog; Booba Nero Nemesis
Hello just wanted to give you a quick heads up. The words in your article
seem to be running off the screen in Opera. I’m
not sure if this is a formatting issue or something to do with browser compatibility but I thought I’d post to let
you know. The layout look great though! Hope you get
the problem fixed soon. Kudos
I want to to thank you for this good read!! I certainly enjoyed every little bit of it.
I’ve got you book-marked to check out new stuff you post…
Also visit my webpage … crime scene cleanup
Official Michael Kors Bags Outlet Store Online SAVE UP 84% Free Shipping For You!
michael kors factory outlet
Hello everybody, here every person is sharing such experience,
so it’s fastidious to read this blog, and I used to pay a quick visit this webpage daily.
Thanks designed for sharing such a pleasant opinion, paragraph is pleasant,
thats why i have read it entirely
Throwing boobs at the problem is invariably the wrong
thing to do, but with the critical success of Bayonetta, it seems game players are still hankering for more titillation and some old-school Japanese gameplay.
The definitions of beautiful, attraction, and sexual constantly
change to serve the social order, and the connection between the three ideas is a recent invention. How you can modify your specific diet, to make sure that it truly is well prepared for your Back button sperm or maybe this Ful sperm.
Here is my web site; phim sex – http://www.allphimsex.com,
Also visit my page – fishing report nj – Ahmed
–
Feel free to visit my page – fishing boats for sale in california
My web site – hunting hitlers stolen treasures (Therese)
Feel free to visit my web page: huntington bank careers
my site; hiking trails, Gregory,
Feel free to surf to my blog fishing boats; Angelia,
Feel free to visit my web site :: camping world rv sales
great points altogether, you just received a new
reader. What could you recommend about your post that you simply made a few days ago?
Any certain?
Also visit my website Sweet Baby Couple Romantic Wallpapers For Your Mobile Cell Phone
Feel free to visit my web site; huntington bank app (Sterling)
I really like it when individuals get together and share ideas.
Great blog, keep it up!
Look into my website; camping checklist rei – Melisa –
My web page … camping checklist for baby (Jacquelyn)
Feel free to surf to my blog post – camping recipes – Juana –
Hey, I think your website might bbe having browser compatibility issues.
When I look at your log in Chrome, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, superb blog!
my homepage: watch online free – Kurt,
This piece of writing offers clear idea designed for the new visitors
of blogging, that in fact how to do blogging and site-building.
Oh my goodness! Awesome article dude! Thank
you, However I am having problems with your RSS. I don’t know the reason why
I am unable to join it. Is there anybody else having the same RSS issues?
Anyone that knows the answer can you kindly respond? Thanx!!
Woah! I’m really loving the template/theme of this site.
It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance” between superb usability and visual appeal.
I must say you have done a excellent job with this.
In addition, the blog loads super quick for
me on Safari. Exceptional Blog!
Does your site have a cntact page? I’m having a
tough tiime locating it but, I’d like to shoot yoou ann
e-mail. I’ve got some creative ideas for your blog
youu might be interested in hearing. Either way,
great site and I look forward to seeing it improve over
time. http://www.kool1440.com
Feel free to surf to my weblog camping checklist app (Ramon)
Hmm is anyone else having problems with the pictures on this blog loading?
I’m trying to find out if its a problem on my end or if it’s
the blog. Any responses would be greatly appreciated.
Take a look at my homepage … epic soccer training kit
my site: hunting hitler tv show (Zoe)
Thanks for one’s marvelous posting! I certainly enjoyed reading it, you
might be a great author. I will make certain to bookmark your blog and
will eventually come back very soon. I want
to encourage you to ultimately continue your great work, have
a nice afternoon!
Feel free to visit my web page :: camping gear
Young escorts are very submissive as they need
good care from the clients as most of them are new to the profession and needs special treatment and care from the clients.
For a start your basic avatar will look like a plastic
doll when nude and so if you want nipples and genitals you’ll
need to buy a new skin. Times and Y sperms Would be the figuring out take into account no matter if you have a baby any young man or maybe a woman.
Also visit my homepage: chaturbate cheats
my homepage – fishing boats with hucksters bargaining for fish
I’m not sure why but this site is loading incredibly slow for me.
Is anyone else having this issue or is it a issue on my end?
I’ll check back later and see if the problem still exists.
Here is my web page … fishing boats (Shaun)
Here is my web site … fishing kayak with motor – Tresa –
Also visit my website :: fishing report long island
my webpage; fishing knots for swivels (Douglas)
Here is my web page; hiking boots for men (Lyle)
Also visit my website – camping tents for rent (Jonathan)
I’m really enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more pleasant for me to come
here and visit more often. Did you hire out a designer to create your theme?
Outstanding work!
Also visit my web blog – huntington bank careers
Here is my web page … camping gear near me (Pansy)
Why viewers still use to rdad news papers whyen in this technological globe all is avaailable on net?
http://www.australianboarding.com
Marvelous, what a weblog it is! This weblog provides helpful facts to us, keep it
up. http://www.otavaloempresarial.com
Hello there, I discovered your blog by means of Google even as looking for a comparable topic,
your website came up, it appears great. I have bookmarked
it in my google bookmarks.
Hi there, simply became alert to your blog thru Google,
and found that it’s really informative. I am going to watch
out for brussels. I’ll appreciate in case you continue this in future.
Lots of folks will likely be benefited from your writing.
Cheers!
Also visit my website :: hiking trails in nc (Hugo)
Feel free to surf to my site … fishing rod
Feel free to surf to my homepage – camping world truck series
Here is my web site hiking near nyc (Angelita)
Also visit my web page: fishing report md – Connor –
Asking questions are inn fact nice thing if you are not understanding something fully, but this piece of
writing provides pleasant understanding yet.
Allso visit my web bloig :: best quotes to become successful (Scarlett)
Hello, i read your blog occasionally and i own a similar
one and i was just curious if you get a lot of spam remarks?
If so how do you protect against it, any plugin or anything you can recommend?
I get so much lately it’s driving me crazy so
any assistance is very much appreciated.
It’s really a nice and useful piece of info. I’m happy that you shared this useful info with us.
Please kewp us upp to date like this. Thanks for sharing.
Here is my homepage: burn fat and build muscle program (Evelyn)
you’re actually a good webmaster. The web site
loading velocity is incredible. It kind of feelks that
you’re doing any distinctive trick. Furthermore, The contents
are masterpiece. you’ve done a mqgnificent process on this matter!
Here is my website: the superior singing method
I got this website from my buddy whho told me about
this web page and now this time I am visiting this web
page aand reading very informative articles or reviews at
this place.
Feel frree to visit my web blog; where to buy phsromones (Floyd)
Feel free to visit my homepage – camping checklist app
My web page; camping gear walmart; Kathleen,
You are a very smart individual!
Here is my webpage; Jason Naughton Galway
Feel free to surf to my page hiking backpack baby; Leopoldo,
When someone writes an paragraph he/she retains the idea
of a user in his/her brain that how a user can be aware of
it. So that’s why this post is perfect. Thanks!
my blog post :: fishing report nj (Tammy)
Here is my blog … fishing rod (Elden)
farmakeio
Spyder jackets are also made with Thinsulate; an insulation technology used in clothing mostly on gloves and winter jackets.
In three months, while your nails grow, the medicine applied prevents the fungi from growing,
bringing back again the natural and balanced nail.
When you take the steps to get in the shape you want to be in,
be happy, thankful, and in love with the body that you were given.
Also visit my homepage: cheap giuseppe zanotti shoes
Hi, I believe your website could possibly be having browser compatibility issues.
When I take a look at your website in Safari, it looks fine however when opening
in IE, it’s got some overlapping issues. I simply wanted to provide you with a quick heads up!
Other than that, great website!
Feel free to surf to my blog: camping world locations
Here is my web page … fishing boats with hucksters
bargaining for fish [Lila]
Asking questions are actually pleasant thing if you are not understanding something
totally, except this piece of writing gives fastidious understanding yet.
Also visit my web blog: huntington bank careers (Josie)
What i don’t realize is in reality how you are
now not really a lot more neatly-preferred than you might be right now.
You’re very intelligent. You understand thus considerably in the case of this matter, produced me in my
view believe it from numerous numerous angles.
Its like men and women don’t seem to be interested until it’s something to accomplish with Lady gaga!
Your own stuffs nice. At all times take care of it up!
I’m extremely impressed with your writing skills and also with the layout
on your weblog. Is this a paid theme or did you customize it yourself?
Either way keep up the nice quality writing, it’s rare
to see a great blog like this one today.
Itts not my first time to go to see this website, i am
browsing this web page dailly andd obtain good facts from here daily.
Also visit my web page … download singing success for free
Post writing is also a excitement, iif you bee familiar with then you can write or else it is
complex to write. http://www.sidsnc.com
Every weekend i used to pay a visit this site, as i wish
for enjoyment, since this this web page conations in fact
good funny stuff too.
Do you have a spam problem on this website; I also am a blogger, and I was wanting to know your situation;
many of us have developed some nice procedures and we are
looking to swap methods with others, be sure to shoot me an email
if interested.
Have a fantastic first day on the stock market,” a swimming pool upkeep and repairman from Petaluma, Calif., wrote from a mobile device.
Hello mates, its impressive paragraph regarding cultureand completely defined, keep it up
all the time.
Hi there! This is kind of off topic but I need some help from an established blog.
Is itt very had to set up ypur own blog?
I’m not very techincfal but I can figure things out pretty quick.
I’mthinking about making myy own but I’m not sure where to begin. Do
you have any ppints or suggestions? Many thanks http://www.winappcommerce.com
Very good blog! Do you have any hints for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost
on everything. Would you propose starting with a free
platform like WordPress or go for a paid option? There are so many options out there that I’m completely overwhelmed ..
Any suggestions? Bless you!
Hi there friends, nice paragraph and good arguments commented at this place, I am
genuinely enjoying by these.
Hi! I could hage sweorn I’ve visited our blog before but after looking at a few of the articles I realized it’s new to me.
Regardless,I’m definitely happy I discovered it and I’ll
be book-marking it and checking back frequently!
Check out my web blog … Odds worth betting syndicate
A motivating discussion is definitely worth comment. There’s no doubt that that you need to
publish more about this topic, it may not be a taboo matter but generally folks don’t discuss
such topics. To the next! Many thanks!!
Hello to all, because I am genuinely eager of reading this web site’s post to be updated on a regular basis.
It includes fastidious stuff.
Feel free to surf to my web-site … female libido enhancer spray paint (Efrain)
Hi, i read your blog from time to time and i own a similar one
and i was just wondering if you get a lot of spam comments?
If so how do you reduce it, any plugin or anything you can recommend?
I get so much lately it’s driving me crazy so
any help is very much appreciated.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is
added I get three emails with the same comment. Is there any
way you can remove me from that service? Cheers!
Excellent beat ! I would like to apprentice while you amend your web site, how can i subscribe for a weblog site?
The account helped me a acceptable deal. I had been a little
bit familiar of this your broadcast offered bright
transparent concept
Hi everyone, it’s my first pay a visit at this web page, and article is
genuinely fruitful designed for me, keep up posting
such content.
If you wish for to grow your familiarity just keep visiting this web site and be updated with the hottest information posted here.
It’s an awesome post in support of all the internet visitors;
they will get bewnefit from it I am sure.
http://www.katiekoep.com
I’ve been browsing online more than 4 hours today, yet I never found any interesting article like yours.
It’s pretty worth enough for me. In my opinion, if all
web owners and bloggers made good content as you did, the internet
will be much more useful than ever before.
Thanks , I’ve just been searching for information about this subject
for a while and yours is the greatest I have found out so far.
However, what about the conclusion? Aree you sure about the supply?
http://www.financialhealthsolutions.net
With the help of this solution not only service providers can provide qualitative service to their users but subscribers can also avail required amount of bandwidth and
avoid wastage. This was the basis that Microsoft
and other companies used when the feature was first introduced.
The next time you watch a porn flick, take note of
the star.
I think the admin of this website is actually working hard in support
of his web site, since here every material is quality based
material.
New Arrival Jordan 11 Legend Blue
cheap jordans 11
Excellent website. Lots of useful info here. I’m sending it to
a few pals ans additionally sharing in delicious.
And obviously, thank you to your sweat!
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
My homepage … hiking boots walmart – Margart –
My homepage – hiking trails
Stop by my blog :: hiking trails near mechanicsburg pa (Tonia)
Feel free to visit my blog … hiking trails near me
app (Earle)
Here is my blog: camping world locations (Jacquelyn)
My website: camping gear walmart – Etta,
Hey just wanted to give you a quick heads up and let
you know a few of the images aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different web
browsers and both show the same results.
Thank you a lot for sharing this with all folks you really recognize what you are speaking approximately!
Bookmarked. Please additionally visit my site =).
We may have a link exchange agreement among us
Also visit my homepage hiking trails in colorado (Shaun)
Also visit my page :: hiking trails [Abby]
Feel free to visit my webpage; camping checklist rei, Vance,
Also visit my blog post … camping gear sale
Here is my blog huntington bank credit card (Ted)
Review my web page – hunting hitler tv show (Alva)
Have you ever thought about including a little bit more
than just your articles? I mean, what you say is fundamental and all.
However imagine if you added some great graphics or videos to give your posts
more, “pop”! Your content is excellent but with
pics and videos, this blog could undeniably be one of the most beneficial in its field.
Great blog!
Incredible points. Great arguments. Keep up the great effort.
Koray Büyükasar bir dizi vardı ORTAK OLARAK ŞEYLER
Feel free to visit my web page; koray buyukasar skandal
Feel free to visit my blog; hunting hitler imdb (Lasonya)
What’s up it’s me, I am also visiting this site regularly, this web page is actually good and the visitors are genuinely sharing good thoughts.
Also visit my website fishing boats for sale in iowa, Shavonne,
Here is my webpage :: fishing report
my weblog … hiking backpack reviews (Lawrence)
I just couldn’t leave your website before suggesting that I actually enjoyed
the standard info an individual supply on your guests?
Is going to be back frequently to investigate cross-check new posts
Also visit my web page … Crazy ATM
Also visit my web site … hiking trails in maine
(Lavern)
Also visit my webpage :: camping world truck series
Also visit my website; fishing kayak setup; Helena,
I was very happy to uncover this page. I need to to thank you for your time just for this wonderful read!!
I definitely loved every part of it and i also have you bookmarked to check out new things in your web site.
Also visit my weblog; crime scene cleanup
Yes! Finally someone writes about skin care tips.
my web site – fishing report ct (Carin)
My blog … hiking boots reviews
I’m pretty pleased to uncover this web site.
I want to to thank you for your time just for this wonderful read!!
I definitely appreciated every little bit of it and
i also have you saved to fav to look at new things on your
website.
This paragraph provides clear idea designed for the new visitors of blogging, that genuinely how to do running a blog.
Review my website … hiking boots (Jeanette)
Also visit my web blog: huntington beach news (Edgar)
my web-site hunting ground
If some one needs to be updated with latest technologies therefore he must be visit this web page and be up
to date every day.
Here is my web page … camping checklist rei, Belle,
My webpage – hiking trails (Chase)
It’s going to be end of mine day, except before ending
I am reading this great piece of writing to improve my experience.
I have learn some excellent stuff here. Certainly worth bookmarking for revisiting.
I surprise how a lot effort you place to make this
kind of wonderful informative site.
What’s Happening i am new to this, I stumbled upon this
I have discovered It absolutely useful and it has aided me out loads.
I am hoping to give a contribution & assist other customers
like its helped me. Good job.
For most up-to-date information you have to go to see world-wide-web and on world-wide-web I found this web page as a best website for newest updates.
you’re really a excellent webmaster. The website loading pace is amazing.
It seems that you are doing any distinctive trick. Also,
The contents are masterwork. you’ve done a great job
in this topic!
You are not a subject, but an object of glory, an object of a rare diamond that
are different from the rest of the other diamonds.
The AKO system allows all the useability of a normal internet connection but
with the added bonus of being a well monitored and secured connection. We are already becoming a rapid communication society.
Stop by my web-site; implant dentaire tarif
The common saying is ‘money cannot buy happiness’ and it is true.
Now it is change or die (meaning plant closure or lay-off.
As mentioned above, globalization is creating numerous opportunities for sharing knowledge, technology, social values, and behavioral
norms and promoting developments at different levels including individuals,
organizations, communities, and societies across different countries and cultures.
my page :: comment avoir les dents droites
It’s really a cool and useful piece of information. I’m glad that you simply shared this
helpful information with us. Please stay us up to date
like this. Thank you for sharing.
My future husband have actually been struggling with Hidradenitis Suppurativa (HS) for about 12 years.
What a material of un-ambiguity and preserveness of precious experience about unpredicted feelings.
My web-site Road Test Bmw 420D Xdrive M Sport Gran Coupe Automatic
Methods to remove the infection, protect the tooth, and avoid issues are the goals of treatment.
It wasn’t up until I was looking into the Paleo Diet that I discovered a book about HS by Tara Grant.
Dans le premieг caѕ, іl n’еѕt pɑѕ ρⲟѕѕіЬle de ϲοnsеіlⅼᥱг à ⅼ’éρоսⲭ գսі
n’еѕt ⲣaѕ ρгⲟргіétaігe ɗu Ƅiеn ԁе ѕе рοгter ϲߋ-ᥱmⲣrսnteuг
ɗе ѕоn cоnjⲟіnt ɑutοmοƅiⅼe il ne ⲣօսггaіt рaѕ contіnueг à bénéfiсіеr ⅾᥙ сⲟntгаt ɗe рrêt νіаǥег һуρߋtҺécаіге
puіѕգᥙе ⅼ’агtiсle L.314-1 ᥱⲭіge qᥙᥱ lе Ьіеn ҺүρоtҺéqᥙé aⲣρaгtіеnnе à
l’еmргuntᥱᥙr.
Ϝеel fгеe tо ѕuгf tߋ my Ьⅼⲟɡ …
pret senior
If you desire to obtain a good deal from this paragraph then you have to apply such strategies to your won blog.
Det trengs større studier som belyser effekt og (langtids)bivirkninger av TNF-α og andre immunsuppressiver ved hidradenitis suppurativa.
My web site; hidradenitis suppurativa treatment 2015; Tonja,
Deroofing: This surgical treatment might be an alternative for
clients who have unpleasant HS that consistently returns.
Here is my web page :: hidradenitis suppurativa cure review (Enrique)
Sartorius K, Lapins J, Emtestam L, Jemec GB.
When reporting treatment results in hidradenitis suppurativa,
suggestions form consistent result variables.
Take a look at my blog post fast hidradenitis suppurativa cure book
Considering that beginning the paleo diet plan over
a year ago I have not only lost 30 pounds easily and kept it off,
however I rarely get an HS breakout.
Here is my blog post; hidradenitis suppurativa treatment 2012 (Carina)
Barth JH. Cutaneous Virilism, Apocrine Glands and
Hidradenitis Suppurativa thesis.
my webpage: hidradenitis suppurativa early stages – Bethany,
In some individuals, prescription antibiotics seem to work for a
month or two, but then unexpectedly stop working.
My homepage – hidradenitis suppurativa pictures breast,
Georgina,
Everyone loves what you guys are usually
up too. This type of clever work and exposure! Keep up the good works guys I’ve incorporated you guys to
blogroll.
I don’t know whether it’s just me or if everybody else experiencing
issues with your website. It appears like
some of the text on your content are running off the
screen. Can someone else please comment and let me
know if this is happening to them too? This may be a issue with my internet
browser because I’ve had this happen before.
Thank you
My site … profit Shield
Hello! I know this is kid of off-topic but I needed to ask.
Does managing a well-established website such as yours take a
lot oof work? I am brand new tto running a blog however I do write in my journal every
day. I’d like to start a blog so I will be able to share my personal experience and views online.
Please let me know iff you hhave any ideas or tips for band new aspkring bloggers.
Thankyou!
my site: boss dr drum machine history
of course like your website but you need to check
the spelling on quite a few of your posts. Several of
them are rife with spelling issues and I to find it very
troublesome to tell the truth on the other hand I’ll definitely come
back again.
These are really great ideas in about blogging. You have touched some pleasant points here.
Any way keep up wrinting.
A fascinating discussion is worth comment. There’s no doubt that that
you ought to write more on this subject matter, it might not be
a taboo subject but usually people do not speak about such subjects.
To the next! Kind regards!!
Also visit my site; please click the following internet page (http://www.links4share.com/Home_Fundamentals:_How_To_Hone_A_Blade)
great points altogether, you simply received a emblem new reader.
What may you recommend in regards to your publish that you
made some days ago? Any certain?
Our principle of treatment including reconstructive strategies decreased the time of healthcare facility stay.
Check out my page … fast hidradenitis suppurativa cure book
(Tammy)
Thanks for the nice blog. It was extremely helpful for
me. Keep sharing such ideas in the future as well.
This was in fact what I was searching for, and I’m glad I got here!
Thanks for sharing the such information here.
Also visit my weblog: male extra pills; shanonholly887547.postbit.com,
I’m nott that much of a internet reader to bbe honest but your blogs really
nice, keep it up! I’ll go ahead and bookmark your website to come back later on.
All thee best
my web-site … Trubelleza Cream
Your content is good as well as informative in my personal opinion.
You have really done plenty of research on this topic.Thanks for sharing it.
Here is my blog; real male enhancement
Hi my friend! I wish to say that this post is amazing, nicely written along with include almost
all important information. I’d like to see more posts just like this.
Here is my blog post – male extra reviews
Varkarakis G, Daniels J, Coker K, Oswald T, Akdemir, Lineaweaver WC:
Treatment of axillary hidradenitis with transposition flaps:
a 6-year experience.
Here is my homepage hidradenitis suppurativa pictures stage 1 (Madeline)
Foor the reason thaat the admin of thijs website is working,
no question vwry shortly it will be renowned, duue to its feature contents.
My website :: skin care regimen for dry skin
After looking at a handful of the articles on your blog, I honestly like your technmique of writing
a blog. I book-marked it to my bookmark webpsge list
and will be checking back soon. Please visit my website as well and let
me know your opinion.
Also visit my bpog post :: Elmer
Early detection and treatment are always encouraged so that you can keep
your condition under control.
Stop by my page: hidradenitis suppurativa pictures stage 1
Anyhow, much like Hs/ai Professional says above, I truly suggest everyone to attempt Paleo
diet plan!
Look into my web site :: hidradenitis suppurativa pictures
Helpful information. Lucky me I found your web
site accidentally, and I’m surprised why this twist of fate didn’t happened in advance!
I bookmarked it.
Hidradenitis can not be treated but treatment
may ease signs, depending on the phase of the condition.
my homepage :: hidradenitis suppurativa remedies
2013 (Chang)
Long-term prescription antibiotics, weight-loss, antiandrogens and surgery are healing alternatives.
Visit my web site … hidradenitis suppurativa remedies 2013 (Elliot)
Figure 5. Bilateral Hidradenitis suppurativa (Hurley’s Staging
III) in the perianal, perineal and mons pubis revealing the left
side.
Have a look at my page: hidradenitis suppurativa natural treatment diet
We likewise have changed her diet to no processed foods she is
also consuming more fruits and vegatables and no sugar.
My blog … hidradenitis suppurativa early stages (Adolph)
Although hidradenitis suppurativa normally establishes after adolescence, it can still impact young adults while they are growing.
Also visit my web-site; hidradenitis suppurativa cure review, Donette,
Elwood ET, et al. Negative-pressure dressings in the treatment of hidradenitis suppurativa.
Here is my web site – hidradenitis suppurativa primal
diet (Levi)
More than 100 anatomy articles feature scientific images and diagrams of the body’s significant systems and organs.
Here is my blog; hidradenitis suppurativa treatment guidelines (Alva)
They will leave your windows squeaky clean, streak-free and aesthetically pleasing from both the interior and exterior.
While flipping through the channels on an early Saturday morning,
I came across an infomercial that caught my eye.
8 AMP motor, so you can rest easy knowing that it
has plenty of power to complete any project that you put it up
against.
Table I reveals the duration of HS, Hurley score
and treatment of the participants throughout the previous 2 years.
my page … hidradenitis suppurativa pictures breast (Roxanna)
Oh my goodness! Impressive article dude! Thank you so much,
However I am encountering problems with your RSS.
I don’t know the reason why I cannot subscribe to it.
Is there anybody else getting similar RSS issues? Anyone that
knows the solution will you kindly respond?
Thanks!!
Hello, i read your blog from time to time and i own a similar one and i was
just wondering if you get a lot of spam feedback? If so how do you prevent it, any plugin or anything
you can suggest? I get so much lately it’s driving me mad so any assistance is
very much appreciated.
Alternative treatment suggests that individuals use it rather of standard cancer treatment.
Also visit my site … hidradenitis suppurativa remedies 2013 (Minna)
Hidradenitis suppurativa generally starts soon after adolescence and continues
into adult life.
my website … fast hidradenitis suppurativa cure ebook pdf (Ezequiel)
It is not a MRSA infection, even though some people do discover relief from a flare-up through antibiotic treatment.
Take a look at my webpage … hidradenitis suppurativa
surgery armpit (Agnes)
I have actually had actually a condition called
Hidradenitis Suppurativa given that right after
adolescence.
Feel free to visit my web page; hidradenitis suppurativa diet recipes
(Elida)
More than 100 anatomy short articles showcase clinical images and diagrams of the body’s major systems and organs.
Have a look at my page; hidradenitis suppurativa cure 2012;
Royce,
I want to attempt a few of these treatment noted
but not sure which one to start initially.
my web-site hidradenitis suppurativa diet plan
You’ve really written a very good quality article here.
Thank you very much for sharing.
Look at my webpage … male enhancement review (Marylou)
Your style is unique in comparison to other people I’ve read stuff from.
Thanks for posting wheen you’ve got the opportunity, Guesss I will just book mark this page.
my web-site: Kathleen
Howdy would you mind letting me know which wweb host
you’re utilizing? I’ve loaded your blog in 3 different
browsers and I must say this blog loads a lot faster tthen most.
Can you suggest a good hosting provider at a reasonable
price? Thank you, I appreciate it!
My web blog – anti aging facial treatments (Josephine)
That’s why neither the paleo diet nor a dairy-free diet help thoroughly,
despite the fact that they do assist a lot.
Here is my page :: hidradenitis suppurativa cure 2012 (Eloy)
She wishes to have surgical treatment but I do not think it would assist and
the medical professionals are no aid.
my site: hidradenitis suppurativa cure review – Shay
–
Aw, this was a very nice post. Taking the time and actual
effort to make a good article… but what can I say… I put things off
a lot and never seem to get nearly anything done.
Prescription antibiotics such as the tetracyclines, sulfonamides, isoniazid (INH), sulfamethoxazole, trimethoprim, nitrofurantoin, and so
on
Also visit my web blog: hidradenitis suppurativa diet (Winifred)
In this crazy world some would commit criminal offenses just
so they might get the totally free surgery.
Here is my blog hidradenitis suppurativa cure fast (Jasper)
TNF-a levels are elevated in lesional and perilesional skin from clients with hidradenitis suppurativa.
Feel free to surf to my homepage :: hidradenitis
suppurativa primal diet (Rosalind)
The next thing you may find essential are coins, these will be used to also
build things and get distinct belongings you will need to move on in the game itself.
Closing in second place for today’s most popular free game is ‘Rear Cars
Driving: Need for Asphalt Racing’ a similar quality racing game.
It’s the i – Phone version of a once popular PC game and for
its latest version – the game developer brings all
the goodness and excitement of the original game – this time optimized for the small screen real estate of the i – Phone.
Also visit my homepage http://www.facebook.com/SmashyRoadWantedHack
I want to raise awareness about this condition and the fact that there IS an effective treatment.
my blog … hidradenitis suppurativa stages
Specifically if there is an infection of the surrounding skin, the physician commonly prescribes prescription antibiotics.
Here is my site hidradenitis suppurativa pictures (Zak)
Wonderful bea ! I would like to apprentice att the same tjme ass you amejd yoiur weeb site,
hhow could i subscriube for a blog web site?
Thee accoount helped mme a appropriate deal. I were tiny bit familiar
of this your broadcast provided shiny transparent idea
Here is my webpage :: Colleen
ALL mammal items have to be eliminated from your diet plan for the
remedy to work to the full.
Look into my website; hidradenitis suppurativa surgery – Rachel –
I’m not that much of a internet reader to be honest but
your sites really nice, keep it up! I’ll go ahead and bookmark your site to come back
in the future. All the best
Please let me know if you’re looking for a author for your weblog.
You have some really good posts and I believe I
would be a good asset. If you ever want to take some of the load off,
I’d really like to write some content for your blog in exchange for
a link back to mine. Please send me an e-mail if interested.
Regards!
Hi there colleagues, pleasant piece of writing and nice urging commented here, I am actually enjoying by these.
Beat Roshan down and get the Aegis will do
a big help to your success. The The Walking Dead No Man’s Land cheats plays a loop of lively tracks that builds up as encounters become intense.
For those who pay over the average price, you will unlock these
two The Walking Dead No Man’s Land cheats titles, on top of
the three titles and DLC pack that were added on October 22.
Here is my web-site: the walking dead no mans land hack
Hidradenitis suppurativa: This is a condition where there are multiple
abscesses that form under the armpits and
commonly in the groin location.
my blog post; hidradenitis suppurativa pictures stage
1 (Uta)
My family members always say that I am killing my time here at net, however I know I am getting know-how
every day by reading thes nice content.
Due to the fact that I want each and every one of you
to try six complete months with this diet, and I compose
entirely.
Feel free to visit my webpage hidradenitis suppurativa natural treatment diet (Amelie)
Weber-LaShore A, Huppert JS. Hidradenitis suppurativa in a pre-pubertal
female.
Also visit my weblog hidradenitis suppurativa cure review (Lauren)
Thank you forr any other informative site. The place else may just I am getting
that type off info written in such an ideal means?
I have a undertaking tht I’m simply now working on, and I’ve been on the look out for such info.
Also visit my homepage … student finance uk deadline 2012
Mild cases of hidradenitis suppurativa may be treated
with warm compresses and antibacterial soap washings.
Have a look at my blog post :: hidradenitis suppurativa
early stages – Florentina –
Early detection and treatment are always motivated so that you can keep your condition under control.
Also visit my weblog hidradenitis suppurativa treatment in india;
Alta,
Normally I do not learn post on blogs, but I wish to say that
this write-up very compelled me to check out and do
so! Your writing taste has been surprised me. Thank you, very great article.
We aren’t going to charge you something to use the hack and
we’ll try to hold it free in near future.
The challenges are not always the same or even similar in nature, so that the Minions Paradise Hack contains a ‘new’ element each time your
dragon gains a level. BR Perform which can be defined well said, the sales company said to editors just that their particular
the company offered my test software application, “Within the event you direct to get, I can debugging to obtain. Planting and growing a Tree of Wisdom is challenging, and if done blindly, it may be time consuming as well.
Feel free to visit my web page http://www.facebook.com/getminionshack
The truth is that this book is for anyone who has autoimmune disease, and everyone who understands someone with Hidradenitis supparativa.
My website … hidradenitis suppurativa treatment antibiotics (Foster)
Thank уߋu fοr ɑnother excellent post.
Wɦere else may anyone ɡеt tҺat ҝind οf іnformation in such
a perfect approach ߋf writing? ӏ’vе
a presentation subsequent ᴡeek, аnd Ⅰ’m at tҺе search fⲟr ѕuch information.
Article writing is also a excitement, if you be familiar with afterward you can write otherwise it is difficult to
write.
Hidradenitis suppurativa is a chronic, frequent, and painful disease
in which there is swelling in locations of the apocrine sweat glands.
Here is my web-site: hidradenitis suppurativa treatment adults, Lea,
Root canal surgery might also be advised to remove any infected root tissue
after the infection has diminished.
my website … hidradenitis suppurativa cure 2015 (Mark)
It is an extremely sound diet plan based in clean foods and those that do not irritate the body.
Feel free to visit my homepage – hidradenitis suppurativa surgery pictures
(Margarito)
Very golod write-up. I definitely love this website. Stick with it!
Have a loook at my weblog … best acne treatment under the skin pimples (Jerold)
I attempted everything to stop the spread and attempt of my HS:
prescription antibiotics, natural solutions,
diet changes, hormone treatment, and so on
My webpage: hidradenitis suppurativa special diet
If you have actually been offered prescription antibiotics and the
location does not enhance within a few days, return your physician.
Take a look at my weblog … hidradenitis suppurativa stage 2 (Kattie)
As an affiliate marketer, you don’t have to stress over on how to work from home because affiliate marketing is all
done through the internet. Today we’ll discuss ways and best business strategies that you can minimize the risk in starting your own home business so you can thrive and finally be your own boss.
8 AMP motor, so you can rest easy knowing that it has plenty of power to complete any project
that you put it up against.
The goal of this article is to evaluate the scientific presentation, diagnostic factors to consider
and treatment of the condition.
Also visit my blog post; fast hidradenitis suppurativa cure
book (Lorna)
In cases of individual scarred lesions or
more severe disease, medical options offer the best opportunities of cure.
My homepage hidradenitis suppurativa pictures stage 1 (Leoma)
Rehman N, Kannan RY, Hassan S, Hart NB: Thoracodorsal artery perforator (TAP) type I V-Y development
flap in axillary hidradenitis suppurativa.
Review my blog – hidradenitis suppurativa diet recipes (Les)
I love your blog.. very nice colors & theme. Did you design this website yourself or
did you hire someone to do it for you? Plz reply as I’m looking to design my own blog and would like to
find out where u got this from. thanks
Kishi K, Nakajima H, Imanishi N: Restoration of skin defects after resection of serious gluteal hidradenitis suppurativa with fasciocutaneous flaps.
my weblog hidradenitis suppurativa surgery youtube (Jeannine)
Elwood ET, et al. Negative-pressure dressings in the treatment of hidradenitis suppurativa.
Also visit my blog post; hidradenitis suppurativa treatments (Chana)
This technique is called an elimination diet” in which foods are eliminated from the diet plan and after that included back into determine if they are problematic.
Have a look at my website :: hidradenitis suppurativa early stages (Harriet)
Fardet L, Dupuy A, Kerob D, et al. Infliximab for extreme hidradenitis suppurativa:
transient medical effectiveness in 7 consecutive clients.
my blog – hidradenitis suppurativa treatment in india (Russ)
Kishi K, Nakajima H, Imanishi N: Restoration of skin problems after
resection of severe gluteal hidradenitis suppurativa with fasciocutaneous flaps.
My web-site :: hidradenitis suppurativa surgery youtube – Kay,
What’s up, I desire to subscribe for this weblog to obtain latest updates, so
where can i do it please assist.
Il fatto che il Xtrasize si riesce a trovare al il più grande
incarico della classifica tra i componenti per il allungamento del pene non sorprende
nessuno.
Figure 6. Bilateral Hidradenitis suppurativa (Hurley’s Staging III) in the perianal, perineal and mons pubis revealing the best side.
My webpage – hidradenitis suppurativa treatment at home
Hidradenitis suppurativa, or Verneuil’s condition, is rather typical, particularly in ladies,
but is frequently unrecognized.
Feel free to visit my webpage … hidradenitis suppurativa pictures after surgery (Melodee)
This is the perfect website ffor anybody
who hopes to find out about this topic. You realize so much its almost tough to argue with you (not
that I actually will need to…HaHa). You certainly put a fresh spiin oon a topic
that has been discussed for a long time. Wnderful stuff, just great!
Here is my weblog – bonus bagging equipment; worldtimeinc.net,
Scheinfeld N; Hidradenitis suppurativa: A practical testimonial of possible medical treatments based on over 350 hidradenitis clients.
Also visit my blog post … hidradenitis suppurativa cures; Natalie,
To learn more about exactly what this condition resembles, go to Hidradenitis suppurativa: Symptoms.
Take a look at my page – hidradenitis suppurativa cure zone (Dwight)
It’s iin reality a great and helpful piece of information. I
am happy that you shred this useful info with us. Please stay uss
informed like this. Thank you for sharing.
my blokg post … Purejuvenate Cream Anti-Aging
Hi there, I wish for to subscribe for this website to get newest updates, therefore where can i do it please help.
This is most appropriate for grade 1 hidradenitis suppurativa, and a course of antibiotic tablets would generally be offered later on.
my blog: hidradenitis suppurativa treatment uk; Gilbert,
Good way of explaining, and nice piece of writing to get data concerning
my presentation focus, which i am going to deliver in university.
Hidradenitis suppurativa is a chronic, persistent,
and painful disease where there is inflammation in areas of the apocrine gland.
My web site – hidradenitis suppurativa treatment up to date
(Allen)
Il numero di medici che riconosce la validità e l’efficacia degli esercizi
per allungare il pene è in costante aumento.
What’s up to all, the contents present at tis website are actually awesome for people
knowledge, well, keep up the nice work fellows.
Here is my blog post – dermabreastlift.Org
Fantastic website you have here but I was curious about if you knew of
any message boards that cover the same topics talked about here?
I’d really love to be a part of online community where I can get feed-back from other knowledgeable people that share the same interest.
If you have any suggestions, please let me know. Thanks!
It’s appropriate time to make some plans for the future and it’s time to be
happy. I’ve read this post and if I could I want to suggest you few
interesting things or suggestions. Maybe you could write next articles referring
to this article. I desire to read more things about it!
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get
four e-mails with the same comment. Is there any way
you can remove me from that service? Cheers!
My blog – Our Husky Red Wolf Mix Pics
Hello! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but
I’m not seeing very good results. If you know of any please share.
Many thanks!
Our Hack device uses an subtle algorithm which retains it steady even if there are thousand’s of gamers
utilizing the hack at a time.
The last waistline training book I reviewed
is not offered (most likely because its writer had no civil liberties to the images it used), so presently the only various other
actual waist training publication offered is Romantasy’s price-prohibitive $50 quick
guide.
my weblog; владпенобетон.xn--p1ai
I have been browsing online greater than three hours nowadays,
but I by no means discovered any attention-grabbing article
like yours. It’s pretty price sufficient for me.
In my opinion, if all webmasters and bloggers made good
content as you probably did, the net will probably be a lot more
helpful than ever before.
You could definitely see your skills in the article you write.
The world hopes for even more passionate writers like you who aren’t afraid to say how they believe.
Always go after your heart.
Here is my page Bmw Caferacer
Thank you a lot for sharing this with all of us you really know what you are speaking approximately!
Bookmarked. Please additionally visit my web site =). We can have a hyperlink exchange
arrangement between us
You really make it seem so easy with your presentation but
I find this topic to be really something that I think I
would never understand. It seems too complicated and extremely broad for
me. I’m looking forward for your next post, I’ll try to get the hang of it!|
Also visit my web page :: trucos gta san andreas
I’m actually glad to find this website on bing, just what I was
trying to find. Saved to bookmarks.
My web blog Phen375 Consumer Reviews, Candelaria,
I hope you’ll take pleasure in this clash of clans mod apk august 2015 without cost Gems, Gold And Elixir you might be going
through any drawback then just remark it beneath !!
Asking questions are genuinely nice thing if you are not understanding something entirely, however this post presents good
understanding even.
my website; hair no more advanced hair inhibitor soothing gel – http://www.bienal-siart.com,
You would actually eat about 4-6 smaller meals during the day.
I want to help you because I have been there before.
This should include work schedule, appointments, and any other commitments.
Feel free to surf to my page: ménopause et prise de poids
Hello, after reading this amazing piece of writing i am too
happy to share my know-how here with friends.
Heу Thᥱre. I foսnd ʏߋսr ƅⅼоǥ uѕing
mѕn. Ƭɦіѕ iѕ ɑn еxtremеⅼy ᴡeⅼ ԝгіttеn ɑгticⅼᥱ.
I’ll maқᥱ ѕuге tߋ bοoҝmɑгҝ
іt аnd rеtuгn tⲟ геad mοrᥱ оff үоᥙг սѕеfᥙⅼ infⲟгmatіߋn. Ꭲɦanks fог tһe ⲣⲟst.
І ᴡіlⅼ ⅾеfіnitеⅼу ϲomеЬaϲκ.
Ⲏегᥱ iіѕ mʏ աеƅⲣagе
– herbal drive testosterone
Hi I am so glad I found your site, I really found you by
accident, while I was browsing on Yahoo for something else, Anyhow I am here now and would just like to say thanks a lot for a fantastic post and a all round interesting blog
(I also love the theme/design), I don’t have time to read
it all at the moment but I have bookmarked it and also added your RSS feeds, so when I have time
I will be back to read a lot more, Please do keep up the superb work.
This web site really has all of the info I needed about this subject and didn’t know who to ask.
I visit each day some web sites and websites to read articles, but this web
site provides feature based writing.
Verry nice post. I simply stumbled upon your weblog and wished to
say that I have really loved surfing around your weblog posts.
In any case I’ll be subscribing to your rss feed and I’m hoping you write once more very soon!
my homepage topical skin treatment for dogs
If you wish for to grow your experience only keep visiting this web page and be updated
with the most recent news update posted here.
Pretty section of content. I just stumbled upon your blog and in accession capital to assert that I acquire in fact enjoyed account
your blog posts. Anyway I’ll be subscribing to your
augment and even I achievement you access consistently fast.
Normally I don’t read post on blogs, but I would like to
say that this write-up very forced me to take a look at and do so!
Your writing taste has been surprised me. Thanks, very
nice post.
Also visit my web blog – Cute Baby Love Couple Wallpaper Cute Baby Love Couple
There is absolutely nothing essentially wrong with wearing midsection training bodices, as long as it is not too strict.
My web-site Maryanne
Nice blog here! Also your site quite a bit up very fast!
What web host are you the use of? Can I am getting your associate hyperlink in your host?
I wish my web site loaded up as fast as yours lol
It’s hard to find knowledgeable people in this particular subject,
but you sound like you know what you’re talking about!
Thanks
Here is my homepage: fredrikstadak.no [Rebecca]
great submit, very informative. I ponder why the other experts of this sector
don’t notice this. You must continue your writing. I’m sure, you’ve a great readers’ base already!
Feel free to surf to my web blog; Bmw 8 Series 840ci Sport 1998 1998 For Sale Privately In
No matter if some one searches for his vital thing, thus he/she needs to be available that
in detail, thus that thing is maintained over
here.
Very nice post. I just stumbled upon your weblog and wanted to say that I have truly enjoyed browsing your blog posts.
In any case I’ll be subscribing to your rss feed and I hope you write again very soon!
Ancient U . s ., Leather western, jacket, cowboy buckskin jacket, american coat, homemade coat.
Qսaⅼіty aгtісlеѕ οг гeνiеԝѕ іs tҺe кеy to Ƅе a fоϲuѕ fߋг tɦе
νieաегѕ tο νіѕit tҺе աеЬѕіtе, thаt’ѕ
ѡҺаt tɦіѕ աеb раցe іѕ ρrօvіԀіng.
Mу ɦοmеρɑɡе; Authentic Love Spells That Work Immediately
Why viewers still make use of to read news papers when in this technological world everything is accessible on net?
Very goodd info. Lucky mme I discovered your website by accident (stumbleupon).
I have saved as a favorite for later!
my blog post – neosize xl guatemala
Your means of explaining all in this piece of writing is really fastidious, every one
be able to simply know it, Thanks a lot.
Howdy! This is kind of off topic but I need
some advice from an established blog. Is it very hard to set
up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m
not sure where to start. Do you have any tips or suggestions?
Cheers
Pretty section of content. I just stumbled upon your site and in accession capital to assert thatt I get in fact enjoyed
account your blog posts. Anyway I will be subscribing to your augment and even I achievement youu access consistently rapidly.
Check outt my web pazge :: playworshipguitar.com
At present, the liver cancer treatment depends on the disease stage,
patients with residual liver function and systemic conditions.
The liver helps break down bilirubin so that it can be removed by the body in the
stool. As hepatitis C is a viral infection which produces damage of the
liver tissues, this catalyses regeneration of nodules that causes cirrhosis.
Review my web page :: homeopathy treatment for hepatitis C
I will try to explain all of the features of this hack and sum up everything you can do with
it. That’s the reason this Wii bunch is definitely a tempting alternative.
Just don’t tell her it’s from the guys who made Grand Theft Auto.
My web site; bitcoin Game Hack
Hi there! Do you know if they make any plugins to assist with Search
Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very
good gains. If you know of any please share. Cheers!
By using the Clash of Clans limitless gems cheat, you may all
the time defend your village utilizing shields.
Hi! This post could not be written any better! Reading this post reminds me of my
old room mate! He always kept chatting about this.
I will forward this article to him. Pretty sure he will have a good read.
Many thanks for sharing!
Wow, this post is good, my younger sister is analyzing these kinds of
things, thus I am going to tell her.
I like what you guys tesnd to be up too. Such clever work and coverage!
Keep up the amazing works guys I’ve included you guys to blogroll.
Feel free to sur to my blog post … phyto350 customer reviews
Usually I do not learn post on blogs, but
I would like to say that this write-up very pressured me to
try and do so! Your writing taste has been amazed me.
Thank you, quite great article.
I’m not sure why but this blog is loading extremely slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem still exists.
Wheelman – The aim of the Minions Paradise Hack is a cross between a Grand Theft Auto and Need for Speed,
with a mixture of shooting and foot sections of reckless driving.
BR Perform which can be defined well said, the sales company
said to editors just that their particular the company offered my test software application, “Within the event you direct to get, I can debugging to obtain. or you will have to spend 30 minutes playing “Bejeweled Blitz” or “Pet Rescue.
Feel free to visit my blog: game Hacker Download 2015
I pay a visit day-to-day some blogs and websites to read content, but this weblog provides feature
based articles.
Article writing is also a excitement, if you
be familiar with after that you can write orr else it is complicated to write.
my web blog; neuology Pictures
I always emailed this webpage post page to all my
associates, because if like to read it after that my friends
will too.
It’s very easy to find out any matter on web as compared to books, as I
found this paragraph at this site.
It’s going to be end of mine day, except before finish I
am reading this wonderful article to improve my experience.
Thanks for another fantastic article. Where
else could anyone get that kind of info in such a
perfect manner of writing? I have a presentation subsequent week,
and I’m on the look for such information.
Fruit has too much sugar to help you burn fat effectively.
This means indulging in a snack every once in a while.
Self image is an important component in a weight loss journey though, so this step should never
be overlooked.
My site: comment maigrir des bras
I Corpi Сavernoѕi ѕоno і dսe ѕеttοгі Ԁі tеѕѕutο cҺе ѕі tгονano l’uno
aϲcanto aⅼⅼ’altгο nelⅼа ѕоmmità Ԁеⅼ ρеne.
Ӎу ѡᥱb site …
Allungamento Del Pene
We absolutely love your blog and find the majority of your post’s to be just what I’m
looking for. Does one offer guest writers to write content available for
you? I wouldn’t mind producing a post or elaborating on a number
of the subjects you write regarding here. Again, awesome website!
Here is my site; Read This method (http://www.inro-reborn.co.in)
Ibelieve this is among the so much significant info for me.
And i am satisfied studying your article.
But want to statement on some general issues, The website taste
is perfect, the articles is actually excellent : D. Good activity, cheers
Take a look at my blog;skin derma prro extra strength –
mundoverde.org.br –
Excellent weblog here! Additionally your site loads up fast!
What web host are you the use of? Can I get your affiliate
hyperlink for your host? I want my site loaded up as fast as yours lol
Hi there colleagues, how is everything, and what you wish
for to say regarding this piece of writing, in my view its in fact remarkable
for me.
This is really interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your magnificent post.
Also, I have shared your website in my social networks!
My web page: simply click the next website, http://www.ix-global.com,
This is a topic that’s close to my heart… Thank you!
Where are your contact details though?
Fruit has too much sugar to help you burn fat effectively.
Vitamin B6 is important for dieters for its role as a coenzyme involved in the metabolism,
of carbohydrates, fats and proteins. Forums are also a great place to seek and give advice.
my web-site: comment faire pour maigrir
I am curious to find out what blo platform you’re working
with? I’m having ssome smawll security issues with my latest blog and I’d like to fibd something more
risk-free. Do you have any solutions?
Here is my homepage :: Celebrity Body Parts
I’ve been browsing online more than 3 hours today, but I by no means found any interesting article like yours.
It’s beautiful worth sufficient for me. In my view, if all
web owners and bloggers made good content as you probably did, the net might be a lot more helpful than ever before.
I’ve been surfing online more than three hours today,
yet I never found any interesting article like yours. It is pretty
worth enough for me. Personally, if all webmasters and bloggers made good content as you did, the web will be much more
useful than ever before.|
I couldn’t refrain from commenting. Exceptionally well written!|
I’ll immediately snatch your rss as I can’t to find your
email subscription hyperlink or e-newsletter service.
Do you’ve any? Please permit me realize so that I may subscribe.
Thanks.|
It’s the best time to make some plans for the future and it’s time to be happy.
I’ve read this post and if I could I desire to suggest you some interesting things or suggestions.
Maybe you could write next articles referring to
this article. I wish to read even more things about it!|
It’s appropriate time to make some plans for the longer term and
it’s time to be happy. I have read this submit and if I may I want to suggest you few interesting things
or suggestions. Perhaps you can write subsequent articles referring to this article.
I desire to learn even more issues about it!|
I have been surfing online more than 3 hours these days, yet I never found any interesting article like yours.
It is lovely worth sufficient for me. In my opinion, if all web owners and bloggers made
excellent content material as you probably did, the
net shall be much more useful than ever before.|
Ahaa, its good conversation concerning this piece of writing at this place at this webpage, I
have read all that, so now me also commenting at this place.|
I am sure this piece of writing has touched all the internet users, its
really really fastidious post on building up new blog.|
Wow, this post is pleasant, my sister is analyzing
such things, therefore I am going to tell her.|
Saved as a favorite, I love your site!|
Way cool! Some very valid points! I appreciate you penning this post and also the rest of the website is very good.|
Hi, I do believe this is a great blog. I stumbledupon it 😉 I will come back once again since I book marked it.
Money and freedom is the greatest way to change, may you
be rich and continue to help other people.|
Woah! I’m really digging the template/theme of this website.
It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance”
between superb usability and visual appearance. I must say you have done a awesome job
with this. Also, the blog loads very quick for me on Internet
explorer. Outstanding Blog!|
These are actually fantastic ideas in concerning blogging.
You have touched some nice factors here. Any way keep up wrinting.|
I love what you guys tend to be up too. Such clever work and coverage!
Keep up the terrific works guys I’ve you guys to blogroll.|
Howdy! Someone in my Myspace group shared this website
with us so I came to give it a look. I’m definitely enjoying the information. I’m book-marking and will be
tweeting this to my followers! Fantastic blog and fantastic
style and design.|
I really like what you guys are up too. This kind
of clever work and reporting! Keep up the very
good works guys I’ve added you guys to our blogroll.|
Hi there would you mind sharing which blog platform you’re using?
I’m looking to start my own blog in the near future
but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m
looking for something completely unique.
P.S Sorry for being off-topic but I had to ask!|
Howdy would you mind letting me know which web host you’re
utilizing? I’ve loaded your blog in 3 different internet browsers and I must say this blog
loads a lot faster then most. Can you recommend a good internet hosting
provider at a reasonable price? Cheers, I appreciate it!|
I really like it when folks get together and share ideas.
Great site, stick with it!|
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how could we communicate?|
Hi there just wanted to give you a quick heads up. The words in your post seem to be running off the screen in Internet explorer.
I’m not sure if this is a format issue or something to do with internet browser compatibility
but I thought I’d post to let you know. The design look great
though! Hope you get the problem solved soon. Kudos|
This is a topic that’s close to my heart… Cheers! Where
are your contact details though?|
It’s very effortless to find out any topic on web as compared to textbooks, as
I found this paragraph at this site.|
Does your website have a contact page? I’m having trouble locating it but,
I’d like to shoot you an email. I’ve got some recommendations for your
blog you might be interested in hearing. Either way, great blog and I look forward to seeing it expand over time.|
Hey there! I’ve been following your weblog for a long
time now and finally got the bravery to go ahead and give you a shout out
from Huffman Texas! Just wanted to tell you keep up the excellent job!|
Greetings from Colorado! I’m bored at work so I decided to check
out your site on my iphone during lunch break. I love the information you present
here and can’t wait to take a look when I get home. I’m surprised at how
quick your blog loaded on my mobile .. I’m not even using WIFI,
just 3G .. Anyways, excellent site!|
Its like you read my thoughts! You seem to grasp so much approximately this, such as you wrote the guide in it or something.
I believe that you could do with a few % to drive the message house a little
bit, but instead of that, that is fantastic blog. An excellent read.
I will definitely be back.|
I visited various websites except the audio quality for audio songs current at this website is truly fabulous.|
Hello, i read your blog occasionally and i
own a similar one and i was just wondering if you get a lot of
spam comments? If so how do you reduce it, any plugin or anything
you can advise? I get so much lately it’s driving me mad so any help is very much appreciated.|
Greetings! Very useful advice in this particular post!
It is the little changes that make the most significant changes.
Many thanks for sharing!|
I seriously love your website.. Excellent colors & theme.
Did you make this web site yourself? Please reply back
as I’m trying to create my very own blog and
would like to know where you got this from or just what the theme is called.
Many thanks!|
Hi there! This article couldn’t be written any better!
Reading through this article reminds me of my previous roommate!
He always kept preaching about this. I most certainly will forward this post to
him. Fairly certain he will have a great read. Thank
you for sharing!|
Incredible! This blog looks exactly like my old one!
It’s on a totally different topic but it has pretty much the
same page layout and design. Excellent choice of colors!|
There’s certainly a lot to know about this issue. I like all the points you have made.|
You made some decent points there. I checked on the web to find out more about the issue and found most individuals
will go along with your views on this web site.|
What’s up, I log on to your new stuff regularly. Your humoristic style is awesome, keep
it up!|
I just could not depart your web site before suggesting that I extremely enjoyed the usual info an individual provide on your guests?
Is going to be back ceaselessly in order to investigate cross-check new posts|
I want to to thank you for this great read!! I definitely loved every bit of it.
I have you bookmarked to look at new things you post…|
Hi, just wanted to tell you, I enjoyed this post. It was helpful.
Keep on posting!|
I drop a comment whenever I like a article on a website or if I have something to add to the conversation. It’s a result of
the sincerness displayed in the article I read. And on this post JavaScript Exercise – Social Software.
I was moved enough to drop a comment 😛 I do have a couple of questions
for you if it’s allright. Is it only me or do some of the comments appear like they are written by brain dead visitors?
😛 And, if you are writing on other social sites, I would like
to follow you. Would you make a list all of your public pages like your Facebook page, twitter feed,
or linkedin profile?|
Hi there, I enjoy reading all of your post.
I like to write a little comment to support you.|
I always spent my half an hour to read this weblog’s
content daily along with a mug of coffee.|
I for all time emailed this web site post page to all my friends,
because if like to read it next my friends will too.|
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a number of websites for about a year and am worried about switching to another platform.
I have heard good things about blogengine.net. Is there a
way I can import all my wordpress content into it?
Any kind of help would be really appreciated!|
Hi! I could have sworn I’ve been to this blog
before but after looking at some of the posts I realized it’s new to me.
Nonetheless, I’m certainly delighted I came across it and I’ll be bookmarking it and checking back often!|
Great article! This is the type of information that are supposed to be shared around the net.
Shame on the seek engines for now not positioning this post
upper! Come on over and talk over with my website .
Thanks =)|
Heya i am for the first time here. I found this board and I find It really useful & it helped me out
a lot. I hope to give something back and aid others like you helped me.|
Hello, I think your blog may be having browser compatibility
issues. When I take a look at your website in Safari,
it looks fine however, when opening in IE, it has some overlapping issues.
I simply wanted to provide you with a quick heads up! Besides
that, fantastic website!|
A person necessarily lend a hand to make critically articles
I’d state. That is the very first time I frequented your website page and thus far?
I amazed with the research you made to create this actual
post amazing. Magnificent activity!|
Heya i am for the first time here. I came across this board and I find It really
useful & it helped me out much. I’m hoping to offer one thing back
and aid others such as you helped me.|
Hey there! I simply want to give you a huge thumbs
up for the excellent info you’ve got right here on this post.
I will be coming back to your blog for more soon.|
I all the time used to read article in news papers but now as
I am a user of web therefore from now I am using net for articles or
reviews, thanks to web.|
Your method of describing all in this piece of writing is genuinely nice, every one be able to
effortlessly be aware of it, Thanks a lot.|
Hi there, I discovered your site by the use of Google even as looking for
a similar topic, your website came up, it seems to be great.
I have bookmarked it in my google bookmarks.
Hello there, just became aware of your blog through Google, and found that
it’s truly informative. I am gonna be careful for brussels.
I will appreciate for those who proceed this in future.
Lots of other people shall be benefited from your writing.
Cheers!|
I’m curious to find out what blog system you have been working with?
I’m having some minor security problems with my latest website
and I would like to find something more safeguarded.
Do you have any suggestions?|
I am extremely impressed with your writing skills
and also with the layout on your blog. Is this a paid theme or
did you modify it yourself? Anyway keep up the nice quality writing, it’s rare to see a great blog like this one today.|
I am really inspired with your writing abilities as smartly as with the layout in your blog.
Is this a paid theme or did you customize it your self? Anyway stay up
the excellent high quality writing, it’s rare to peer a great blog like this one these days..|
Hi, Neat post. There’s an issue along with your website in web explorer, might check this?
IE nonetheless is the marketplace leader and a big section of people will pass over your magnificent writing
due to this problem.|
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for wonderful information I was looking for this info for my mission.|
Hello, i think that i saw you visited my blog so i came
to “return the favor”.I’m attempting to find things to enhance my site!I suppose its ok to use a few of your \
Good post. I earn something new aand challenging on sites I stumbleupon on a daily basis.
It will always be useful to read through articles from otber writers and
practice something from their sites.
Stop by my web blog … Kandi
Hey there! I’ve been following your site for a while now annd finally got
the courage to ggo ahead and give you a shoout out freom Humble Tx!
Just wanted to mention keep up the fantastic work!
My website :: learn guitaar chords online (Huey)
Thank yoᥙ foг thе ցооԀ ԝгіteսρ.
Ⅰt actᥙalⅼʏ աɑs ɑ amᥙsеmеnt ассߋunt it.
Ԍⅼancе сomⲣⅼᥱx tߋ mогe aⅾԁеⅾ aǥгееаЬlе fгіm
үоu! ᗷy thе ѡɑʏ, ɦоᴡ cοսⅼɗ աe қеер іn tоսсһ?
Rеvіeᴡ mʏ ѕіtе
leptin resistance doterra diffuser
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of
the expenses. But he’s tryiong none the less. I’ve been using Movable-type on numerous websites for about a year and am
concerned about switching to another platform.
I have heard very good things about blogengine.net. Is there a way
I can import all my wordpress posts into it? Any kind of help would be really appreciated!
Very good post! We will be linking to this great post on our
site. Keep up the good writing.
Aw, this was an incredibly nice post. Finding the time and actual effort to generate a very good article… but
what can I say… I hesitate a lot and never seem to get nearly anything done.
What’s Taking place i am new to this, I stumbled
upon this I have found It absolutely helpful and it has aided me
out loads. I am hoping to contribute & help different customers like its
helped me. Great job.
Good way of explaining, and fastidious piece of writing
to get data about my presentation subject matter, which i am going to present in institution of higher education.
Also visit my web page – fat diminisher system review
There’s definately a great deal to learn about
thgis topic. I love all the points you made.
Also visit my page :: playworshipguitar.com (http://www.educationlinks.com.bh)
Hey! This is my 1st comment here so I just wanted to give a quick
shout out and tell you I genuinely enjoy reading through your
articles. Can you suggest any other blogs/websites/forums that go over the same topics?
Thanks!
Why visitors still make use of to read news papers when in this technological globe
everything is available on web?
We stumbled over here from a different web page and thought I
might check things out. I like what I see so now i’m following you.
Look forward to looking over your web page for a second time.
What i do not understood is actually how you are not actually
a lot more smartly-preferred than you may be right now. You’re so
intelligent. You know therefore significantly relating to this matter, produced me personally consider it from
so many varied angles. Its like men and women don’t seem to be fascinated unless it’s one thing to do with Lady gaga!
Your personal stuffs great. At all times handle it up!
Can I just say what a comfort to find someone who really knows what they are talking about over the internet.
You definitely realize how to bring a problem to light and make it important.
More people have to check this out and understand this side of your story.
I was surprised you aren’t more popular because you definitely have
the gift.
My web page – hack someones snapchat
Many gamers demand for Clash of Clans hack with none examine, owing to the very
fact it results in hyperlinks and pointless pages.
I’ve been surfing online more than 3 hours today, yet I never found any
interesting article like yours. It is pretty worth
enough for me. In my opinion, if all website owners and bloggers made good content as
you did, the web will be a lot more useful than ever before.
Here is my homepage :: Millionaire Shield
After study a few of the blogs on your website now, and I truly like your way of
writing a blog. I bookmarked it to my bookmark website list and will be
checking back soon. Pls check out my web site as well and tell me what you think.
Check out my blog post; brydgeair keyboards
I know this if off toic but I’m looking into starting my own weblog annd was wondering
whazt alll is needed too get set up? I’m assuming having
a blog like yours would cost a pretty penny?I’m not very internet smart so I’m not 100% sure.
Anyy tips or advice would be greatly appreciated.
Kudos
Visit my page: Jacquelyn
Great site. Your blogs are very interesting and I’ll tell my friends.
Also visit my site … ipad keyboards [http://kazukomilam10196.postbit.com/]
Heya i’m for the first time here. I found this board and I
find It really useful & it helped me out
a lot. I hope to give something back and help others like you aided me.
Wow, incredible blog layout! Hoow long have you been blogging for?
you make blogging look easy. The overall ook of your website is great, as
well as the content!
Feel free to visit myy site … dietary supplement infustry growth – Keesha –
Somebody essentially lend a hand to make seriously posts I’d
state. That is the first time I frequented your website page and to this point?
I surprised with the research you made to make this particular publish incredible.
Great activity!
With the invention of wireless broadband, netbooks can make it easy to access Internet
even in remote places. This will cost you more than buying
a new one but you’ll have the advantage of being able to rank in the search engine more quickly.
Apart from that the search engine giant, Google has rolled out
a strategy where mobile-friendly websites are ranked higher in the Search Engine Rank Page (SERP).
Great article.
My blog post :: Binary Interceptor
You are so awesome! I do noot suppose I hqve read
through something like ths before. So nice to find somebody with a few original thoujghts on this issue.
Seriously.. thank you for starting this up. This website is
one thing that is required on the internet, someone with a bit of originality!
Look at my web site Rev Test Side Effects
I am curious to find out what blog system you happen to be utilizing?
I’m having some minor security issues with my latest site and I would like to find something more
safe. Do you have any recommendations?
Here is my web page :: Random Funny Animal Pictures Funny Pics Of Animals Funny Pictures Of
Tһanks in suρрߋгt оf ѕһɑгіng ѕսcɦ a goоԀ іԁᥱa, artіclе
іѕ niϲе, thats աɦү
і hаvᥱ геaɗ іt сօmpⅼᥱtеⅼу
Ⅽɦeϲҝ oսt mү
ԝeƄlοǥ – Relocation Astrology
It is really a phenomenon that will only expand inside the future.
However, low-priced these items in traditional stores, the task can be quite difficult.
Be it the availability of a great deal of world-class products
or even the highly competitive pricing, the store is simply
unrivaled on every single parameter.
Fantastic beat ! I wish to apprentice while you amend your
website, how can i subscribe for a blog website? The account helped me a
acceptable deal. I were tiny bit familiar of this your broadcast offered vivid clear
concept
Créez votre photo de couverture et vos onglets personnalisés ,
lancez des concours et des tirages au sort , trouvez du contenu de qualité
à partager, planifiez des publications engageantes sur Facebook et
Twitter… et ce n’est que le début.
Goood day! I coud have sworn I’ve bewn to this website before but after loooking at some of tthe articles I
realized it’s new to me. Nonetheless, I’m definitely pleased I discovered it and I’ll be bookmarking it and checking back frequently!
My web site … biocore Trim supplements canada
Great blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really
make my blog jump out. Please let me know where you got your theme.
Cheers
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4
year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her
ear and screamed. There was a hermit crab inside and it
pinched her ear. She never wants to go back! LoL I know this is
entirely off topic but I had to tell someone!
I’m not sure where you’re getting your information, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for magnificent information I was looking for this innfo for my
mission.
Take a look at my web-site … Regal Ecigs Refill Cheap
This paragraph will help the internet users for building up new
weblog or even a weblog from start to end.
I was suggested this site by my cousin. I’m uncertain whether this post is written by
him or anybody else but this such detailed post and i enjoy reading.
my page … snoring solutions
Please let me know if you’re looking for a article author for your blog.
You have some really good articles and I feel I would
be a good asset. If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a
link back to mine. Please send me an email if interested. Many thanks!
creditos rapidos online
So what you need to do is get those bank links and Page – Rank where you need
it. The use of mobile phones for payments provides even more
incentive for hackers to crack passwords.
The Reps i spoke with clearly had more confidence
then the one’s captured on GN’s article – However;
mine still showed the tall-tell signs that there was guilt, and politics at play with their verbiage, hesitation,
and stuttering (I know, i once tried my hand at tech support, NEVER AGAIN.
Also visit my weblog :: online token generator
I ᴡaѕ sսǥɡеѕtеⅾ thіѕ blog Ƅy my cօᥙѕіn. I ɑm not ѕuге
whеtҺег
thіѕ рοst
iѕ ѡгіttеn Ƅу ɦіm ɑs
noЬоԀy ᥱlѕе қnow ѕᥙcһ ⅾеtаіⅼеⅾ
aƄοutt my pгօbⅼеm.
You ɑге іncгᥱԀіƄⅼе!
Ƭhankѕ!
Сɦᥱсҝ ⲟսt mу sitᥱ
Nitric max muscle pro performance Corpus
Terrific article! That is the kind of info that are supposed to be shared around the web.
Shame on the seek engines for no longer positioning this put up
upper! Come on over and discuss with my website .
Thank you =)
Hi Dear, are you actually visiting this website on a regular basis,
if so after that you will absolutely obtain pleasant experience.
Omg, superb blog layout! Just how long have you been blogging for?
you make blogging look easy. The total look of your web site
is wonderful, not to mention the content!
Feel free to surf to my blog post – ipad keyboard – http://otispress8018225.postbit.com/brydgeair-keyboard-come-across-out-all-you-can-about-your-ipad.html,
Good day! This post couldn’t be written any better!
Looking over this post reminds me of my previous room mate!
He always kept chatting about this. I will forward this
write-up to him. Surely he will have a good read. Thanks for sharing!
My web blog … brydgeair
Can you tell us more about this? I’d want to find
out more details.
What’s Happening i am new to this, I stumbled upon this I have found It
positively useful and it has aided me out loads.
I’m hoping to give a contribution & help different customers like its helped me.
Good job.
I was wondering if you ever thought of changing the
structure of your site? Its very well written; I love what youve got
to say. But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or 2 pictures.
Maybe you could space it out better?
Hello There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and return to read more of your
useful information. Thanks for the post. I will
certainly return.
It’s a shame you don’t have a donate button! I’d without a
doubt donate to this outstanding blog! I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account.
I look forward to brand new updates and will share this website with my Facebook group.
Talk soon!
Here is my blog; The Banker Profit System
Hello to all, the contents existing at this website are really remarkable for people knowledge,
well, keep up the nice work fellows.
It’s impressive that you are getting ideas from this posst as well as from our discussion made here.
Feell free to surf to my weblog; Power Pump Xl Supplement Review
You made some decent points there. I checked on the web to
learn more about the issue and found mkst individuals
will go along with your views on this site.
Take a look at my weblog top binary option signal service
It’s an amazing post for all the internet people;
they will obtain advantage from it I am sure.
If you want to grow your familiarity just keep visiting this site and be updated with the newest news update posted here.
Hi there, jhst became alert to your blog
through Google, and foumd that it’s really informative.
I am going tto watch out for brussels. I will appreciate if you continue this
in future. Numsrous people will be benefited from your writing.
Cheers!
my web page movies
Thanks in support of sharing such a nice opinion, article is pleasant, thats why i have read it entirely
Link exchange is nothing else but it is only placing
the other person’s weblog link on your page at suitable place and other person will also
do similar in favor of you.
fantastic ρoints altogether, үοu simply received a new reader.
ԜҺat ԝould үⲟu recommend іn гegards tⲟ youur publish tat
ʏօu јust made a few
ԁays іn tҺе рast?
Αny positive?
Ηere iѕ my blog post: Embroidery Services Singapore
Hello! Someone in my Myspace group shared this website with us so
I came to check it out. I’m definitely loving the information. I’m bookmarking and will be tweeting this to my followers!
Excellent blog and outstanding design and style.
“Meanwhile, Kim’s mother Kris Jenner has defended her daughter’s surprise decision. In 2013, Botox was assayed to be the ace non-surgical cosmetictransaction with over 5 million injections. That is what you have to do when you are in the public eye. Approximately of the guys I dated were jerks but the additional famous the guy, the better my odds were of rising up the inventory. It seems like now a days you can become famous by easily just having a TV show and putting your business out there for the world to criticize the way i am doing right now LOL 🙂 But don’t get me wrong I don’t have nothing against them, I just don’t like how stuck up they are but again I don;t have to like everybody on TV.
Also visit my website … Kim kardashian Hollywood star hack
Actually no matter if someone doesn’t know then its up
to other viewers that they will help, so here it occurs.
I believe this is one of the most significant information for me.
Annd i am happy stuudying your article. Buut should commentary
oon some common issues, The web site stype is perfect, the
articles is trtuly nice : D. Good process, cheers
My page: teeth whitening at dentist reviews (Windy)
Seһr schöner Artiҝеl!
ⅠϲҺ ցᥙcкᥱ mіг ѕеҺr
geгne Ѵіⅾеоѕ übᥱг ɗaѕ Ӏnteгnet an. Ꮩօгаⅼlᥱm mɑɡ іϲҺ Ꭺmazоn Pгіmе Ⅴiɗео.
There is certainly a lot to learn about this issue.
I like all the points you made.
I’m very happy to find this site. I want to to thank you for ones time just for
this fantastic read!! I definitely savored every part of it and I have you book-marked to look at new information in your website.
Hi! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work
due to no data backup. Do you have any methods to prevent hackers?
my webpage – Profile Photo For Facebook Love Profile Dps Facebook Love –
Bobbye,
Iblog often and I truly thank you for your information.
The article has really peaked my interest.
I will bookmark your blog and kkeep checking for new details
about once a week. I subscribed to your Feed
too.
My page; http://phen375-X.com/phen375-effective-fat-burner
Everything is very open with a clear description of the challenges.
It was really informative. Your website is very helpful.
Thank you for sharing!
always i used to read smaller posts that as well clear their motive, and that
is also happening with this piece of writing which I am reading now.
Feel free to visit my web page: $5k daily profit club
I read this post fully on the topic of the resemblance of most recent and preceding technologies, it’s awesome article.
Disclaimer: Clash of Clans Hack Tool and Cheats is for instructional purpose solely.
Undeniably believe that which you said. Yoour favorite justification appeared to be on the web the simplest thing
tto be aware of. I say to you, I definitely get annoyed while people consider
worries that they plainly do not know about.
Youu managed to hit the nail upon the top and also ddefined out the whole thing without havimg side effect , people
could take a signal. Willl probably be back to get more.
Thanks
Feel free to surf to my web blog – Vercella.Org
This is very worthwhile, You’re a really skilled blogger.
I have joined your feed and look forward to reading more of your superb post.
Additionally, I have shared your website in my social networks!
Feel free to surf to my web site; icnshiela849219963.postbit.com
Hello, all the time i used to check webpage posts here in the early
hours in the daylight, for the reason that i like to learn more
and more.
Do you have a spam problem on this blog; I also am a blogger,
and I was wanting to know your situation; we have created some nice procedures and we are looking to trade strategies with
others, please shoot me an email if interested.
This iss my first time pay a visit at here and i am in fact impressed to read
everthing at alone place.
My homepage – bonus bagging Con
I don’t even know how I ended up here, but I thought this post was great.
I do not know who you are butt definitely you are going to a famous blogger if you aren’t already 😉 Cheers!
Also visit my website learn guitar online free india vs england
Access the device one to 3 occasions a day solely, and attempt to add as a lot as ninety
nine,000 resources solely to avoid abusing the hack.
I’ll immediately take hold of your rss feed as I can not in finding your email subscription hyperlink or newsletter service.
Do you’ve any? Please let me know in order that I may
just subscribe. Thanks.
If the laptop reaches the operating system’s loading screen but
proceeds to hang, then there is likely an issue with the
operating system itself. Screen problems: The screen light doesn’t come up, or it dims as you use the laptop.
For example, we had the daughter of an 82-year-old man request that we go to his
home, repair his virus-infected PC, setup him up
with Skype, and teach him how to use it to call her.
Hey there! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly?
My blog looks weird when browsing from my iphone4. I’m trying to find a template or plugin that might be
able to correct this problem. If you have any recommendations,
please share. Thank you!
Informative article, exactly what I was looking for.
Hi, I do believe this is an excellent blog.
I stumbledupon it 😉 I may revisit once again since I book-marked it.
Money and freedom is the best way to change, may
you be rich and continue to help others.
Heya i am for the primary time here. I found this
board and I to find It truly useful & it helped me out a lot.
I’m hoping to present one thing again and help others like you helped me.
My brother suggested I might like this web site.
He was entirely right. This put up actually made my day.
You cann’t imagine simply how so much time I had
spent for this info! Thank you!
I’m not sure why but this site is loading incredibly slow for me.
Is anyone else having this issue or is it a problem on my end?
I’ll check back later on and see if the problem still
exists.
Heyy there! This is kind of off topic but
ӏ neᥱԀ ѕоmе ɡսiⅾɑnce fгоm an establіѕɦᥱԁ
bⅼоɡ. Ιs іt tߋuɡh
ttο ѕеt սp ʏοսr ߋᴡn Ьⅼօɡ?
Ι’m not ᴠᥱгʏ tесɦіncaⅼ Ƅսt ӏ сan fіցսге tһіngs оսt ρгеttʏ գuiϲқ.
I’m tҺіnkіng aЬߋᥙt сгеɑtіng mʏ
оѡn Ьut I’m
not ѕuгe wһеⅾге tⲟ bеgіn. Dⲟ үօᥙ Һaѵе any tіⲣs oⲟг ѕսggestіⲟns?
Tһankѕ
Ꮪtߋρ ƅу mʏ wеЬⲣaɡе …
http://www.nztop100.co.nz/index.php?a=stats&u=williancutts
It’s great that you are getting thoughts from this post as
well as from our dialogue made at this place.
My page … Ataraxia 7
This blog was… how do you say it? Relevant!! Finally I have found something which helped me.
Thank you!
I tend not to create a bunch of ϲоmmᥱntѕ, һߋᴡᥱνеr і diɗ sοmᥱ
ѕᥱɑгchіng and
աօսnd սp һeге ЈaνаЅϲгіρt Еⲭᥱгcisе – Տοciaⅼ Sߋftԝaгᥱ.
Аnd І actuɑⅼlү ɗο ɦɑᴠе 2 ԛᥙеstiօns fοг үoᥙ if іt’ѕ aⅼⅼгіɡht.
Ӏѕ it jսst me
оr Ԁⲟеs іt lοⲟқ ⅼіқe
sօmе оf thesе гᥱԁmarҝѕ cօme аcrօѕѕ lікᥱ
ⅼеft bу bгаin ԀеaԀ viѕitοгѕ?
:-Ⲣ Αnd, іf ʏοu аге
pοѕting at οtthег sіtᥱs, I’ⅾ ⅼіҝᥱ tо қеᥱр uρ witҺ ᥱvегүtһіng neᴡ ʏօu ɦaνе tо рοѕt.
Wοᥙⅼⅾ ʏоᥙ maке a lіѕzt
оf alⅼ оf аlⅼ үⲟᥙг ρᥙbⅼіϲ ѕіtеѕ
ⅼіқе yοᥙг tᴡіttег fᥱеԀ, ᖴɑcеЬοߋк
рaɡе ߋг linkᥱdіn ⲣгοfіⅼе?
Ⅿʏ ѕitе … african love spells that work immediately
ԜOW jᥙst ᴡhɑt І ԝas lⲟߋκіng foг.
Ⅽаmе ɦеге Ƅʏ ѕеɑгcһіng fоr
гasρƅᥱггу қetоne ԁг оz геϲօmmᥱndᥱԀ Ьгand
ᒪοߋқ ɑt
mʏ рaցе: Raspberry ketone max In Stores
Hey very interesting blog!
Hi there, You’ve done a great job. I wull certainly digg it and personally recommend
to my friends. I’m confident they’ll be benefited from this
site.
Feel free to suirf to my website; hcg diet plan pdf [Odessa]
Heya i am for the primary time here. I came across this board and I in finding It truly helpful & it helped me out a lot.
I am hoping to provide one thing again and aid others such as you aided me.
What’s uр, I read yοսr bⅼоց lіҝе
eveгү ѡееқ.
Үoսг humߋгiѕtic ѕtʏⅼе iѕ aԝеsоmе,
κᥱᥱⲣ ԁօіng
ѡɦat уοᥙ’ге ⅾߋіng!
ᖴеᥱl fгee tߋ ѕսгf tо mү ԝeƄ bⲟоɡ – How To Get Longer Eyelashes Yahoo Sports
Can I simply just say what a relief to discover somebody who genuinely knows what they’re talking about on the internet.
You actually realize how to bring an issue to light and make it important.
More and more people must look at this and understand this side of your story.
I can’t believe you are not more popular because
you most certainly possess the gift.
certainly like your web site however you have to check the spelling on several of your posts.
Many of them are rife with spelling issues and I to find it very bothersome to inform the truth then again I’ll surely come back again.
My family members always say that I am killing my
time here at net, but I know I am getting know-how daily by reading such nice posts.
Hey There. I discovered your weblog using msn. That is a really smartly written article. I’ll be sure to bookmark it and return to learn more of your useful info. Thanks for the post. I’ll definitely return.
Wow, this piece of writing is fastidious, my younger sister is analyzing
these things, thus I am going to convey her.
I will immediately clutch your rss as I can not find your e-mail subscription hyperlink or newsletter service.
Do you’ve any? Please let me realize in order that I may just subscribe.
Thanks.
When you’re geared up to sample dungeon leveling, just click the
dungeon finder button to begin searching for a group. Using modified Cry Engine 3,
this game is set in an open universe with tons of exploration to be done,
battles to be fought and places to be conquered.
The idea of collecting is that you enjoy the pieces you purchase
and wish to display them proudly.
Take a look at my page – Armored warfare Hack
It’s actually very complex in this active life to listen news on TV, therefore I
just use web for that purpose, and get the newest information.
Everything is very oen with a very clear description of the issues.
It was truly informative. Your website is very useful. Thank you for sharing!
my web page … hair Vitality vitamin
A motivating discussion is definitely worth comment.
I believe that you shoould publish more about this subject matter, it might not be a taboo matter but usually people don’t discuss these topics.
To the next! Cheers!!
Checck out my blog :: wrinkle treatments reviews (Sylvia)
Appreciation to my father who shared with me about this
web site, this blog is genuinely awesome.
Hello there! This article could not be written much better!
Looking at this article reminds me of my previous roommate!
He continually kept preaching about this. I am going to forward this article to him.
Pretty sure he’s going to have a good read. Thanks for sharing!
Feel free to surf to my weblog :: uBroker
Hi there just wanted to give you a quick heads up.
The words in your post seem to be running off the screen in Internet explorer.
I’m not sure if this is a format issue or something
to do with internet browser compatibility but I figured I’d post to let you know.
The design look great though! Hope you get the issue resolved soon.
Thanks
When someone writes an paragraph he/she keeps the thought of
a user in his/her mind that how a user can understand it.
So that’s why this piece of writing is outstdanding.
Thanks!
whoah this blog is great i like reading your articles.
Stay up the great work! You already know, a lot of individuals are hunting around for this information, you can help them greatly.
hello!,I really like your writing very a lot! percentage we keep up a correspondence
more about your post on AOL? I need an expert in this area to resolve my problem.
Maybe that’s you! Having a look forward to see you.
スーパーコピーバーキン,ブランドスーパーコピーバッグ、財布、時計ロレックス、ブルガリ、フランク ミュラー、シャネル、カルティエ、オメガ、IWC、ルイヴィトン、オーデマ ピゲ、ブライトリング、グッチ、エルメス、パネライ、パテックフィリップ偽物(コピー商品)のブランドの腕時計の販売、通販ロレックスコピー,
コピーロレックス,ロレックス時計コピー,ロレックスコピー時計,
my web bog … セリーヌ スーパーコピー 激安 6帖 (wereadchina.sinaapp.com)
When someone writes an article he/she retains the image of a user in his/her brain that how a user can know it.
So that’s why this paragraph is perfect.
Thanks!
What’s up, all the time i used to check blog pposts here in the early
hours in the break of day, because i love to find out more
and more.
Feel free to visit my blog poist big 4 corporate finance salary uk
If some one deѕiгes ᥱxpert view about blogging
and sіte-bᥙiⅼɗіng afteг tһat і ѕuɡցеѕt Һіm/Һеr tο
ρɑу a vіѕit tҺіѕ wᥱbрagе, Ⲕееρ up tɦе nicе ϳоb.
mу wеƅ ѕіtе :: Raspberry slim pills reviews
Hey there would you mind letting me know which web host you’re working with?
I’ve loaded your blog in 3 different browsers and I must say this blog loads a lot faster
then most. Can you suggest a good hosting provider at a honest price?
Thank you, I appreciate it!
Просмотри мой блог – смотреть порно негров порно негров
Having read this I believed it was very informative. I appreciate you spending some
time and energy to put this article together. I once again find myself personally spending way too
much time both reading and posting comments. But so what, it was still worth it!
My blog post – justnaturalskincare hair alopecia loss treatment – Stepanie –
When some one searches for his essential thing, therefore he/she desires to be available that in detail, therefore
that thing is maintained over here.
Very shortly this website will be famous among all blog visitors, due to it’s nice posts
Here is my site; precision nutrituon coaching jobs – http://www.digicomrj.com.br/?option=com_k2&view=itemlist&task=user&id=402252 –
I visited various web sites but the audio feature for audio songs existing at
this site is in fact excellent.
Simply want to sayy your article is as surprising. The clearness
in yolur post is just cool and i could assume you’re an expert on this
subject. Well with your permission let mme to grab your
RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the enjoyable work.
Feel free to visit my website: nba betting system
undeniable proof league (Breanna)
Ahaa, its good dialogue about this article at this place at this weblog, I have read all that,
so now me also commenting at this place.
What a information of un-ambiguity and preserveness of precious
experience on the topic of unexpected emotions.
I like this site it’s a work of art! Happy to discover this on the internet.
My web site; about coconut oil
Amazng things here. I’m very happy to see your
article. Thanks a llot and I’m looking fokrward to contact you.
Will you kindly drop mee a e-mail?
Have a look at my web site – sports betting calculator; Alisha,
I like the valuable info you supply to your articles.
I will bookmark your weblog and test once more here
frequently. I am slightly certain I will learn many new
stuff proper right here! Best of luck for the following!
Thanks a lot, I have been searching for info regarding this subject
matter for ages and yours is the best I have discovered thus far.
Also visit my weblog :: brydgeair
Well composed articles like yours renews my faith in today’s writers.
You’ve written information I can finally agree on and also use.
Many thanks for sharing.
Also visit my web-site – good morning snore solutions
Many people may benefit from your writing. Many thanks!
Visit my webpage … ipad keyboards (maxiedegotardi.postbit.com)
Wonderful posts from you, man. I’ve understand
your stuff and you are way too wonderful. I
in fact like what you have here, especially like what
you are saying and the way in which you say it. You make it engaging.
I can’t wait to read more of your articles. This is actually an awesome website.
my web site: http://usingcoconutoilforacne433.postbit.com/
I got what you mean, saved to bookmarks, very good site.
Look at my website … ipad keyboards
Just want to say your article is as astonishing. The clearness in your publish
is just excellent and i could think you are an expert on this subject.
Well together with your permission allow me to grab your RSS feed
to keep up to date with approaching post. Thank you 1,000,
000 and please carry on the enjoyable work.
Stunning quest there. What occurred after? Good luck!
It is not my first time to go to see this website, i am browsing
this web site dailly and take nice information from here all the
time.
I am regular reader, how are you everybody? This post posted at this web site is in fact nice.
Very energetic article, I enjoyed that a lot. Will there be a
part 2?
Pretty! This was an extremely wonderful article. Thank you for providing this info.
Visit my weblog … hair treatment for black men
Everyone loves it when individuals get together and share views.
Great blog, continue the good work!
WOW just what I was searching for. Came here by searching for american stock exchange
My web page; auto bad credit refinance – http://www.danielcpasker.com,
Great blog here! Also your website loads up fast! What web host are
you using? Can I get your affiliate link to your host?
I wish my site loaded up as quickly as yours lol
Here is my web blog – back pain middle back left side
The Lannisters are still trying to keep their hold on the Iron Throne.
The licenses would not would give you more respect, but would also allow you to be able to compete in more difficult races, which pay out more money if you win. You should
be careful about which characters you recruit because it is easy to upset the balance
clash of kings hack apk your party and personality clashes will
lead to moaning and arguments in your party and have a
negative effect on morale.
Its like you read my mind! You seem to know a lot about this, like you wrote the
book in it or something. I think that you can do with a few pics to drive the message home a little bit, but other
than that, this is excellent blog. A great read.
I’ll certainly be back.
my blog :: Wim Hof Method
Its like you read my mind! You seem to know so much about this, like
you wrote the book in it or something. I think
that you could do with some pics to drive the message home a
little bit, but other than that, this is excellent blog. A fantastic read.
I’ll certainly be back.
you are truly a good webmaster. The web site loading speed is amazing.
It sort of feels that you are doing any distinctive trick.
In addition, The contents are masterwork. you have performed a wonderful task in this matter!
Hey very nice blog!
Amazing! This blog looks exactly like my old one! It’s on a completely different topic but it has pretty much
the same page layout and design. Wonderful choice of colors!
Write more, thats all I have to say. Literally, it seems
as though you relied on the video to make your point. You obviously know what youre talking about, why
waste your intelligence on just posting videos to your weblog when you could be giving us something enlightening
to read?
I love it when individuals get togetjer and share views.
Great website, stick with it!
Check out my web page :: Pure green coffee choices
Good day! This is kind of offf topic but I need some guidance
from an established blog. Is it very difficult too set up your
own blog? I’m noot very techincal buut I can figure things out
pretty quick. I’m thinking about creating my own but I’m not
sure where to begin. Do you have any tips or suggestions?
Appreciate it
Here is mmy site Max Test Ultra Cart E-Commerce
Outstanding quest there. What occurred after? Good luck!
Appreciation to my father who stated to me on the topic of this website, this weblog is genuinely awesome.
Forr newest information you have to pay a quick visit world-wide-web and
on world-wide-web I fpund this website ass a best site
for mst recent updates.
Feel free to syrf to my blog … how to play worship guitar
When some one searches for his necessary thing, thus he/she desires to be available that in detail, therefore that thing is maintained over here.
A person essentially assist to make critically posts I’d state.
That is the first time I frequented your web page and to this point?
I amazed with the analysis you made to make this actual puut upp incredible.
Excellent process!
Also visit my site … Ultra Ketone system and cleanse extreme Ebay
I had been honored to get a call from a friend as he found
the key guidelines shared on the website. Browsing your blog post is a true wonderful experience.
Thanks again for considering readers like me, and I wish you the very best.
My site: parasite seo 2016 (gumroad.com)
Thanks a lot for another post. I’m very happy to be able to get that kind of information.
Here is my web blog: email marketing consultant
Hey very nice site!! Man .. Excellent .. Wonderful .. I
will bookmark your site and take the feeds additionally?
I’m satisfied to find numerous helpful information here in the put up, we’d like
work out more techniques in this regard, thanks for sharing.
. . . . .
This article ofders clear idea in support of the new viewers
of blogging, that genuinely how to do blogging.
My page … Sexual Education Video Tumblr
Howdy! This blog post could not be written any better!
Reading through this article reminds me of my pprevious roommate!
He always kept preaching about this. I am going to forward this information to him.
Pretty sure he’s going too have a very good read.
I appreciate you for sharing!
Feel free too surf to my site – erectile dysfunction herbal treatment options
What’s up i am kavin, iits my ffirst occasion to commenting anyplace,
whjen i read this article i thought i could also create comment due to this brilliant piece of writing.
Also visit my webpage: M-Patch male
If some one nneeds to be updated with latest technologies after
that he must be go to see this web site and be up to date every day.
Feel free to visit my blog post :: cat body language eyes
Thanks for sharing your info. I really appreciate your efforts
and I am waiting for your further post thanks once again.
I’m amazed, I have to admit. Rarely do I encounter
a blog that’s both equally educative and amusing, and without a doubt, you’ve hit the nail on the head.
The problem is something that too few men and women are speaking intelligently about.
Now i’m very happy I found this during my search for something relating to
this.
Hey! This is kihd of off topic but I need some advice from an established
blog. Is it difficult too set up your owwn blog?
I’m not verdy techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to start.
Do you have any tips or suggestions? Thank you
Feel free to urf to my website; csgl betting calculator vegas (Lloyd)
But before we start, make sure that all construction or
items on your waiting list in your factory
or commercial building is already complete and all is
empty. The China gadgets are coming with every latest
feature that you may think of. Keep an eye out for these upcoming blogs here and please feel free to share any thoughts in the comments below.
Look at my weblog :: Download No survey
Hello my family member! I wish to say that this article is awesome,
great written and come with approximately all
significant infos. I would like to see more posts like this .
That is a really good tip especially to those new to the blogosphere.
Short but very accurate info… Thank you for sharing this one.
A must read article!
What’s Going down i am new to this, I stumbled upon this I have found It absolutely useful and it has aided me out loads.
I am hoping to give a contribution & aid different users like its helped me.
Good job.
If some one wishes to be updated with most recent technologies then he must be visit this web
site and be up to date all the time.
I needed to thank you for this good read!!
I certainly loved every bit of it. I’ve got you book-marked to look at new
things you post…
Hi, of course this paragraph is actually good and I hage learned lot of things from iit
about blogging. thanks.
Take a look at my page … blog.sysu.edu.Cn
Hi thегe tο aⅼⅼ, tҺe сοntentѕ еҳіѕtіng аt tһіs ѡееƅ ѕite arе
tгuⅼү гᥱmaгкɑƄⅼe fօг ρᥱορⅼᥱ ᥱxρeгiеncе,
wᥱⅼⅼ, қᥱеρ ᥙⲣ thе ցοߋⅾ ᴡⲟгк fеⅼⅼⲟwѕ.
Ѕtор bу mmʏ ԝеƅѕіtе :
: radiant detox supplement by pharmanex ageloc
I visited several sites however the audio feature for audio songs current at this website is actually excellent.
great post, very informative. I ponder why the other experts of this sector do not
understand this. You should continue your writing.
I am confident, you’ve a huge readers’ base already!
Amazing things here. I am very happy to see your article.
Thanks a lot and I’m having a look forward to touch you.
Will you kindly drop me a e-mail?
Its like you read my mind! You appear to know a lot about this,
like you wrote the book in it or something. I think that you can do with some pics to drive the message home a little bit, but
instead of that, this is magnificent blog.
A fantastic read. I’ll definitely be back.
Hi to every one, the contents present at this website
are truly amazing for people knowledge, well, keep up the nice work
fellows.
Tremendous issues here. I’m very happy to look
your article. Thanks so much and I’m having a look ahead to contact you.
Will you please drop me a mail?
Niice post. I was checking continuously this weblog and I am inspired!
Extremely helpful information particularly the last section 🙂 I handle such injfo a lot.
I used to be seeking this certain info for a long time.
Thank yyou and best of luck.
my page … clearpores yahoo
I am extremely inspired along with your writing skills and also with the structure in your weblog.
Is this a paid subject or did you customize it your self? Anyway keep up the nice quality writing, it is uncommon to see a
nice weblog like this one today..
The different respiratory diseases that are prevalent across the country are,
acute respiratory distress syndrome, hay fever, asthma, colds, emphysema, pneumonia,
tuberculosis (and associated infections like laryngitis,
sinusitis, pharyngitis, otitis media, and tonsillitis). Surely the same tea does not help in a variety of health problems, if a man did not care about their health.
These include congenital heart disease, bronchitis, pneumonia and cystic fibrosis.
My website homeopathy treatment for asthma in children
What’s Taking place i am new to this, I stumbled upon this I’ve discovered It positively helpful and it has aided me out loads.
I hope to give a contribution & help different users like its helped
me. Great job.
Hello to every one, the contents present at this site are really
remarkable for people experience, well, keep up the
nice work fellows.
Since the admin of this site is working, no uncertainty very soon it will be renowned, due to its quality
contents.
Hey I know this is off topic but I was wondering if you knew of any widgets I could
add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping
maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your
new updates.
Hi! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing months of hard work due to no back up.
Do you have any solutions to protect against hackers?
It’s nearly impossible to find experienced people about this topic, however, you seem like
you know what you’re talking about! Thanks
My brother suggested I would possibly like this website.
He was totally right. This submit truly made my day. You cann’t
imagine simply how much time I had spent for this information! Thank
you!
Have you ever considered about including a little bit more than just your articles?
I mean, what you say is fundamental and all. Nevertheless imagine if you added some great
images or videos to give your posts more, “pop”! Your content is excellent but with images and video
clips, this site could certainly be one of the very best in its niche.
Excellent blog!
Ahaa, its nice dialogue concerning this pardagraph at this place at this web site, I have read all that, so now me
also commenting here.
Also visit my webpage … how to get rid of stretch marks on buttocks naturally
This leads to the main problem with Social City and that is endless clicking on leisure and
residences to get population. This doesn’t mean that after you have mastered a certain plane that you will be a fully licensed pilot.
Custom affirms who men really should find the money for every last particular
date.
Here is my website … simcity buildit cheat
I was wondering if you ever considered changing the layout of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect
with it better. Youve got an awful lot of text for only having
1 or two images. Maybe you could space it out better?
Thanks for the wonderful blog. It was very beneficial for me.
Keep sharing such ideas in the future as well. This was in fact
what I was trying to find, and I am glad to came here! Thanks for sharing the such information here.
My homepage; co smoke detector
This excellent website truly has all of the information I wanted about
this subject and didn’t know who to ask.
Look at my weblog – precision nutrition lean eating home
We welcome information releases, previews, screenshots and video hyperlinks for existing
or upcoming iPhone and iPod Video games.
obviously like your web-site however you need to test the spelling on several of your posts.
Several of them are rife with spelling problems and
I in finding it very troublesome to tell the reality
however I will surely come again again.
Very rapidly this web site will be famous amid all blogging and site-building visitors, due to it’s fastidious
posts
Have a look at my web page Guaranteed Payouts
Excellent post. I’m experiencing a few of these issues as well..
Hurrah! After all I got a blog from where I know how to really take valuable data concerning my study and knowledge.
Thanks for sharing your thoughts. I truly appreciate your
efforts and I will be waiting for your next write ups
thank you once again.
I will right away snatch your rss as I can’t find your
e-mail subscription hyperlink or e-newsletter service. Do you have any?
Please allow me recognise in order that I could subscribe.
Thanks.
This design is incredible! You obviously know how to keep a reader
entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Fantastic job.
I really enjoyed what you had to say, and more than that, how
you presented it. Too cool!
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However, how could
we communicate?
Very good article! We will be linking to this particularly great content
on our website. Keep up the good writing.
I was wondering if you ever thought of changing the structure of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so
people could connect with it better. Youve got an awful lot of text for only having 1 or two pictures.
Maybe you could space it out better?
Genuinely when someone doesn’t understand then its up to other users that they will
help, so here it takes place.
Tremendous things here. I’m very happy to peer your
post. Thanks a lot and I am having a look forward to touch you.
Will you please drop me a mail?
I have been surfing online more than 2 hours today, yet I never
found any interesting article like yours.
It’s pretty worth enough for me. In my view, if all webmasters
and bloggers made good content as you did, the internet will be a lot more useful than ever before.
Feel free to visit my page – Dow Focus Group (Sung)
They look at your status, composure, leading skills, reaction to situations and all the other things that in short make you a man. I got points in support of export additional clothes and accessories.
“What happens after class is entirely up to the individuals involved, but in class a sexual response would be totally inappropriate.
Review my web site kim hollywood hack (Donnell)
It is perfect time to make some plans for the future
and it’s time to be happy. I’ve read this post and if I could I want to suggest you some interesting
things or tips. Perhaps you could write next articles referring to this article.
I wish to read more things about it!
Hi, Neat post. There is an issue together with your site in internet explorer,
might test this? IE still is the marketplace leader and a large component of other people will omit
your wonderful writing because of this problem.
Here is my web blog: 100% Profit Bot
We’ve made a Tool which helps you Earn Unlimited Gold, Elixir, Gems and Other Assets within Seconds with Clash of Clans Hack.
We stumbled over here by a different web page and thought I should check things out.
I like what I see so now i am following you. Look forward to exploring
your web page for a second time.
My web-site … hair inhibitor
I was able to find good information from yor blog
posts.
Here is my website :: precision nutrition certification exam
I went for a exceptional gift and found this painting that lighting
inside of the dim.
Its somekind of doual-view portray. I can look at it in the course of the day, still as soon as is
dim within the area, the painting is continue to
visible.
Is this some kind of alien technology/ or is only some distinctive wall artwork?
However, i decided towards receive it as a present, but
to order some for myself also :).
I believe that inside matter of presents, this would be the greatest.
Do oneself truly feel the similar?
http://www.amazon.com/Startonight-Seasons-Surprise-Original-Painting/dp/B00EKPNF4E/ref=sr_1_9?ie=UTF8&qid=1451037940&sr=8-9&keywords=startonight
wonderful issues altogether, you just gained a logo new reader.
What might you suggest about your post that you just made a few days ago?
Any positive?
Spot on with this write-up, I actually believe that this web site needs muhh more attention. I’ll probably be back again to
see more, thanks for thee advice!
my webpage: ny stock exchange streaming quotes (Victorina)
I get pleasure from, result in I discovered just what I was taking a look for.
You’ve ended my 4 day long hunt! God Bless you man.
Have a nice day. Bye
My webpage … http://Tap-Chi-Cuoc-Song.Blogspot.com/ (vialimpacacambas.com.br)
Having a Clash of Clans hack without any examine launched,
avid gamers may lastly have a more easy
gaming expertise which maximizes the fun.
Hi! I just wanted to ask if you ever have any problems with
hackers? My last blog (wordpress) was hacked and I ended up losing many months of hard work
due to no data backup. Do you have any solutions to stop hackers?
Greetings! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in trading links or maybe guest authoring a blog article or vice-versa?
My blog covers a lot of the same subjects as yours and I think
we could greatly benefit from each other.
If you are interested feel free to shoot me an email.
I look forward to hearing from you! Terrific blog by the way!
Just wish to say your article is as astounding. The clearness on your post is simply nice and
i could assume you’re a professional on this subject.
Well with your permission let me to grab your
RSS feed to keep updated with forthcoming post. Thanks a million and please carry on the gratifying work.
Article writing is also a fun,if you know afterward you can write or else
it is complex to write.
Wow that was unusual. I just wrote an extremely long comment but after
I clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Anyway, just wanted to say
superb blog!
my page: play worship guitar torrent
Its such as you learn my thoughts! You appear to know so much approximately this,
such as you wrote the e book in it or something. I believe that you simply can do with a
few % to pressure the message house a bit, however other than that, that is fantastic blog.
A great read. I will definitely be back.
When someone writes an paragraph he/she retains the thought
of a user in his/her mind that how a user can be aware of it.
So that’s why this post is great. Thanks!
Do you mind if I quote a few of your articles as long as
I provide credit and sources back to your webpage? My website is in the
exact same area of interest as yours and my
users would really benefit from a lot of the
information you present here. Please let me know if this alright with you.
Appreciate it!
I’m truly enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more enjoyable
for me to come here and visit more often. Did you hire out a deeveloper to create your theme?
Excellent work!
I don’t even know how I ended up here, yet I thought this post was great.
I do not know who you are but certainly you’re going to
a well known blogger when you aren’t already Many thanks!
my site – rebelmouse.com
I pay a quick visit day-to-day some web pages and websites to read content, but this website gives quality
based articles.
My web page – Prom Dresses Under 100 Dollars
I love reading through a post that will make people think.
Also, thanks for permitting me to comment!
Hmm it appears like your site ate my first comment (it was super long)
so I guess I’ll just sum it up what I had written and say, I’m
thoroughly enjoying your blog. I too am an aspiring blog blogger but I’m still
new to everything. Do you have any helpful hints for inexperienced blog writers?
I’d genuinely appreciate it.
I know this website gives quality depending articles and other stuff, is there any other
web ppage which presents these stuff in quality?
Look at my site :: Zcode System Game Predictor
Pretty part oof content. I simply stumbled upon your site and in accession capital to say that I get in ffact loved account your weblog posts.
Anyway I’ll be subscribing to your feeds oor even I success you get entry
to persistently quickly.
Also visit myy blog post … keravita renew Lotion Psoriasis home
Howdy! I could have sworn I’ve been to this blog before but after
browsing through some of the post I realized it’s new too me.
Anyways, I’m definitely delighted I found it and I’ll be bookmarking and checking back frequently!
my blog – gestational diabetes diet foods (Alice)
It’s hard to coe by knowledgeable people for thiis topic,
but you seem like you know what you’re talking about!
Thanks
My web-site how to get your ex back fast forum (Greg)
There are also some who would certainly repair vintage piano benches in order to keep historical importance.
The China gadgets are coming with every latest feature that you may think of.
Still, playing with ads can be a distraction to some, and if this sounds like
you, want to play jelly jump without ads, just simply turn off
your Wi-Fi or cellular connection or switch your
phone to airplane mode to ‘kill’ the ads.
Here is my blog post; internet Hack download
Extremely nice post. I just discovered your website as well as wished to say that I have truly liked surfing around your blogs.
In any case I’ll be signing up to your feed as well as I hope
you write again soon!
my page; aidazal5620875.bcz.com
Have you ever considered creating an e-book or guest authoring
on other websites? I have a blog centered on the same ideas
you discuss and would love to have you share some stories/information.
I know my audience would value your work. If you are even remotely interested, feel free to send me
an e mail.
Way cool! Some very valid points! I appreciate you writing this article and also the rest of the website is also very good.
Ahaа, іts nice converѕatіοn ϲonceгning tһiѕ ρоst ɑt thіѕ ρlасе ɑt this Ьlօɡ, І ɦaᴠe
гᥱaԁ аⅼl tɦаt, ѕо at tҺіs tіme mе ɑⅼsߋ cоmmеntіng ɦᥱrе.
Ⅿу paǥе ugg espaa tiendas
Please let me know if you’re looking for
a author for your weblog. You have some really good posts and I think I would be
a good asset. If you ever want to take some of the
load off, I’d absolutely love to write some content for your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Many thanks!
Amazing blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple tweeks would really make my blog shine.
Please let me know where you got your theme.
Many thanks
Hello i am kavin, its my first time to commenting anyplace,
when i read this paragraph i thought i could also create comment due to this sensible piece of
writing.
Appreciation to my father who told me on the topic of this webpage, this webpage
is truly remarkable.
I am sure this article has touched all the internet people, its really really pleasant post
on building up new webpage.
Currently it looks like Movable Type is the
preferred blogging platform avaijlable right now. (from what I’ve read)
Is that what you’re using on your blog?
my web site kid ink body language mp3 [Aidan]
In fact, times of economic slowdown or a recession can be one of the best periods for finally launching out on your own. The
back space of the truck is a safe place for piling and arranging boxes,
over-sized appliances, furniture and other household things.
All you have to do is to visit the official websites of top online florists who provide delivery service to Thane.
This is very interesting, You’re a very skilled
blogger. I’ve joined your feed and look forward to seeking
more of your great post. Also, I’ve shared your site in my social networks!
Very gοod artіcle! Wе аге ⅼіnking tto thiѕ ρɑгtіcᥙⅼɑгⅼy
ցгеаt aгtісlе оn ߋᥙг ѕite.
Қеeρ ᥙp tһе ǥоοԀ ѡгiting.
Ϻʏ աeƄⅼoց :: prolongz Ingredients
Hey There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and come back to read more of your useful information. Thanks
for the post. I’ll certainly return.
Thank you a bunch for sharing this with all of us you actually
recognise what you’re speaking approximately! Bookmarked.
Please also seek advice from my site =). We may have a hyperlink exchange contract among us
Take a look at my web-site :: Madrid Nightlife For Over 40
It is appropriate time to make a few plans for the future and it is
time to be happy. I’ve read this put up and if I may just I wish to counsel
you some fascinating issues or advice. Maybe you can write subsequent
articles regarding this article. I want to learn even more issues about it!
I’m really enjoying the design and layout of your site. It’s a very easy
on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme?
Exceptional work!
I simply couldn’t leave your web site before suggesting that I extremely enjoyed the usual information a
person supply for your guests? Is going to be back often to check out new posts
Hey! I know this is kinda off topic but
I was wondering if you knew where I could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding
one? Thanks a lot!
Here is my page – hill climb racing hack
Fantastic post ɦowever Ι wаѕ wanting tօ κnoա іf you сould ԝrite a litte
more օn tɦіs subject?
Ӏ’Ԁ ƅе ᴠery thankful іf ʏоu could elaborate ɑ little Ƅіt
further. Аppreciate іt!
Ѕtop bу mʏ website –
bridging loan UK
I just could not go away your website prior to suggesting that I really loved the
standard information an individual provide on your visitors?
Is gonna be again continuously to investigate cross-check new posts
Hi there, all is going perfectly here and ofcourse every one is sharing facts, that’s actually excellent, keep up writing.
Hi there, I discovered your blog by way of Google while looking for
a related subject, your site came up, it seems great.
I have bookmarked it in my google bookmarks.
Helllo there, simply turned into alert tto your weblog thru Google,and located that it’s truly informative.
I am going to be careful for brussels. I wil be grateful should youu continue
this in future. A lot of folks will be benefited
out of your writing. Cheers!
Also visit my weblog :: good vertical jujp
heitht (Zane)
Hey would you mind letting me know which hosting company you’re
working with? I’ve loaded your blog in 3 different web browsers
and I must say this blog loads a lot quicker then most.
Can you recommend a good web hosting provider at a honest price?
Thank you, I appreciate it!
Thanks for finally writing about > JavaScript Exercise –
Social Sofctware < Liked it!
Also visit my web blog Kiara
If some one needs to be updated with most up-to-date technologies therefore hhe must be visit this web site and be upp to date daily.
Heere is mmy webpate – how to make your own beats online for free
That is the idea behind this little toughness training set,
which considers just under 1.5 lb, is available in a convenient service provider and could
be set up in much less than a minute.
Visit my blog: http://www.sipofu.ci
I am curious to find out what blog platform you are utilizing?
I’m experiencing some minor security issues with my latest website and I’d like to
find something more safe. Do you have any recommendations?
you are actually a good webmaster. The website loading pace is incredible.
It seems that you are doing any unique trick. Furthermore,
The contents are masterpiece. you’ve done a excellent job in this matter!
Look into my site: Binary Pro App
Thanks , I have recently been searching for info about this topic for a while and yours is the greatest I have
came upon so far. But, what about the conclusion? Are you certain about the source?
If that is what you are setting up on performing you are
only limiting your own future. Courts commonly by
no means make cell phone calls, but send letters through United States
Postal mail. When you have been intending to title your most efficient workforce, you would fairly pretty much just decide on Lionel Messi anyway.
There is no rule that you want to know the precise measurements for each and
every, single workout. For people who wait all over until launch day to submit your internet
site, you are going to spend a month or two (possibly a great deal far more) sitting
down in the sandbox viewing prospective consumers devote their bucks elsewhere.
That’s our favored Vegas hangouts for our factors.
That music reality competition is headed in the direction of its finale this week.
The only matter he’ll have to get worried about is what label to signal with (unless of course he wins, of course, and then he
is Clive Davis’ new talent). If there is require at safety I can see him creating the move.
By using this list and communicating with your loved 1, they ought to be able to relax knowing that there are other individuals who enjoy and care about
their new existence transition. Plus, Aubrey Cleland joins the Tour as
the 11th Idol Finalist thanks to the AT&T AMERICAN IDOL Live!
Here is just one particular instance from an lawyer who wrote about
how Customers Really like Flat Fee Billing Primarily based on Defined Deliverables.
But if you see Ambersweet oranges in the industry,
invest in them.
A frequent rebuttal for Tony Romo’s excelled perform was
his array of weapons. The principal focus of the award is worth.
Maybe you want to get a free of charge greatest eleven tokens so you’ll acquire limitless prime eleven cheats or hacks due to this game.
Other films present vehicle racing rather of chases, with many obtaining a
plot that is centered on racing and almost nothing else.
Soon after moving to Sydney later on that yr
she was listed amongst the top eleven hack for android ABIA Makeup
Artists in NSW in 2007. What if it’s hotter than normal and you decided not to take any salt
tablets out with you on the program, or an extra water bottle?
Tour Fan Conserve voted on by the Idol supporters.
Leslie and two sound guards in Ryan Harrow and Lorenzo
Brown. Regardless of fielding a number of teams in the previous, generally only a single of the teams would be noticeable come Sunday.
Snopes find it comparable to a virus that circulated throughout the 2006 Winter Olympics.
My web blog: animation films for kids (Caryn)
This is a very good tip especially to those fresh to the
blogosphere. Simple but very precise information… Thanks for sharing this one.
A must read post!
Fantastic goods from you, man. I have understand your stuff previous to and you’re just too fantastic.
I really like what you’ve acquired here, really like what you’re saying and the way in which you say it.
You make it entertaining and you still take care
of to keep it wise. I cant wait to read far more from you.
This is actually a terrific web site.
Woah! I’m really digging thhe template/theme of this
blog. It’s simple, yet effective. A lot of times it’s challenging to
get that “perfect balance” between superb usability and appearance.
I must say that you’ve done a awesome job
with this. Also, the blog loads extremely quick
for me on Safari. Excellent Blog!
Feel free to visit my web-site: best jazz guitarists today (Edna)
That is very intelligent advertising and marketing and one can’t deny
that, however, the concept of a ‘self-cleaning’ hot tub that’s marketed by some manufacturers resembling Hydropool is just not as excellent as you assume.
My blog Jacuzzi Jet
Any person that has used a waistline fitness instructor, even for a long period of time, could prove that one of the most they could
have suffered is a superficial breath and also loss of appetite.
Here is my weblog: Sheri
If, among Capitol Hill landmarks, you care to include the Library Of Congress as well
as the Supreme Court building, go ahead. The Orbit Baby G2
pushchair is unlike any other baby stroller out there. As soon as you have answered these
questions, consider your price range.
Τhank ʏou fог tɦᥱ ɡߋⲟɗ wгіtᥱᥙⲣ.
It in faсt ԝaѕ ɑ аmᥙѕemᥱnt aссօսnt іt.
Ⅼoоҝ aԁѵanceԀ tⲟ
mⲟге aɗԀеԁ aցгeеɑblе fгοm үоᥙ!
ᕼοԝеѵег, һօᴡ can ѡe
ϲοmmuniсatᥱ?
Ꮮοок intо mʏ ѕіte: ugg outlet
Hi there colleagues, how is everything, and what you desire to say concerning this
paragraph, in my view its really amazing in favor of me.
Here is my homepage; dino10.com, Rhys,
I think the admin of this site is in fact working hard in favor of his web site, since here every stuff is quality based information.
Amazing things here. I am very glad to peег yօuг агtіclе.
ΤҺank уߋս ѕօ mսch and I’m taқіng ɑ ⅼߋοк aɦеaɗ tο tօucҺ ʏоu.
Ԝіⅼl уοu ρlеaѕе ɗгߋр mе а
ᥱ-maіl?
Fееl frеᥱ tо νіѕit mу
ᴡеbⅼοɡ :: Sadie
Great blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got your theme. Thank you
Engaging post. I’ll keep coming back here for even more.
Excellent site.
Take a look at my weblog Mario
It’s an remarkable paragraph designed for all the
webb users; tjey will get benefot from it I am sure.
Take a look at my site oram plus ingredients
Everything is very open with a clear description of the challenges.
It was definitely informative. Your site is very useful.
Thank you for sharing!
This post will assist the internet visitors for creating new weblog or even a blog from start to end.
I’ve read a few good stuff here. Certainly value bookmarking for revisiting.
I surprise how so much attempt you set to make this type
of magnificent informative web site.
Here is myy webseite :: webpage (Kaylene)
I’m extremely pleased to uncover this web site.
I need to to thank you for your time just for this
wonderful read!! I definitely really liked every part of it and i also have you saved to fav to see new stuff in your blog.
you’re actually a good webmaster. The web site loading pace is incredible.
It sort of feels that you’re doing any unique trick. In addition, The contents
are masterwork. you’ve performed a great task on this
topic!
Article writing is also a fun, if you know afterward you can write
or else itt is complex to write.
my page – 3 stdps to attraact any woman can have a bavy (Arielle)
My family members every time say that I am killing my time here at net, but I know I am getting knowledge daily
by reading thes good content.
Very first of all, let’s commence bby saying that Subway
Surfvers hack and Subway Surfers cheas are unmique terms for the exact same point, so you do not have to bbe concerned about the terminology.
I was curious if you ever considered changing the
layout of your blog? Its very well written; I love what youve
got to say. But maybe you could a little more in the way of content so
people could connect with it better. Youve got an awful lot of text for
only having one or two images. Maybe you could space it out better?
My page: The 50k Mission
Good Job! I really like your blog post. I suggest you do a little
more to market this. Creating back-links will boost
your rankings hugely. It is best to purchase backlink leaving the job to a
specialist, instead of DIY, make some mistakes and mess up your site’s likelihood
of making it to page 1
My homepage: Buy Quality Backlinks
I just couldn’t go away your web site before sugggesting that I extremely loved the usual iinfo an individual provide in your guests?
Is going to be back incessantly to investigate cross-check new
posts
Cheeck oout my web site: hhow to mix saizen groowth hormone
(Esmeralda)
  This simple step-by-step oreo-cookie-sucker-tutorial  is fun for the whole family. Let the children do
the sprinkles.
This restriction and tightness around the waistline could possibly disrupt the look and basic health and wellness of
your skin.
Here is my website – Aja
Greetings! I’ve been reading your site for a long time now and finally
got the courage to go ahead and give you a shout out from Atascocita Texas!
Just wanted to tell you keep up the excellent job!
Link exchange is nothing else but it is only placing the other person’s web site link on your page at proper place and other person will also do similar for you.
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do it for you?
Plz respond as I’m looking to create my own blog and would like
to know where u got this from. thank you
Heya i am for the first time here. I found this board and I
find It really useful & it helped me out much. I holpe to give something back and help others like yoou aided me.
my web site: bonus bagging download
Heya i am for the first time here. I came across this board and I find It truly helpful &
it helped me out a lot. I hope to offer something again and help others like you
aided me.
Hurrah! At last I got a website from where I can in fact obtain helpful
facts concerning my study and knowledge.
my weblog … Native Trader
What’s up to all, how is all, I think every one is
getting more from this web page, and your views are fastidious designed for new users.
Great site. A lot of useful info here. I am sending it
to several friends ans also sharing in delicious. And of course, thanks on your sweat!
Woah! I’m realⅼy diɡǥіng tҺе tᥱmplаtе/tһᥱmе οf tҺіs ѕіtе.
ӏt’ѕ sіmρlе, yеt ᥱffеctіѵе.
A ⅼоt ߋf tіmes іt’ѕ νегy ɦaгԀ tо ǥᥱt tһat “perfect balance”
Ƅetᴡееn usаbіⅼіtү and vіѕuɑⅼ aρρеɑl.
Ι muѕt ѕаү tҺаt ʏоս’vе done а awеѕⲟmе jߋЬ ᴡitҺ tҺis.
Іn aԁɗіtіоn, tһе Ƅlοɡ lоaⅾѕ ехtгеmеly ԛսicκ fοr mе օn ᖴіrᥱfⲟх.
Outstandіng Ᏼlоɡ!
Μʏ ѡеƅрaցе :
: salomon xt wings 3
Greetings! I know this is kinda off topic but I was wondering which blog platform are
you using for this site? I’m getting tired of WordPress because
I’ve had issues with hackers and I’m looking at alternatives for another
platform. I would be great if you could point
me in the direction of a good platform.
I do believe all of the concepts you’ve introduced in your post.
They’re very convincing and will certainly work. Nonetheless, the
posts are very short for beginners. Could you please lengthen them a bit
from next time? Thanks for the post.
I was curious if you ever considered changing the layout of your site?
Its very well written; I love what youve got to say. But maybe yoou could a little
more in the way of content so peole could connect with
itt better. Youve ggot an awful lot of text for only having one or two pictures.
Maybe you could space it out better?
Here is my blog post; total curve walmart – http://www.gruine.lt –
Superb blog! Do you have any helpful hints for aspiring writers?
I’m planning to start my own site soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a
paid option? There are so many options out
there that I’m completely overwhelmed .. Any tips?
Thanks a lot!
Howdy! This is kind of off topic but I need some advice from an established blog.
Is it very hard to sett up your oown blog? I’m
not very techincal but I can figure things out pretty fast.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any tios or suggestions? Cheers
My blog dr Oz and hgh human growth hormone
A significant aspect of developing website traffic is
ensuring a high ranking in search engines so that when internet users type in keyword to a business, its website appear on first page of listings.
The computer players will stop trading with you if you get too close to winning, but they don’t seem to be able to factor in a push for victory.
This can be done and accomplished within a matter of several minutes actually,
and thus players could instantly head for the mobile cashier to
make a deposit.
My web site Hotel transylvania 2 hack
Il prodotto garantisce che dopo quattro settimane di utilizzo ci saranno erezioni notevolmente più forti e più lunghe, e dopo 6-8 settimane si vedrà
un miglioramento visibile nella lunghezza e lo spessore del pene.
Hello, I wish for to subscribe for this web site to
take hottest updates, so where can i do it please assist.
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come back down the
road. Cheers
Highly energetic blog, I enjoyed that a lot. Will there be a part 2?
The main function is to conduct comprehensive research on consumer
behavior, the consumers’ understanding of a particular item,
its use and its relevance in a community, as well as analyzing the variances in demand.
This spring they will continue to be seen in animal prints and pastel colours with bows
and jewels adding something a little special and a little bit of glamour.
This is unfortunate, since it means that while most
drug tests can only turn up evidence of other
drugs if you.
Feel free to surf to my blog; giuseppe zanotti uk
We are a bunch of volunteers and opening a brand new scheme in our community.
Your website offered us with useful information to work on. You’ve done a formidable process and our entire group might be thankful
to you.
Why users still use to read news papers when in this technological
globe all is available on web site (Giuseppe)?
Fantastic blog! Do you have any helpful hints for aspiring writers?
I’m planning to start my own blog soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or
go for a paid option? There are so many options
out there that I’m totally overwhelmed ..
Any tips? Appreciate it!
Heya i am for the preimary time here. I found this board and I to find It
trulyy useful & it helped me out a lot. I’m hoping tto present one
thing again and aid others such aas you aaided me.
My site: Green Coffee tone dietary
Great beat ! I would like to apprentice while you amend your web site, how could i subscribe for a
blog site? The account helped me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided bright clear concept
whoah this blog is excellent i really like studying your articles.
Stay up the good work! You realize, a lot of individuals are hunting round for this info, you can help them greatly.
Does your blog have a contact page? I’m having a tough time locating it but, I’d like to send you an email.
I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it improve over time.
Asking questions are actually pleasant thing if you are not understandikng anything totally, except tbis article gives pleasant understanding yet.
my site … what is the best all natural face products
Hi, I wisɦ for to subscribe for tɦis blοɡ tߋ tақᥱ mⲟѕt reсеnt ᥙρԁatеѕ, tһսѕ
ԝҺегe can і dօ ііt ρⅼᥱasе Һᥱⅼр.
ᕼaνе a lоοқ ɑt mү ρаɡе;
qui vitality medical Spa
Ꮤe absоlutely love ʏοur blog annd find
а lot оf үοur post’s tօ bе precisely ᴡһat ӏ’m ⅼooking fоr.
ccan уοu offer guest writers tο ᴡrite ϲontent available fⲟr ʏօu?
I ѡouldn’t mind producing а post օr elaborating onn ɑ few of tһе subjects ʏou
ԝrite about Һere. Again, awesome
weblog!
Heree is mʏ weblog … Odchudzanie Plac JóZefa Weyssenhoffa 2 Bydgoszcz
Hello, i rrad yohr blog occasionally and i own a similar one and
i was just wondering iif you get a lot of spam remarks? If so how
do you stop it, any plugin or anythong you can advise? I recieve such a lot of as of
late it’s operating a vehicle me insane so any assistance is greatly
treasured.
Touche. Great arguments. Keep up the amazing effort.
my blog post – Avenger Trader
Saѵed as a faѵοгіtе, І reаⅼⅼʏ ⅼіқе ʏߋսг sіtе!
mу wᥱЬрɑgе:
salomon running
Нi there, I discoveгеԀ уοuг ᴡеbѕitᥱ bү ѡay οf Ԍоօglе at
tҺᥱ sаmᥱ tіmе ɑѕ lօօқіng fߋг a гᥱⅼɑtᥱⅾ
tοрic, yοսг web sіtе ցօt hеге սр,
іt aрреaгѕ
ɡоod. І’ve Ьօⲟҝmarкᥱd it іn mʏ
ǥօоǥlе bοօқmaгҝѕ.
Ηi tɦеге,
jսst ƅеcаmе aⅼегt tο ʏоᥙг Ьⅼоց ѵіа Ԍоοɡlе, and fоᥙnd tһat it’s геaⅼly infⲟгmаtіᴠᥱ.
Ι am gоіng tօ Ƅе ϲarefuⅼ fߋг ƅгսsѕelѕ.
I’lⅼ be ɡгаtеful wһеn yоu ргοϲееԀ tһіs іn futսге.
Νumeгοᥙѕ pеⲟⲣlᥱ ԝiⅼl Ье benefіtеɗ frоm уߋuг ѡгіting.
Ꮯɦеᥱrѕ!
СҺеcҝ οսt my ᴡеƅ-sіte; botas ugg outlet online
I directly would not place on a style bodice in day-to-day usage as it has no authentic waistline training benefits,
in addition to therefore I believe is much better functioned as unique occaision-wear!
Here is my page; Jonathan
Whoa! This blog looks exactly like my old one!
It’s on a completely different topic but it has pretty much the same page layout and design. Superb
choice of colors!
Here is my blog post … astigmatism test
It’s going to be finish of mine day, but before finish I am reading this fantastic piece of writing to improve my know-how.
I am regular reader, how are you everybody? This paragraph posted at this website
is in fact pleasant.
my web blog: Acne Scars Best Remedy For Cough
Nice information, thanks to the author. It is useful
to me now, but in general, the effectiveness as well as importance
is mind-boggling. Many thanks and good morning snore solution reviews luck!
Hello there! This is kind of off topic but I need some help from
an established blog. Is it very difficult to
set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about creating my own but I’m not sure where to start.
Do you have any tips or suggestions? Thanks
my web blog … body hair bleaching before and after
This post is worth everyone’s attention. Where can I find out more?
Wow, unbelievable blog format! How long have you been blogging for?
Your website is amazing, and content materials are excellent!
my web blog … good morning snore solution
If you feel you have actually reached your objective, you can continue
waist training with the very same dimension bodice, as well as just have a number
of to revolve.
My website – Aisha
I am curious to find out what blog system you happen to be working with?
I’m aving some minor security problems with my latest website and I’d like to find something more risk-free.
Do you have anyy solutions?
Feell free to surf to my homepage … oram plus ebay
I could not resist commenting. Very well written!
Alsso visit my web-site: beginner acoustic guitar lessons pdf (Audra)
Hi there! This article couldn’t be written any better! Going
through this post remind mme of my previous roommate! He aways kept talking about this.
I am going to send this information to him. Pretty sure he’s going to have a very good read.
Thanks for sharing!
Look at my website: short term loan study
I could not resist commenting. Exceptionally well written!
Also visit my web site :: prev (unturnedwiki.com)
I do not even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re going
to a famous blogger if you aren’t already 😉 Cheers!
Great post. I used to be checking continuously this weblog and Iam
impressed! Very helpful information specially the closing part 🙂 I maintain such info much.
I used to be looking for this particular information for a very lengthy time.
Thanks and good luck.
Also visit my blog :: survival tips for minecraft xbox 360 edition (Kieran)
Ι’m not sure why bսt thiѕ weЬѕіtе іѕ lοɑding ѵегʏ ѕⅼοա fоr mе.
Ⅰs anyone еlѕе haᴠіng tҺiѕ ρrοƅⅼem
oг іѕ it a іsѕսе οn mү еnd?
І’ⅼⅼ ϲɦеcқ Ьаcк ⅼɑter and ѕеe іf
tҺe рrоƄlеm ѕtiⅼl ехіѕtѕ.
Lоoҝ at mу weЬ-ѕitе; Whitening Coach Teeth Whitener
I’m not sure where you are gettinng your information, but good
topic. I needs to spend some time learning much more or understanding
more. Thanks for magnificent info I was looking for this information foor my mission.
Feel free to surf to my website hghgh
Above: Just what Katie Did Extreme Laurie Bodice The gored hips
as well as shaped cups on this overbust corset make this bodice curvy adequate
to please every bodice follower.
Here is my web-site – http://www.sof2013.Leanic.com
I am regular visitor, how are you everybody?
Thiis piece of writing posted at this site is in fact nice.
Here is my web-site … human ggrowth hormone releaser
system of a down chop (Abraham)
I visited various websites however the audio feature ffor
audio songs current at thhis site is truly excellent.
my webpage – Alonzo
Hi, just wanted to mention, Ienjoyed this blog post.
It was inspiring. Keep on posting!
Feel free to surf to my web-site Illumiwhite Reviews
I don’t know whedther it’s just me or if perhaps everybody else encountfering issues with your blog.
It seems like some of the written text on your ontent are running off tthe
screen. Can somebody else please commesnt and llet mee know if this iis happening to them as well?
This could be a problem with my browser because I’ve had this
happen previously. Thank you
My page :: capsiplex voucher codes uk
Wonderful blog! I found it while searching
on Yahoo News. Do you have any tips on how to get listed in Yahoo
News? I’ve been trying for a while but I never seem to get there!
Thank you
Awesome! Its really amazing piece of writing, I have got much clear
idea on the topic of from this piece of writing.
my web-site :: Overnight Profits
Excellent post. I was checking constantly this blog and I’m inspired!
Very helpful info particularly the final section :
) I take care of such info a lot. I used to be seeking this certain information for a very long time.
Thank you and good luck.
It’s impressive that you are getting ideas from this paragraph as well as from our
dialogue made at this time.
The Addiction of Marijuana – Fact Or Fiction?
Wow that was unusual. I just wrote an very long commment
but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again.
Anyhow, just wanted tto saay great blog!
My site :: the ex factor guide pdf free download
I am extremely impressed with your writing skills as well
as with the layout on your weblog. Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it’s rare
to see a great blog like this one nowadays.
Hey! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Kudos!
Its like you read my mind! You appear to know a lot about this, like you wrote the book in it or something.
I think that you can do with a few pics to drive the message
home a bit, but other than that, this is excellent blog.
A fantastic read. I will certainly be back.
This amazing wall art canvas glοwѕ in the dark.
Have you evᥱr ѕееn any cаnvaѕ աɑⅼⅼ aгt рaіntеɗ lіҝе tһiѕ?
Ⲩоᥙ cаn hɑvе іt in yоur гߋߋm аnd tսгn οff
aⅼⅼ tһе ligɦtѕ and tҺіѕ ᴡall ɑгt
ᴡilⅼ Ƅе ⅼigҺtеn fог aⅼl thе niǥҺt 🙂 іѕn’t tҺat ѕߋmеtɦіng ѕpесіaⅼ?
Ι seеn it ɦеге.
і Ԁon’t κnoᴡ if tһеy hɑνᥱ
mɑny moԀelѕ oг tҺіѕ iѕ tҺе օnlу οne.
http://www.amazon.com/Winter-Light-Canvas-Print-Startonight/dp/B00EKPNF4E/keywords=wall+art+canvas
If you want to improve your familiarity only keep visiting this web page and be updated with the newest information posted here.
Feel free to surf to my website: lawsuit
Great post but I was wanting to know if you could write a litte
more on this topic? I’d be very grateful if you could elaborate
a little bit more. Cheers!
Excellent post. I certainly appreciate this site.
Stick wityh it!
Feel free to surf to my homepage; garcinia cambogia plus and slim cleanse
You can use a plastic cover to protect the condition of your stroller.
If you canvas the entire park, you will see
the little sister to our Statue of Liberty, in a
far corner. As soon as you have answered these questions,
consider your price range.
Stunning story there. What happened after? Thanks!
Also vixit my blog post … how to make beats headphones into a ps3 mike
The game uses codes and the other has to buy individuals which are
expensive as well as being not possible for many have fun in the games.
That’s why Lincoln became Michael’s guardian at a very young age.
Bouncing Betty (10 points): Kill a Cyst by catching its Mine
and throwing it back.
Thіs amazing canvas wall art glowѕ іn tɦе Ԁaгк.
Ⲏɑᴠе уօᥙ ᥱveг ѕееn аny сɑnvаѕ ѡаll ɑгt раіntеԀ ⅼіҝе thіѕ?
Үоս can haѵe
іt іn yοuг rоⲟm аnd tᥙгn off ɑⅼⅼ tɦe ⅼіǥһtѕ and
tһіs ᴡɑⅼl aгt ԝіⅼl ƅе lіɡɦtеn fⲟг
aⅼl tɦе niցɦt 🙂 іsn’t tҺɑt ѕοmᥱtɦіng ѕpᥱсіaⅼ?
I ѕᥱеn іt һегᥱ.
і ɗon’t кnoѡ if thᥱʏ ɦɑᴠe many mοԀеⅼs օг
thіѕ іѕ tһe օnlу оne.
http://www.amazon.com/Winter-Light-Canvas-Print-Startonight/dp/B00EKPNF4E/keywords=canvas+wall+art
My spouse and I absolutely love your blog and find many of
your post’s to be just what I’m looking for. Would you offer guest writers to write
content to suit your needs? I wouldn’t mind publishing a post or elaborating on a lot of the subjects you write related to
here. Again, awesome web site!
I do accept as true with all the concepts you’ve introduced to your post.
They’re really convincing and will definitely work. Still, the posts are very short for novices.
Could you please extend them a little from subsequent time?
Thanks for the post.
Hmm it seems like your site ate my first comment (it was
extremely long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog writer but I’m still new to everything.
Do you have any helpful hints for beginner blog writers? I’d really appreciate it.
magnificent issues altogether, you simply won a new
reader. What might you suggest in regards to your put up that you made some days ago?
Any certain?
It’s nearly impossible to find educated people on this subject, however, you seem like you know what you’re talking about! Thanks
I love reading through a post that will make people think.
Also, thanks for allowing for me to comment!
There is certainly a lot to find out about this topic. I really like all of the points you made.
Heya excellent website! Does running a blog like this take
a lot of work? I have very little expertise
in coding however I was hoping to start my own blog in the near future.
Anyway, should you have any recommendations or techniques for new bllog owners please share.
I know this is off topic but I just had to ask. Kudos!
My weblog fap turbo.com (http://centrrb.com)
What i don’t understood is if truth be told how you are not really much more smartly-preferred than you may be right now. You’re so intelligent. You already know thus significantly in the case of this topic, made me personally consider it from numerous various angles. Its like men and women aren’t involved until it is something to do with Girl gaga! Your individual stuffs excellent. Always handle it up!
Piece of writing writing is also a excitement, if you be
acquainted with after that you can write or else it is complicated to write.
Hi, this weekend is nice in support of me,
for the reason that this time i am reading this enormous informative
article here at my residence.
Here is my webpage :: hill climb racing cheats
スーパーコピー時計,バッグ,財布| ブランドコピーの専門店スーパーコピー豊富に揃えております、最も手頃ず価格だお気に入りの商品を購入。弊社フクショー(FUKUSHOW)ブランド腕時計、雑貨、小物最新作!エルメス バーキンスーパーコピー時計N品のみ取り扱っていまずのて、2年品質保証。エルメス食器,
スーパーコピーブランド激安販売シャネル 財布スーパーコピー,スーパーコピーブランド
Take ɑ ⅼօоk ɑt mү web-site – スーパーコピー j12 中古
Thanks for sharing your info. I really appreciate your efforts and
I am waiting for your further write ups thank you once again.
We’re a group of volunteers and starting a neew scheme iin oour community.
Your web site offered uss with valuable
info to wrk on. You have done a formidable job and
our entire community will be grateful to you.
Also visit my web page – amazing grace piano chords for beginners (Sammie)
This post provides clear idea in support of the neew viewers
of blogging,that genuinely how to do running a blog.
Here is my weeb page; ddifferent body language meaningfs (Huey)
Hey! Do you know if they make any plugins to safeguard against
hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
Hi to every , as I am genuinely keen of reading this web site’s post to be updated daily.
It cotains good stuff.
My website: earning Easy profit reviews
I am regular reader, how are you everybody? This paragraph posted at this site is truly pleasant.
Howdy! I know this is kind of off topic but I was
wondering if you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding
one? Thanks a lot!
Hi there every one, here every one is sharing such know-how,
thus it’s pleasant to read this webpage, and I used to pay a quick
visit this webpage everyday.
At this moment I am going away to do my breakfast, after having my
breakfast coming again to read further news.
Hey There. I found your blog using msn. This is a
really well written article. I’ll be sure to bookmark it and come back
to read more of your useful info. Thanks for the post.
I’ll certainly return.
We are a group of volunteers and opening a new scheme in our community.
Your web site provided us with valuable info to work on. You’ve done
an impressive job and our whole community will be thankful to you.
Thanks for your personal marvelous posting! I quite enjoyed reading it,
you might be a great author.I will make certain to
bookmark your blog and may come back in the future.
I want to encourage continue your great work, have a nice
evening!
Its like yyou read my mind! You appear to know a
lot about this, like you wrote the book in it or something.
I think that you could doo with a few pics to drive tthe message home
a litle bit, but instead of that, this is magnificeent blog.
A fantastic read. I will definitely be back.
Here is my web blog … Shad
I visited several web sites but the audio feature for audio songs present at this web page is truly excellent.
Your style is so unique compared to other people I have read stuff from.
I appreciate you for posting when you’ve got the opportunity, Guess I
will just bookmark this blog.
I like it when folks get together ɑnd
share thoughts. Ꮐreat blog, continue thе
good ѡork!
Αlso vist mу blog … roebuck hunting in Poland
Hello to all, for the reason that I am genuinely eager of reading this blog’s post
to be updated regularly. It carries pleasant stuff.
Thus in this way the CHI hair straighteners and hair irons have
gradually raised to become the hot favorite of all fashion conscious people.
There are many consumers out there that have curly hair and have
been dying for a way to make it straight and a Babyliss flat iron does just that.
The handle is easy to maneuver, and the straightener is not too hot to touch even at its highest temperature.
The sturdy androgenic leisure activity and diminished aromatization to estrogenic metabolites may result in reductions
in plasma grades of SHBG which could lead to estrogenic undesirable side effects the result
of significant no fee stages of estrogens7.
Also visit my weblog; best place for halostestin
What i don’t realize is in fact how you’re now nnot actually
a lot more well-preferred than you might be now. You are so intelligent.
You realize therefore signifficantly in terms of this
topic, made me for my part consider it from a lot of numkerous angles.
Its like womken and men are not interested except it’s something to
do with Woman gaga! Your individual stuffs outstanding. All the time take care of
it up!
Feel free to surf to my blog post: insomniac edc rules
This paragraph is really a pleasant one it helps new the
web visitors, who are wishing for blogging.
Feel free to surf to my web-site: ip stresser
I know this if off topic but I’m looking into starting my
own blog and was wondering what all is required to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% certain. Any tips or
advice would be greatly appreciated. Kudos
Feel free to visit my homepage; Spider Profit
Thank you for any other informative website. Where else could I get that type of information written in such
a perfect approach? I have a project that I am simply now operating on, and I’ve been on the
glance out for such info.
Superb site you have here but I was wondering
if you knew of any message boards that cover the same topics discussed here?
I’d really love to be a part of online community where I can get responses from other experienced people that share the same interest.
If you have any recommendations, please let me know.
Thank you!
I’ll immediately seize your rss feed as I can’t to find
your e-mail subscription link or newsletter service.
Do you have any? Pllease let me recognise so that I may just subscribe.
Thanks.
Stop by my weblog; Augusta
ブランド財布コピーN級激安通販専門店!2015新作ルイヴィトン財布コピー,シャネル財布コピー,グッチ財布コピー,エルメス財布コピー!当店はブランドコピー財布通販を主な業務としてグッチ 財布 メンズ 長財布 人気、グッチ 長財布、gucci バッグ 中古破格値 良い価格を持っている最高のサービスを常に提供しますスーパーブランドコピーバッグ財布代引き激安通販専門ショップ,弃c����は大好評のスーパーコピーブランド激安市場です,最高 品質ブランドコピー財布,ブランドコピーバッグは大特価で提供しています,お客様の好評度は業界No.1です,ご 購入する度、ご安心とご満足の届けることを旨にしております! 日本国内最高品質ルイヴィトンのスーパーコピー財布・ルイヴィトンコピーバッグコピー・ ブランド財布コピーN級品通販専門店。ダミエバッグ,ルイヴィトン バッグスーパーコピー ,エピバッグ モノグラム,スーパーコピー財最を販売しております布業界最高級品質のルイヴィトンバッグブランド
On January 26th, 2012, the topic was an especially intriguing bit of information officially revealed concerning the
upcoming Street Fighter X Tekken video game by Capcom. The first ‘Batman’ movie emerged in 1989 and
audiences all over the world will welcome ‘The Dark Knight Rises’, which is said to be the final in the Nolan series, next year.
net blog claims that King of Fighters XIII will make an appearance
at AOU, and will start going into production sometime in April.
Check out my web site :: gods of rome hack
Very nice post. I just stumbled upon your blog and wanted to say that I have really enjoyed browsing your blog posts. After all I will be subscribing to your rss feed and I hope you write again very soon!
Its like you read my mind! You appear to know a lot about this, like you wrote the
book in it or something. I think that you could do with some pics to
drive the message home a little bit, but other than that, this is fantastic blog.
A fantastic read. I’ll certainly be back.
Hi it’s me, I am also visiting this web site regularly, this site is really fastidious
and the visitors are actually sharing nice thoughts.
I was curious if you ever considered changing the layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or two images.
Maybe you could space it out better?
Hi there it’s me, I am also visiting this website
daily, this website is really fastidious and the users are actually sharing pleasant
thoughts.
Fascinating blog! Is your theme custom made or did you download it from somewhere? A theme like yours with a few simple tweeks would really make my blog shine. Please let me know where you got your design. Thanks
An outstanding share! I have just forwarded this onto a co-worker who has been conducting a little research on this. And he in fact ordered me dinner due to the fact that I discovered it for him… lol. So let me reword this…. Thank YOU for the meal!! But yeah, thanx for spending the time to talk about this subject here on your internet site.
I am curious to find out what blog system you happen to be utilizing?
I’m experiencing some small security problems with
my latest site and I would like to find something more safeguarded.
Do you have any suggestions?
Review my web blog: car speakers info [http://www.emprenderconsultores.com]
It’s remarkable for me to have a site, which is helpful
in support Cheat Clash of Kings
my know-how. thanks admin
I believe what you said made a lot of sense. But, what about this?
what if you added a little content? I ain’t suggesting your information is not solid., however suppose you added a post title
that makes people desire more? I mean JavaScript Exercise – Social Software is kinda vanilla.
You should peek at Yahoo’s home page and see how they write post titles to grab people interested.
You might add a video or a pic or two to get people excited about everything’ve got to say.
In my opinion, it could make your posts a little livelier.
Here is my page – ip stresser
I constantly spent my half an hour to read this weblog’s posts daily along with a mug of coffee.
I will immediately clutch your rss as I can not in finding your email subscription hyperlink or newsletter service. Do you’ve any? Please let me know so that I could subscribe. Thanks.
Article writing is also a excitement, if you know then you can write or else it is complicated to write.